はじめに
企業におけるITシステムは、業界を問わずクラウド環境への移行が進んでいます。近年、クラウドネイティブ、クラウドファーストという標語を掲げて、戦略的にITシステムのクラウド化を進めている企業も多くなっています。
そのような企業では、AIのみに関わらず、社内業務のRPA化、社内システムのクラウド化などを、攻めのIT戦略としてデジタルトランスフォーメーション(DX)の一環として取り組んでいます。
業務の目線では、単純かつ繰り返しの日常業務をRPAに置き換え、システム的な目線では、ハードウェア、ソフトウェア、アプリケーションをクラウド上のIaaS、SaaSなどへ移管し、業務における生産性を向上させ、システム管理に関わる工数を低減することが、近年のDXを成功に導き、企業の競争力を高める1つのサクセスファクターではないかと考えます。
このように、RPAの促進とクラウドの活用を両輪で進めた場合、RPAとクラウドの関係はどのようなものとすべきなのでしょうか。
現在、RPAに取り組まれている方々においては、RPA開発でクラウドはどのように活用できるのか、またどのように利用すべきかて、各々の取り巻く環境や制約の中で様々なことにチャレンジし、最適解を模索されているのではないでしょうか。
実際に、UiPathへはクラウドに関して「クラウド環境にUiPathのサーバー製品であるOrchestratorを構築したい」「UiPath Robotをクラウド環境で運用したい」といった問い合わせを数多くいただきます。インフラの運用という観点でOrchestratorやRobotをクラウド環境で運用することは、初期構築や運用監視においてクラウド特有の恩恵が得られ、これはまさにDXの活動の一環と言えます。
しかし、それだけがRPAとクラウドの活用法の全てではないと考えます。クラウドのエコシステムやクラウド内に点在するマイクロサービスと連携し、業務の自動化をより高度化・安定化させることにも、RPAとクラウドの連携は大きな恩恵を与えてくれるはずです。今回は、この点において2つのインテグレーション事例を通して理解を深めていきます。
今回の対象読者
今回は、以下のような方を読者対象としています。
- クラウド環境を利用中、または、検討中でRPAとの連携を模索されている方
- プログラム経験がある方 (UiPath StudioでVB.NET、クラウド環境でPythonを使用したものを紹介)
また、前提事項として、以下のクラウドサービスを使用します。実践にあたっては、それぞれのアカウントが必要となります。
- Amazon Web Service
- Google Cloud Platform
今回行うこと
今回は2つのケースを取り上げます。1つはAmazon Web Service(AWS)で提供されているストレージサービス、サーバーレスアーキテクチャを用いたファンクションのマネージドサービスとのRPA連携を構築していきます。これは、第1回「RPAでの大量データ自動化処理の実践開発」で紹介したOrchestratorのキューの作成をクラウドで代替するものです。
AWSのストレージサービスであるS3、サーバーレスアーキテクチャーでのアプリケーション開発が可能なLambdaを使用します。CSVファイルがS3へアップロードされたことをトリガーとして、Lambda関数でそのCSVファイルを読み取り、Orchestratorのキュー作成までを一気通貫で行います。
もう1つは、RPAからGoogle Cloud Platform(GCP)の画像認識AIサービスであるVision APIを取り扱います。前回は、自身でPythonを使用して機械学習のトレーニングから予測までを実装しましたが、今回はGCPで予めトレーニングされたAIを、そのREST APIのインターフェイスを通して利用します。
なお、UiPath GO!では、現在「Google Vision」というアクティビティパッケージにて、Vision APIの呼び出しを実行するアクティビティを提供しておりますが、API連携のRPA開発の汎用的な手法、やり方を学習するという意味で今回はこちらを使わず、UiPath Studioの機能のみで実装をしていきます。
なお、この他にもMicrosoft AzureからFace APIという顔認証専用のAPIが公開されています。UiPath GO!では、このAPIに対応した「Microsoft Facial Recognition」というアクティビティパッケージも公開されています。必要に応じて、ぜひご利用ください。
●UiPath GO!
