さらに進化を遂げたInterSystems IRIS data platform Pythonのネイティブサポートが広げる可能性とは
2022年5月13日 6:30
はじめに
データ分析の重要性が高まる一方、データを取り扱う基盤はますます複雑化しています。そうした課題を解消するため、インターシステムズは企業・組織のデータ活用をよりシンプルにする統合データプラットフォーム「InterSystems IRIS」を提供してきました。そして、最新リリースの IRIS 2021.2では、世界で最も利用されている開発言語であるPythonを完全にネイティブサポート。PythonのランタイムをIRISのデータエンジンに組み込んだ「Embedded Python」により、データアナリストやシステム開発者にどのような利便性やメリットがもたらされるようになったのか。詳しく解説します。
テクノロジーの進化とともに
複雑さを増す一方のデータ分析環境
“ビッグデータ”や“データ駆動型経営”といったキーワードが語られて久しいですが、企業・組織におけるデータ活用の重要性はますます高まっており、機械学習/AIを用いた分析も盛んに行われるようになっています。そうした中、膨大なデータを取り扱うアプリケーションの開発や分析の現場においては、技術の進化とともに、さらなる変革が求められています。
これまでのデータ基盤の進化を振り返ると、組織横断によるデータ活用のためにデータウェアハウス(DWH)が構築され、ETLツールを用いたデータの抽出、変換、書き出しが行われてきました。もっとも、DWHは分析用の様々なデータを格納する入れ物ですから、直接ここで分析するには巨大すぎます。そこで、部門や目的等に応じて必要な情報だけを抽出し、分析するためにデータマートを用意するといったことが行われています(図1)。
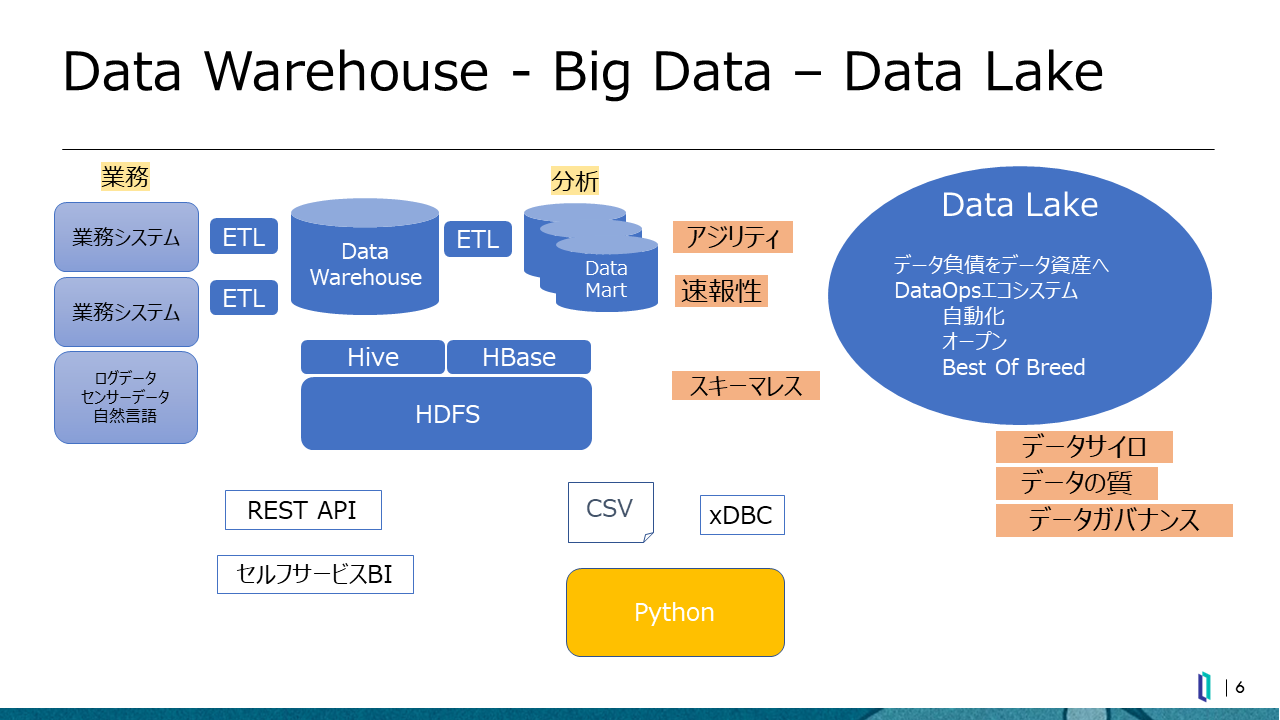
図1:RDBから発展したデータ基盤はニーズの多様化につれ複雑化を続けている
近年では、ログデータや、IoTデバイスから収集されるセンサーデータ等、従来のリレーショナルデータベース(RDB)では保存が困難なデータも分析対象として取り扱いたいというニーズが浮上してきました。そこで登場したのが、ビッグデータ技術のHadoopや、NoSQLといったテクノロジーです。Hadoopの分散ファイルシステムであるHDFSをベースに、NoSQL DBのHbaseや、Hadoop上でDWHを構築するための基盤ソフトウェアであるHive等の活用も行われています。加えて、構造化/非構造化を問わず多種多様なデータを取り扱えるよう、それらを一元的に保存するための基盤であるデータレイクの導入も拡大しています。
一方、データ活用の現場では、REST APIやセルフサービスBIを用いた分析や、Pythonを用いた機械学習によるデータ分析も盛んに行われるようになっています。とはいえ、CSV形式でのファイルダウンロードや、ODBCなどを用いたデータの取得・書き込み・操作等といった従来型の手法も、まだまだ一般的です。
このように、データ活用・分析のさらなる高度化に向けて様々な仕組みが実現されていますが、データの量や種類の増加、保管先の分散、利用ツールや言語の多様化により、データ分析の環境は複雑性を増しているのが実情ではないでしょうか。
特にデータサイエンティストやシステム開発者の方々の中には、「様々なデータソースにデータが分散して存在しており、分析用のデータセット作成に手間がかかる」「目的のデータを取り出すのに時間がかかる」「データを設計・管理するデータエンジニアと、データサイエンティストとの連携が困難になった」といった悩みを抱える人は多いと思われます。「もっとシンプルにデータを扱えるようになれば、もっと早く、もっと業務に役立つような分析が行えるのに」と考えるデータサイエンティストは少なくないでしょう。
データ分析のシンプル化を実現する
InterSystems IRIS データプラットフォーム
そのような課題を解消し、より効率的なデータ活用を、よりシンプルな仕組みで実現するものが、統合データプラットフォーム「InterSystems IRIS」データプラットフォーム(以下、IRIS)です(図2)。
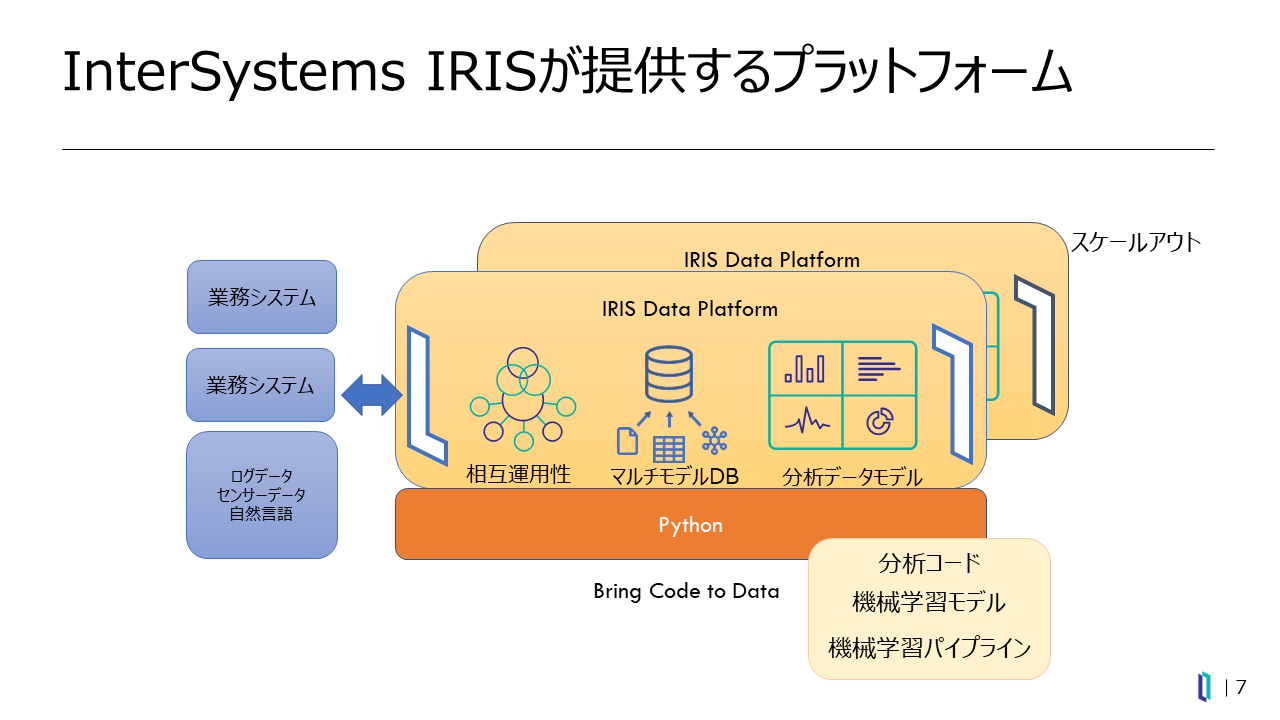
図2:InterSystems IRISの全体概要図