https://go.uipath.com/ja/
AWS LambdaとOrchestratorの連携
RPAを用いて、外部システムで生成されたトランザクションをUIを自動化して別システムへデータ投入するといった場合、UiPathでの最善のアーキテクチャーは外部システムから直接Orchestratorにトランザクションをキューとして登録し、Robotがそれを処理していくモデルとなります。
しかし、現実の世界では、予算の都合や外部システムの都合などにより、それを実現することが難しいケースは多々あります。その場合、外部システムとRPAの中間地点をS3とすることで、S3でファイルを中継してシステム連携することが可能となります。かつ、S3へのファイル投入をイベントトリガーとして後続処理を動かすことにより、シームレスな連携が実現します。
この場合のフローは、S3の特定のバケットへのファイルアップロードをイベントトリガーとして、LamdbaでOrchestratorへキューを登録する、です。S3のバケットへのファイル登録は外部システムからでも、PCからKinesis経由でも良いですし、人が手動で行うケースのいずれも可能です。
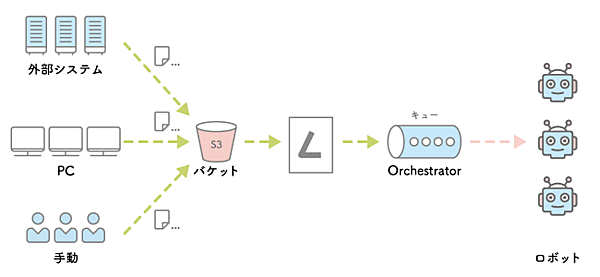
AWS S3のバケットは、アドレスを持ったバケツのような概念です。冗長性があり、標準ストレージ機能においても高品質のSLAが保証されています。
●Amazon S3 でのデータ保護
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/DataDurability.html
また、AWS Lambdaも冗長性だけでなく、スケーラビリティもクラウド側で管理されます。従って、S3、Lambda双方ともに冗長性、スケーラビリティなどは全てクラウド側でマネージ(管理)されます。クラウドのマネージドサービスを利用することで、開発工数を抑えながら冗長性、スケーラビリティなどのクラウドの恩恵が得られるようになります。
仮に、大規模なアプリケーションをサーバレスのアーキテクチャーで構築しようとした場合、色々な困難に直面することは大いに考えられますが、今回のケースのような単純な使用方法では気軽に開発でき、かつ運用においての安定性も享受されるというRPAとクラウドで双方がWin-Winの関係になります。
S3でのバケット作成
まず、CSVデータを受領するため、AWS S3にバケットを作成します。自身のAWSのWebコンソールへログインし、S3のメニューへアクセスします。過去にS3を利用したことがない場合は次のような画面となります。
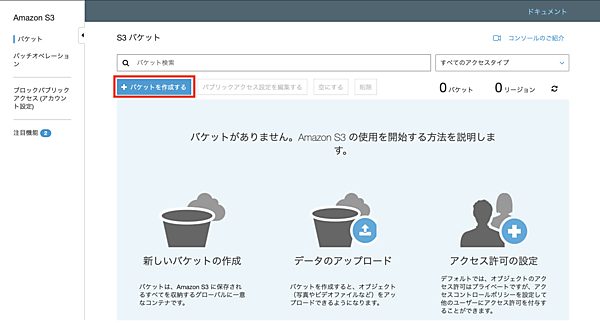
それでは、バケットを作成していきましょう。「バケットを作成」ボタンから次の画面に遷移し、必要な情報を入れていきます。バケット名は「thinkit-test」としました。こちらは全世界(全てのAWSリージョン)においてユニークである必要があるので、実際に試す際は別の名称を使用する必要があります。なお、既に存在する名称の場合、エラーとして画面に通知されます。また、リージョンは「アジアパシフィック(東京)」とします。
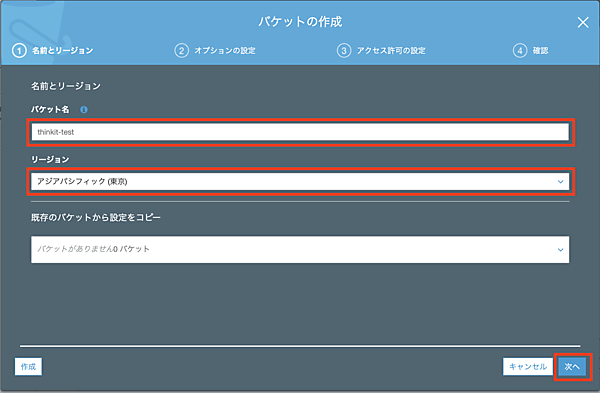
次の画面では、デフォルトのまま「次へ」へ進みます。
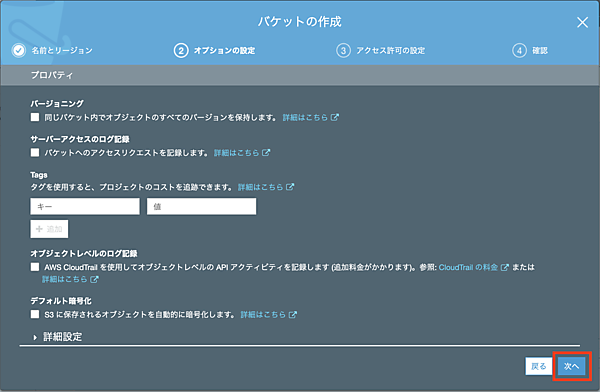
こちらもそのまま「次へ」へ進みます。パブリックアクセスはインターネット公開などをしない場合は「パブリックアクセスをすべてブロック」にチェックを入れたままにします。これにより、意図しないファイルの外部漏洩を抑止します。
最後に確認画面が表示されます。内容に問題がないことを確認の上、「バケットを作成」へ進んでバケットが作成されるのを待ちます。
しばらくすると、画面上に「thinkit-test」というバケットが作成されます。
ひとまず、このバケットに第1回の「RPAでの大量データ自動化処理の実践開発」で使用したCSVファイル「test-data.csv」をアップロードします。
以上で、S3にCSVを保存するためのバケットが作成できました。
Lambdaでの関数作成
続いて、Lambdaで関数を作成します。再度、AWSのマネージメントコンソールからLambdaのメニューへアクセスします。LambdaもS3と同様に、未使用の場合は次のようなメニューとなっています。さっそく、「関数の作成」のリンクから関数を作成していきましょう。
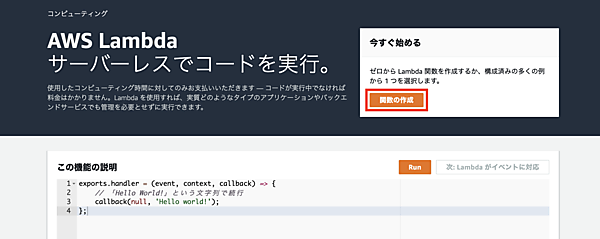
関数を作成するには「一から作成」「設計図の使用」「Serverless Application Repositoryの参照」のいずれかを選択する必要があります。
「設計図の使用」を選択しs3というキーワードでフィルタをかけると、python3.7、python2.7、nodejsの3つの雛形がフィルタリングされました。今回は、Python3.7でS3のデータ取得をする雛形を使用します。フィルタリング結果の「s3-get-object-python」を選択した状態で「設定」ボタンを押します。現在、LambdadではJava、Go、PowerShell、Node.js、C#、Python、Rubyの各言語が使用できます。
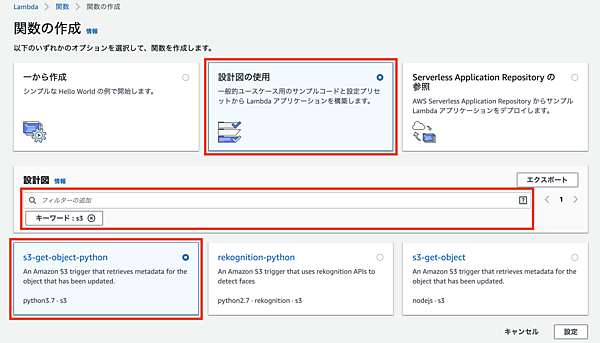
関数名に適当な名称(ここでは「s3-to-orchestrator」)を入力し、実行ロールに「AWSポリシーテンプレートから新しいロールを作成」を選択します。ロール名は「s3-to-orchestrator」、ポリシーテンプレートは「Amazon S3オブジェクトの読み取り専用アクセス権限」が選択された状態にします。このポリシーによりLambdaからS3のデータ取得が可能となります。
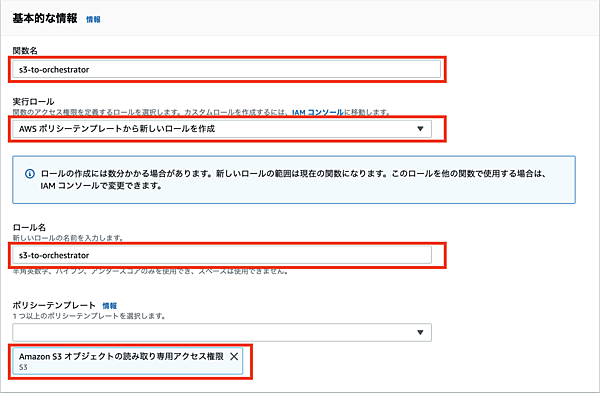
続いてS3トリガーの設定へ移り、バケットに作成済みの「thinkit-test」を、イベントタイプに「すべてのオブジェクト作成イベント」を選択します。プレフィックス(接頭辞)はブランクとしますが、S3のバケットでディレクトリを作成し、その中のファイルのみを対象とする場合などに指定します。サフィックス(接尾辞)には「csv」を指定します。トリガーの有効化に関しては、しばらくテストを行うためチェックなしのままとします。
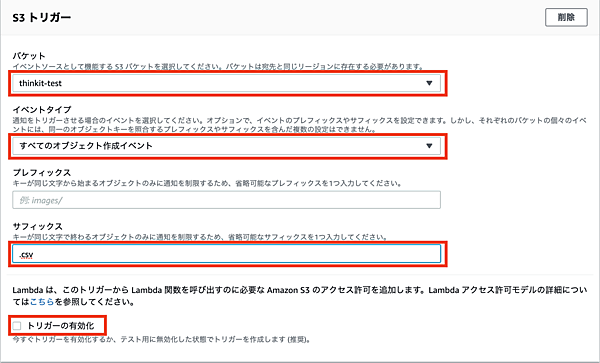
Lambda関数のコードは、一旦デフォルトのままで「関数の作成」ボタンを押します。
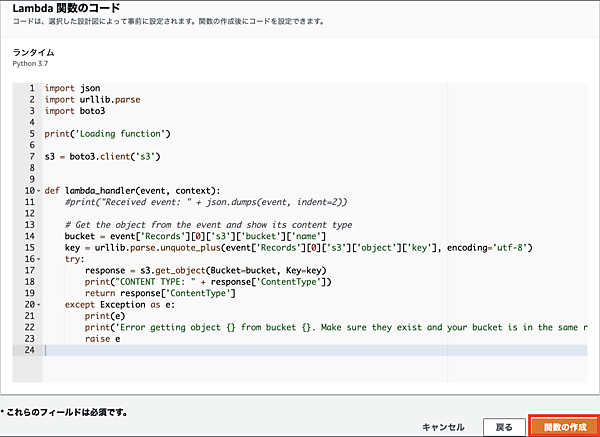
関数の作成にはしばらく時間を要しますが、関数が作成されると次のような画面となります。DesignerのパネルにはS3がトリガーとして存在し、s3-to-orchestratorと命名したLambda関数に紐付けられています。その下の関数コードのパネルでは、Python3.7でLambda関数を画面上から編集できます。デフォルトではS3からデータを取得するコードが記載されています。
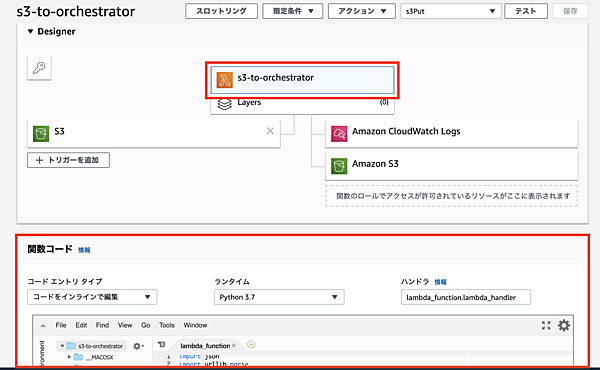