IRISの最大の特長は、マルチモデルデータベースへの完全なアクセスをサポートしていることです。リレーショナル、オブジェクト、ドキュメント、多次元データなどさまざまなデータに対応しているため、多種多様な形式のデータを煩雑な変換作業等を行うことなく取り扱うことが可能です。また、IRISは、ObjectScriptというプログラミング言語を内蔵しており、これは汎用スクリプト言語としての記述力をもつほか、PL/SQLやTransact-SQLと同様にストアドプロシージャの記述を可能としています(図3)。
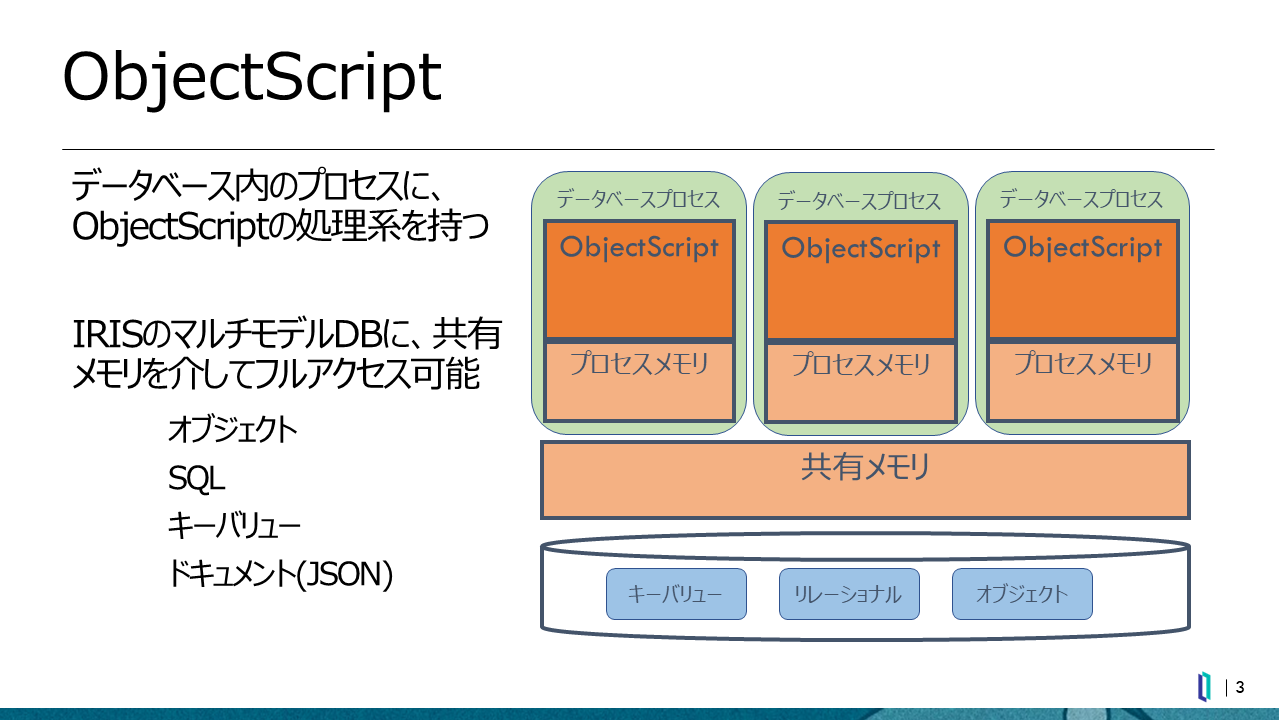
図3:ObjectScriptの仕組み
このほかにも、相互運用性機能によりデータとプロセスのサイロを解消、業務システムのデータ集約からクレンジング機能まで、一貫して整備されたデータ分析環境を提供します。さらに多彩なデータモデルを用いた分析機能も提供。これらの機能群により、1つのプラットフォームで、データ活用に関する様々な課題を解消することができます。
多彩なメリットをもたらす
Embedded Python
このような多彩な機能を持つIRISですが、最新リリースの IRIS 2021.2に追加された機能が「Embedded Pythonです。これは、既存のObjectScriptと同等のレベルで、IRISのデータベースプロセスにおいて、Pythonのランタイムを動作させられるというものです(図4)。
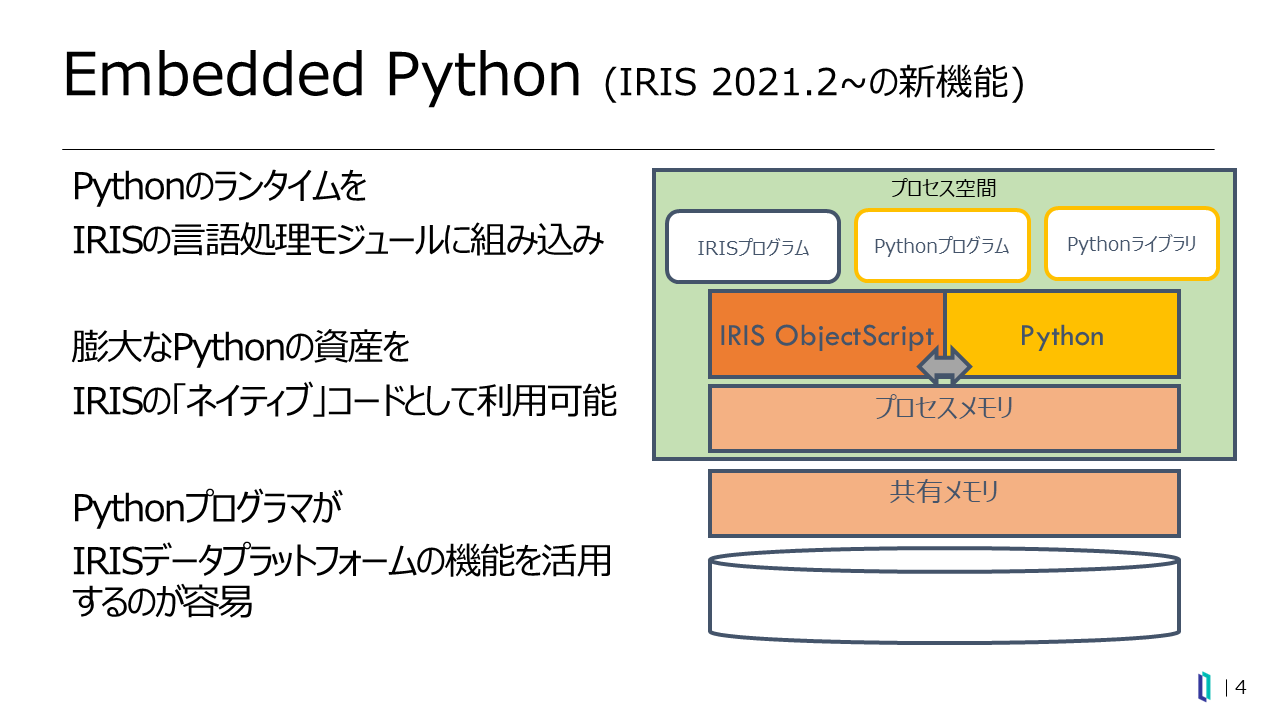
図4:Embedded Pythonの概要図
つまり、IRISのメソッドをPythonで記述したり、PythonのコードからIRISのクラスにアクセスしたりするなど、IRISのObjectScriptとPythonとの間での相互呼び出しが可能となりました。これにより、クライアントプログラムではなく、サーバー側の言語としてPythonがネイティブに動作できます。
具体的な動作イメージですが、図5に示すようにObjectScript側からPythonで定義されているクラスやモジュールにアクセスできるほか、ObjectScriptで書かれたIRISのクラス定義におけるメソッドをPythonで記述することも可能です。逆にPython側からObjectScriptで定義されているクラスを操作することもできます。
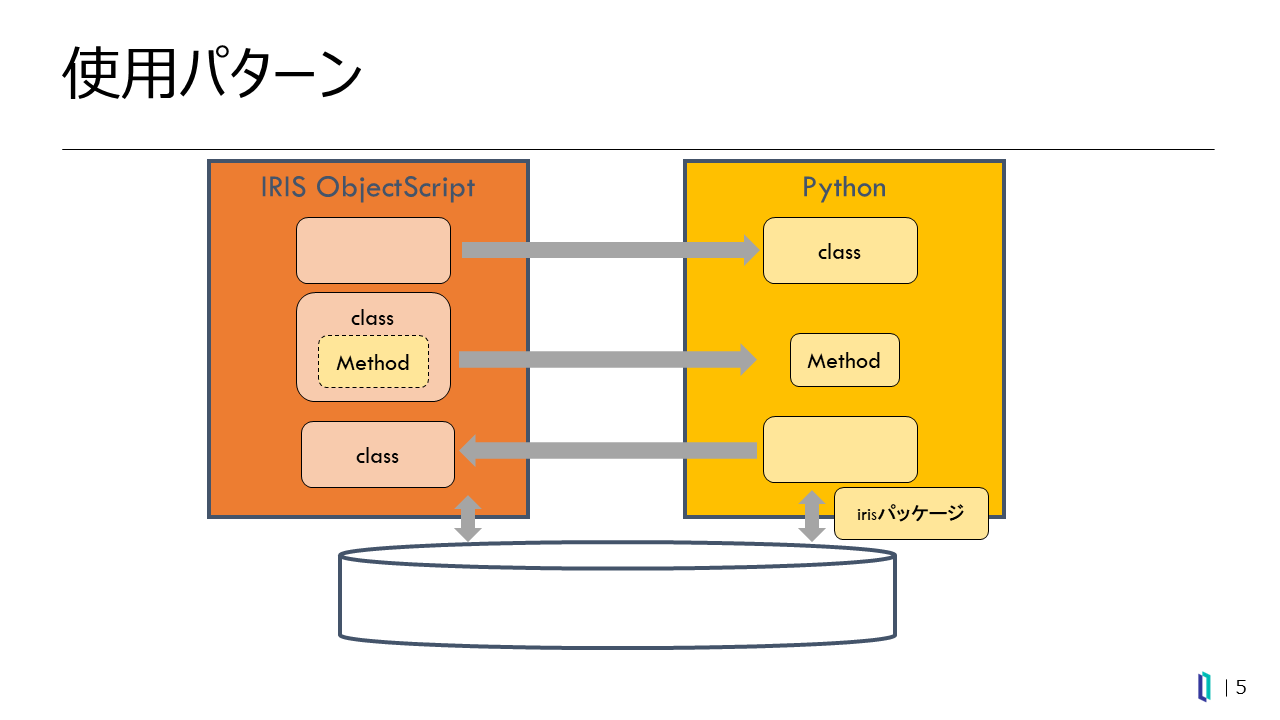