この関数コードのエディタ上で、S3へのCSVアップロードをトリガーとして、Lambda関数でそのCSVを読み取り、Orchestratorへキューを作成するコードへとPythonのコードを編集していきます。
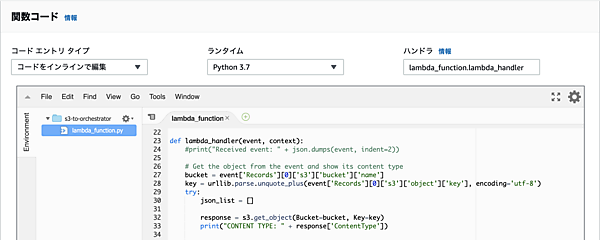
編集画面では「lambda_function.py」が開かれている状態です。「ハンドラ」を見ると、デフォルトでlambda_function.lambda_handlerという記載が存在します。これは、トリガーイベントの発動時に「lambda_function.py」ファイル内のlambda_handlerが実行されることを意味します。
まず、CSVファイルを取得するためのS3のバケットへのアクセスはboto3というPythonのライブラリがデフォルトでLambda側にインポートされており、使用できる状態となっています。Lambdaの具体的なコードは次のようになります。
import json
import urllib.parse
import boto3
import csv
import urllib.request
BASE_URL = 'https://orchestrator.xxx.local' # OrchestratorのURL
QUEUE_NAME = 'MyQueue' # キュー名
OC_TENANT = 'default' # テナント名
OC_USER = '<user>' # Orchestratorのユーザー名
OC_PASSWORD = '<password>' # Orchestratorのパスワード
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
print('Loading function')
s3 = boto3.client('s3')
def lambda_handler(event, context):
#print("Received event: " + json.dumps(event, indent=2))
# Get the object from the event and show its content type
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
json_list = []
response = s3.get_object(Bucket=bucket, Key=key)
print("CONTENT TYPE: " + response['ContentType'])
lines = response['Body'].read().decode('utf-8').split()
for line in csv.DictReader(lines, delimiter=',', quotechar='"'):
json_list.append(line)
bear = auth_with_oc()
for json in json_list:
logger.info("generate queue: " + str(json))
add_queue(bear, json['no'], json['title'], json['type'], json['amount'], json['desc'])
return response['ContentType']
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