図5:IRISにおけるEmbedded Pythonの動作イメージ
Embedded Pythonは、様々なメリットをもたらします。1つは、Pythonのプログラマ―の方々が、IRISが提供する多彩なデータプラットフォーム機能を使い慣れた言語で利用できるようになったことです。ObjectScriptを学ばなくても、IRIS が活用できるわけです。これにより、Pythonで開発された機械学習モデルやAIを、IRISを用いてアプリケーションに直接組み込めるほか、IRISの相互接続性機能により様々なシステムのデータを統合、ここでRPAの仕組みを実装しデータの前処理やデプロイプロセスを自動化、一元化すれば、日々の開発、分析業務を大幅に効率化できるようになります。
取り扱うデータ量が増加の一途を辿る中、システム開発や分析に際して、都度、データレイクやDWH等からデータを抽出していたのでは、ネットワークを介してデータを移動させるコストや煩雑性は高まるばかりです。対して、近年“Bring Code to Data”という、よく語られるキーワードが示すように、データが存在する場所でコードを実行させるアプローチは、シンプルかつ効率的でアーキテクチャ的にも優れていると言えます。Embedded Pythonにより、IRISは、“Bring Code to Data”の実現をさらに一歩、推し進めることができました。
一方、IRISのプログラマ―やシステム管理者にとってのメリットは、Pythonの膨大なエコシステムを利用できるようになることです。既にあるPythonの豊富なライブラリが使えるようになれば、より効率的なシステム開発が行えるようになります。
また、最近では統計、機械学習を行なうためにPythonを学習するエンジニアが増えています。これまではIRISを利用したくとも、「ObjectScriptを学習しなければならない」「ObjectScriptを扱えるプログラマが少ない」といった課題が、導入障壁になっていたことは否めませんでした。しかし、Pythonを知っていればIRISを使ったプログラムも書けるので、開発者の確保や、人材の育成に関する負荷やコストを抑えながら、IRISがもたらす多彩なメリットを享受できるようになりました。
こんなに簡単に使える
Embedded Python
Embedded Pythonの利用ケースを、実際のコードに基づき紹介します。
1つが、Pythonでデータ分析をする人がよく使うJupyter Notebookを用い、IRISからデータを取得、分析を行なうというものです。ここでは、機械学習やデータサイエンスに携わる人々が集うコミュニティであるKaggleの「ワイン品質データセット」を用い、データの取得から分析を行うところまでの様子を実際のコードで示します。
import iris
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
from matplotlib import style
import seabornPythonの場合、利用するライブラリ最初に宣言しますが、ここでirisパッケージをインポートすれば、IRISへの接続が可能になります。また、pandasなどデータ分析用のPythonライブラリもインポートしています。
そしてデータを取得するための前処理については、既にIRIS側でObjectScriptにより何らかの業務ロジックが準備されていると仮定し、それらのモジュールをPython側から呼び出します。
# iris.cls().classmethod() でIRISで定義されたクラスのクラスメソッドを呼びます。
# User.SimpleDemo.getWorker()は、指定した名前のワーカクラスのインスタンスを生成し、返します。
irisworker = iris.cls('User.SimpleDemo').getWorker('User.MyWorker')
# ワーカのインスタンスのdoSomething()を呼び出します。
irisworker.doSomething('Pythonからこんにちは')そしてIRIS のSimpleDemoクラスのインスタンスを生成し、doSomethingというメソッドを実行させるという非常にシンプルなものとなっています。
以下は、ObjectScriptで定義されたSimpleDemoクラスの中身です。
Class User.SimpleDemo Extends %RegisteredObject
{
ClassMethod getWorker(name As %String) As %RegisteredObject