def auth_with_oc():
headers = {'Content-Type': 'application/json'}
endpoint = BASE_URL + "/api/account/authenticate"
bear = None
body = {
'tenancyName': OC_TENANT,
'usernameOrEmailAddress': OC_USER,
'password': OC_PASSWORD
}
req = urllib.request.Request(endpoint, json.dumps(body, ensure_ascii=False).encode('utf-8'), method='POST', headers=headers)
with urllib.request.urlopen(req) as res:
res_body = res.read().decode("unicode-escape")
json_res = json.loads(res_body)
bear = json_res["result"]
return bear
def add_queue(bear, csv_id, title, exp_type, amount, desc):
headers = {'Authorization': 'Bearer ' + bear, 'Content-Type': 'application/json'}
endpoint = BASE_URL + "/odata/Queues/UiPathODataSvc.AddQueueItem"
body={
"itemData": {
"Name": QUEUE_NAME,
# "Priority": "High",
"SpecificContent": {
"title@odata.type": "#String",
"title": title,
"type@odata.type": "#String",
"type": exp_type,
"amount@odata.type": "#Integer",
"amount": amount,
"desc@odata.type": "#String",
"desc": desc
},
"Reference": csv_id
}
}
req = urllib.request.Request(endpoint, json.dumps(body, ensure_ascii=False).encode('utf-8'), method='POST', headers=headers)
with urllib.request.urlopen(req) as res:
logger.info(res.read().decode("unicode-escape"))
順番に説明していきます。冒頭に、追記に必要となるライブラリ(Lambdaから追加なしで参照可能なもの)でOrchestratorへキューを登録するOrchestratorのREST APIを簡易に呼ぶためのurllib.requestライブラリを追加でインポートします(併せてCSV用のライブラリもインポートします)。その他に、Orchestratorとの接続情報やログ用のオブジェクトといった必要事項を記載しています。
import csv
import urllib.request
BASE_URL = 'https://orchestrator.xxx.local' # OrchestratorのURL
QUEUE_NAME = 'MyQueue' # キー名
OC_TENANT = 'default' # テナント名
OC_USER = '<user>' # Orchestratorのユーザー名
OC_PASSWORD = '<password>' # Orchestratorのパスワード
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
次に、トリガーイベントの発動時に実行されるlambda_handler(event, context)メソッドでbucket及びkey(S3上のファイルパス)を取得するためのコードがデフォルトで生成されています。このコードはlambda_handler(event, context)メソッドの引数であるeventよりbucket及びkeyを取得しているものです。
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
CSVファイルをJSONフォーマットで各行を保存するためのjson_listを用意し、s3.get_object(Bucket=bucket, Key=key)というメソッドでS3よりCSVファイルを取得します。S3はバケットの情報と、そのファイルパスを示すKeyの情報で対象のファイルへアクセスできます。
CSVファイルは、responseというDictionary型の変数のBodyに格納されており、これをUTF-8の日本語も正常に読み取れるようデコードして、CSVをDictReaderメソッドにて解析していきます。各行は、lineという変数でforループの中でJSONフォーマットとして取得され、リストであるjson_listへ格納しておきます。
json_list = []
response = s3.get_object(Bucket=bucket, Key=key)
print("CONTENT TYPE: " + response['ContentType'])
lines = response['Body'].read().decode('utf-8').split()
for line in csv.DictReader(lines, delimiter=',', quotechar='"'):
json_list.append(line)
次に、Orchestratorとの認証を行います。Orchestrator APIの仕様については「UiPath Orchestrator APIガイド」が参考になります。
bear = auth_with_oc()下記の自作のメソッドを呼び出し、Bearトークンのみを返すメソッドとします。処理としては、requestsライブラリより/api/account/authenticateのエンドポイントへREST APIを呼び出し認証を行います。正しく認証できた場合はそのレスポンスに含まれたBearトークンのみを取り出します。
def auth_with_oc():
headers = {'Content-Type': 'application/json'}
endpoint = BASE_URL + "/api/account/authenticate"
bear = None
body = {
'tenancyName': OC_TENANT,
'usernameOrEmailAddress': OC_USER,
'password': OC_PASSWORD
}
req = urllib.request.Request(endpoint, json.dumps(body, ensure_ascii=False).encode('utf-8'), method='POST', headers=headers)