{
Set wk = $classmethod(name, "%New")
Quit wk
}
}Visual Studio Codeの画面で見て頂きますと、SimpleDemoというクラスがIRISデータプラットフォームに定義されており、WorkerのインスタンスをIRISの構文である“%New”を用い、生成して返しています。
Class User.MyWorker Extends %RegisteredObject
{
Method doSomething(s As %String) As %String
{
Quit "Received: "_s
}
}そしてWokerにはdoSomethingというメソッドがあるのが分かります。ここでは引数で渡されたメッセージに「Received:」をつけて表示しているだけですが、本来であれば何らかの業務ロジックを実装します。

再びJupyter Notebookに戻り、コードを実行します。IRIS側で定義された2つのクラスが連携し、それが、あたかもPythonのコードのように動いています。これはIRIS側で定義したクラスと、そのクラスのメソッドをPythonコードから呼び出すことで何らかの業務上の処理を行えることを示しています。
いよいよデータを取得しますが、ここでは単にSQLを実行するだけです。これにより、IRISに保存されているデータからワインの品質に影響する成分やアルコール濃度などのデータがすぐに取得できました。
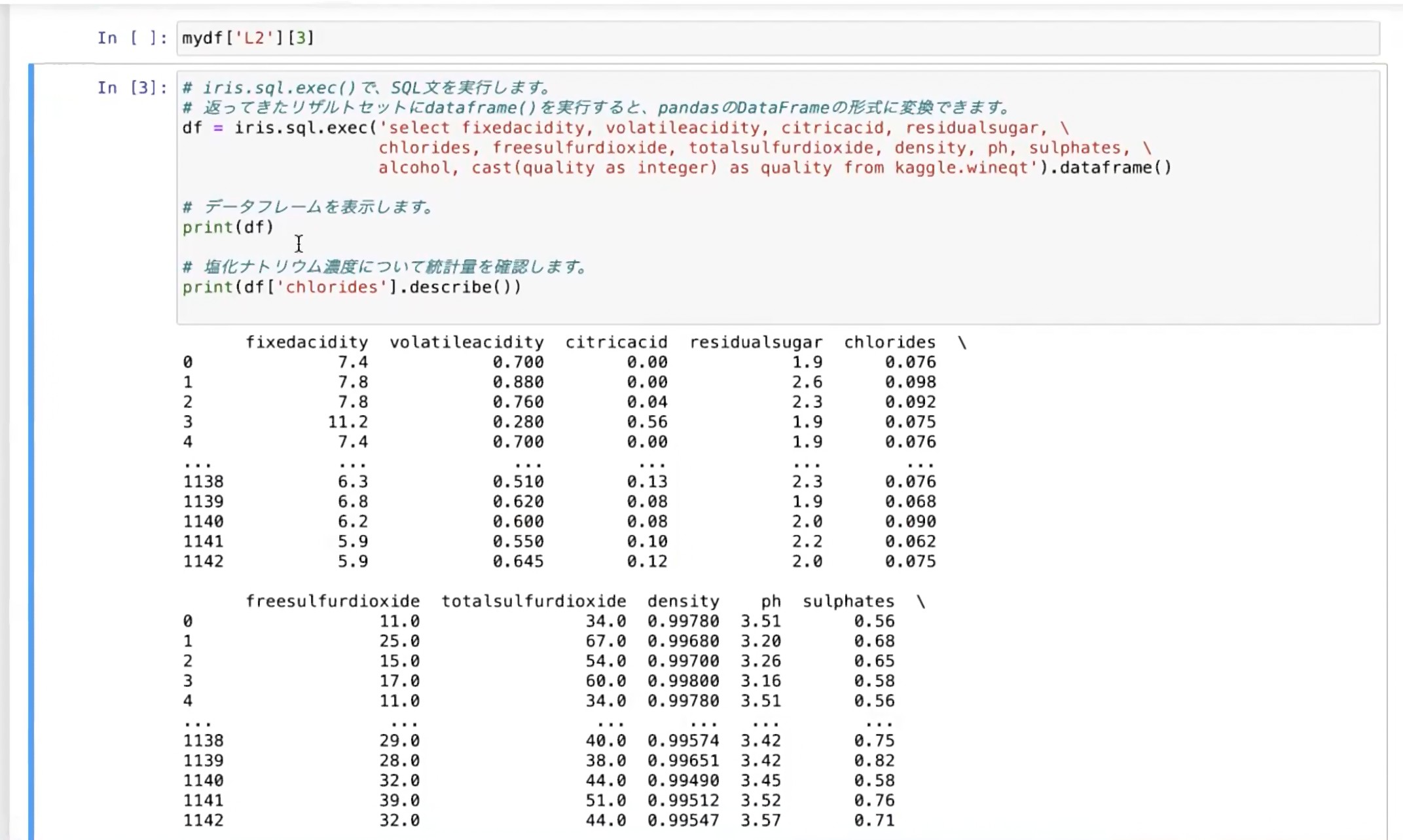
このように、IRIS上にある多種多様なデータをストレスなくNotebook側で取得できます。データを取得してデータフレームに入れてしまえば、あとは多彩なPythonライブラリを活用して自由に分析が行なえます。
また、データ変換や匿名化などの前処理IRISのObjectScriptで記述しておけば、分析用に加工されたデータをPython側からスムーズに読みこむこともできます。データ管理者(DBA)に依頼してデータセットを準備してもらったり、その待ち時間のせいで分析が思うように進まなかったりといったことを抑制できるわけです。