with urllib.request.urlopen(req) as res:
res_body = res.read().decode("unicode-escape")
logger.info(res_body)
json_res = json.loads(res_body)
bear = json_res["result"]
return bear
キューの登録についても、同様にメソッドadd_queue(bear, csv_id, title, exp_type, amount, desc)を用意し、その中で/odata/Queues/UiPathODataSvc.AddQueueItemのエンドポイントを呼び出します。
def add_queue(bear, csv_id, title, exp_type, amount, desc):
headers = {'Authorization': 'Bearer ' + bear, 'Content-Type': 'application/json'}
endpoint = BASE_URL + "/odata/Queues/UiPathODataSvc.AddQueueItem"
body={
"itemData": {
"Name": QUEUE_NAME,
# "Priority": "High",
"SpecificContent": {
"title@odata.type": "#String",
"title": title,
"type@odata.type": "#String",
"type": exp_type,
"amount@odata.type": "#Integer",
"amount": amount,
"desc@odata.type": "#String",
"desc": desc
},
"Reference": csv_id
}
}
req = urllib.request.Request(endpoint, json.dumps(body, ensure_ascii=False).encode('utf-8'), method='POST', headers=headers)
with urllib.request.urlopen(req) as res:
logger.info(res.read().decode("unicode-escape"))
呼び出す際にはlambda_handlerメソッドでCSVファイルを解析して作成したjson_listのリストを1件ごとに処理していくものとします。forループでjson変数に格納された各要素no、title、type、amount、descの値をbearと共にadd_queueuメソッドの引数へと渡します。
for json in json_list:
logger.info("generate queue: " + str(json))
add_queueu(bear, json['no'], json['title'], json['type'], json['amount'], json['desc'])
これで、一連の実装が完成しました。
Lambda関数のテスト
それでは、期待通りに関数が動作するかテストしてみます。Lambdaにはテスト用の仕組みも備わっており、「テストイベントの設定」からテストイベントを作成していきます。イベントテンプレートには「Amazon S3 Put」を指定して、いくつかの項目を変更します。
| 名前 | 変更後の値 |
|---|---|
| buket name | thinkit-test |