もう1つ具体例を示しましょう。次はObjectScriptの代わりにPythonでIRISの業務ロジックを記述するケースです。ここではGoogle Maps APIを用いて、2地点間の直線距離を計算するメソッドを例示します。Google Maps APIはREST APIでもアクセスできますが、Pythonでもgooglemapsというライブラリをインポートすれば、すぐに利用できます。
下のコードはIRISのクラス定義の中で、getDistanceというメソッドを定義している部分です。IRISの記法で出発点(origin)、到達点(destination)を文字列で渡してあります。ポイントは宣言の最後にある[ language = Python ]という記述で、これにより、Pythonを使ってプログラミングが行えるようになります。
ClassMethod getDistance(origin As %String, destination As %String) As %Integer [ Language = python ]
{
import googlemaps
import iris
# GoogleMapsのAPIキーをグローバルから読む
apikey = iris.gref('^APIKey').get()
# APIキーを用いてGoogle Mapクライアント生成
client = googlemaps.Client(apikey)
# 2点間の距離を求める
r = client.distance_matrix([origin], [destination])
distance = int(r['rows'][0]['elements'][0]['distance']['value'])
return distance
}なお、Google Maps APIを利用するにはAPIキーが必要ですが、ここではハードコーディングせずに、IRISのKey Value Storeに格納されているものをgetで取得しています。ちょっとしたサンプルプログラムでは、手間を惜しんでIDやパスワードをコードの中に埋め込みたくなってしまうものですが、IRISは変数を永続化するような感覚で手軽に使えますから、そうした悪しき風習を排除できます。
それでは定義したメソッドを実行してみましょう。ターミナルでIRISコンソールを開き、「東京駅」と「大阪駅」を指定してgetDistanceメソッドを呼び出すと、約501,251mという結果が表示されました。

このように、Embedded Pythonにより、Pythonの豊富なライブラリや、Googleや様々なネット上にあるサービスを活用したプログラムを、IRISのデータエンジン上で実行することが可能になりました。
データ分析においては、データアナリストの方々自らが社内外にある様々なデータを収集し、日々の分析を行っていると思われます。そうしたデータや、アナリスト個人のナレッジ/ノウハウが個人の環境に留まらず、全社的に利用可能なプラットフォーム上に集積され社内に共有されるのであれば、よりデータ分析の効率化、高度化が促進し、ひいてはデータ駆動型企業に近づくことができます。このような仕組みを実現するものがIRISなのです。
また、システム開発においても、Embedded PythonでPythonのエコシステムを活用可能になったIRISは、大きな生産性向上をもたらすと期待できます。
インターシステムズでは、開発者・技術者の方々向けに無償の「IRIS Community Edition」を提供しています。Community Editionは同時接続数などに制限があるものの、機能的な制限は一切なくIRISのすべての機能が利用できます。この記事でIRISに興味をお持ちの方は、ぜひダウンロードして、その有用性をお試しいただければと思います。
●InterSystems IRIS Community Edition
https://download.intersystems.com/download/register.csp?lang=jp
また、2020年7月より、開発者が自由闊達なやり取りを行える日本語によるコミュニティサイトの運営も開始しています。開発者の皆様同士の交流の場として、技術的な質問とその回答を書き込めます。また、海外サイトの翻訳や日本語オリジナルの役立つ記事もございます。セルフラーニング用のビデオも用意していますので、ぜひ皆様のご参加もお待ちしております。
●インターシステムズ開発者コミュニティ
https://jp.community.intersystems.com/
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