| arn | arn:aws:s3:::thinkit-test |
| object key | test-data.csv |
事前にS3へアップロードした「test-data.csv」を使用したテストイベントとします。全て変更したら、イベント名を「s3Put」として「作成」ボタンを押せば準備は完了です。
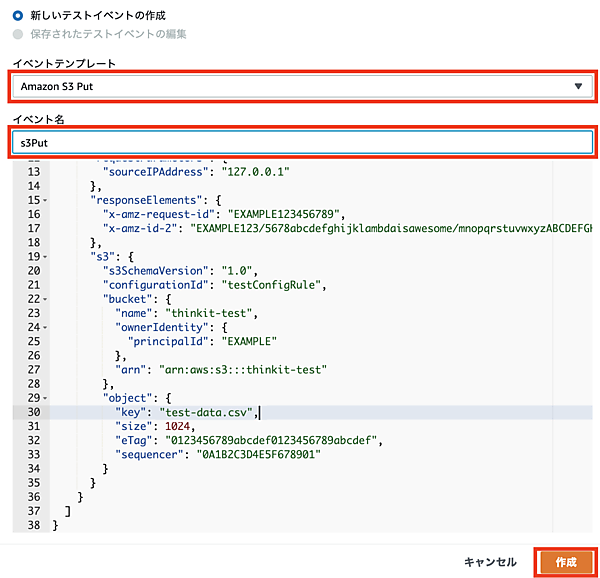
プルダウンから「s3Put」を選択した状態で、「テスト」ボタンを押します。
テストが実行されると「test-data.csv」がトリガーとしてLambda関数に渡され、このファイルを使用して関数のテストが実行されます。正常にテストが終了した場合は「実行結果: 成功」と表示されます。
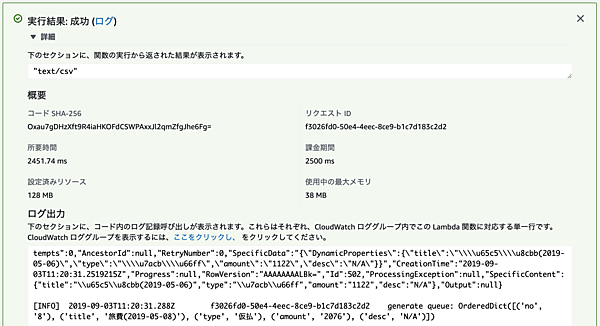
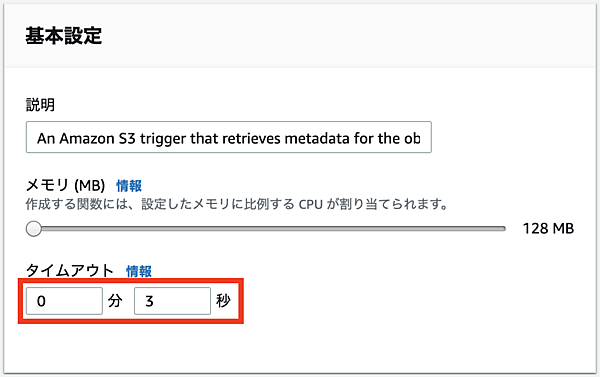
テストがエラーになった場合は原因が表示されるので、それを元に関数を修正します。Lambdaのデフォルトの関数実行時のタイムアウトは3秒なので、Orchestratorとの接続に時間がかかる場合などは予めタイムアウト値を長めに設定しておきます。
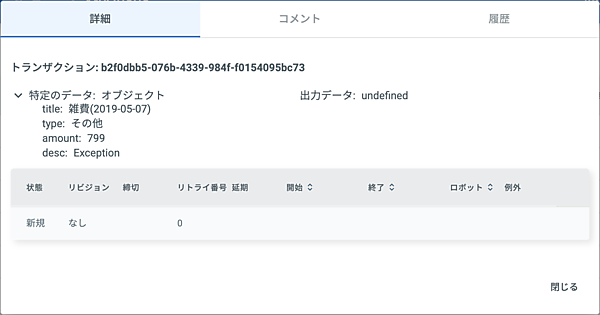
Orchestratorのコンソール画面で「MyQueue」のキューにLambda関数のテストから登録したデータが正しく反映されているかを確認します。
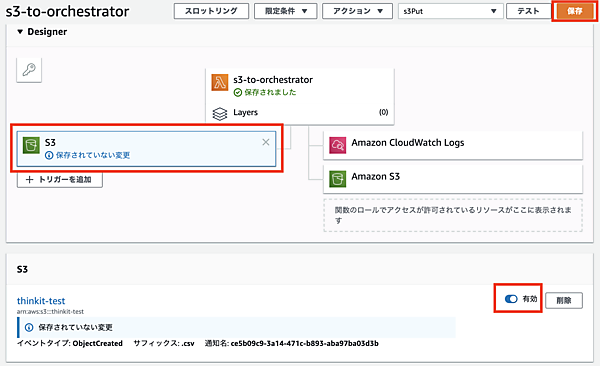
Lambda関数の運用開始
運用開始に伴い、無効にしておいたトリガーの設定を変更します。Designerのパネルでイベントの「S3」を選択するとS3のパネルが表示されるので、無効のチェックをクリックして有効へ変更します。最後に「保存」ボタンで設定を保存します。
以降では、S3へのファイルアップロードをトリガーとしてこの関数が自動で実装され、Orchestratorには都度キューが生成されるようになります。
Lambda関数に関して
今回は詳細に説明しませんでしたが、Lambdaのレスポンスとして、デフォルトのresponse['ContentType']をそのまま利用しています。これは後続のサービスへ処理の最終結果を渡したいといった場合に、Json形式などで独自のものを引き渡すことに利用できます。
また、あえて標準で使用可能なライブラリのみを用いて関数を作成しましたが、追加でライブラリを使いたい場合は一旦開発中のスクリプト全てをローカルへエクスポートします。そしてpip install <library name> -t ./とpipコマンドで、そのディレクトリ配下にライブラリを追加します。その状態で全てをzipで圧縮し、再度Lambdaのコンソールへアップロードすることで好みのライブラリが追加可能となります。関数の開発自体もAWS SDKを使えばローカルで可能となります。その他にも、Lambda関数の開発手法としてサーバーレス専用のServerless FrameworkやAWS SAMといった開発用のフレームワークもあり、開発、テスト、デプロイまでがサポートされています。
トリガーもS3だけでなく、API Gatewayを使用したREST API経由、Alex Skillを使用した音声認識経由でも利用できます。ログも今回は省略しましたが、CloudWatchというLogサービスに保存されています。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
