はじめに
人工知能(Artificial Intelligence)、機械学習(Machine Learning)、深層学習(Deep Learning)といったワードが世間で騒がれており、この言葉を聞かない日はないほどです。2045年にはAIは人間の知能を超えるシンギュラリティ(技術的特異点)に到達するといった予測もされています。この分野への研究投資も活発に行われており、様々な活用方法が続々と出てきています。
自動車の自動運転には大企業が莫大な資金を研究開発に投資していますし、農家の方が機械学習を利用してきゅうりの出荷用選別機を製作しYouTubeで話題になるなど、一昔前までは考えられなかったことが既にいくつも実用化されています。スパムメールの検知やオンラインショッピングでのオススメ商品の提示など、既に我々が恩恵を受けているものも多数あります。
日々RPAに携わり、業務の自動化や効率化に取り組まれている方々においても、RPAとAIを組み合わせることでRPAだけでは出来なかったことが、AIを利用することで自動化の対象範囲が広がるのではないか、自動化のバリューがより有用なものとなるのではないかと期待されている方も多いと思います。今回は、我々のオフィスでの業務において、RPAとAIをどのように連携させれば良いのか、またどのような業務に適用できるのかを紹介します。
なお、今回はGoogle、Amazon、Microsoftといった大手クラウドベンダーやAIのサービスは使用しません。AIのモデル作成からRPAとの連携という部分までは、Pythonを使用したコードやUiPathのワークフローを作成しながら、AIとRPAとの連携を理解することを目的としています。RPA業界においては「AI連携」と頻繁に叫ばれてはいますが、実例はまだ意外に少ないように思われます。プログラミング初心者でも、何かしら自身の業務に適用出来るよう、環境の構築から実装時のポイントまでステップ毎に紹介していくつもりです。
なお、既存のAIのサービスとRPAのインテグレーションについては、次回での解説を予定しています。
今回の対象読者
今回は以下の読者を想定しています。
- RPAとAIを組み合わせて何かしら実用化したい
- Pythonでの環境構築方法、UiPathとの連携方法を知りたい
- サンプルが欲しい
- 日本語のデータを利用した機械学習を実現したい
Pythonの知識は必要ですが、Python未経験の読者でも環境構築から実行までができるように説明していきます。
今回行うこと
AIといっても機械学習、ニュートラルネットワーク、深層学習と色々なジャンルがあります。今回は私が直近において実用化した機械学習(Machine Learning)の実装を基に、AIとRPAの連携方法を紹介します。
機械学習とは、コンピュータ自身に学習させることにより、インプットデータの特徴やパターンを見つけ出すものです。機械学習では、この学習の方法に「教師あり学習」「教師なし学習」「強化学習」の3つの方法がありますが、今回は「教師あり学習」を用いています。また、アウトプットは、複数に分類される「多クラス分類」と呼ばれるケースを取り扱います。
私が実用化した業務は、会計明細の仕分け作業です。会計情報は勘定科目ごとに分けられ登録されますが、各明細においては摘要として詳細な使用用途が記載されています。プロジェクト単位やチーム単位でその金額を分析する要件があり、従前はその摘要を基に、会計担当者が目視かつ手動にて分類(タグ付け)を実施していました。
機械学習として、既に過去の膨大なタグ付けされたデータがあり、これは機械学習における学習データとしては十分なものでした。このデータを基に「教師あり学習」でモデルを作成し、機械学習をRPAと組み合わせて自動化を実現しました。
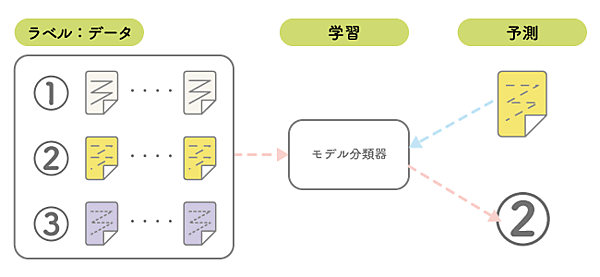
今回のコラムでは、日本語のテスト用のデータとして紹介できる丁度良いものがなかったため、Think ITサイト内の記事のタイトルとそのカテゴリの関係性を機械学習で利用します。カテゴリは5つあるため、5クラスへの分類となります。アウトプットに関しては、2択の結果(売り/買い、勝ち/負けといった0か1での判断)を予測するものと、今回のように複数の結果を予測する多クラスの予測の2種類が存在します。ただし、このデータは人間の目で見ても明確な関連性といったものはなく、機械学習に適用する事に関しては残念ながら最適ではなく、機械学習の精度は期待できないことをご了承ください。
使用する各種データ
今回使用するファイルは「python_classifier.zip」です。こちらを解凍すると以下のファイル構成になります。これが今回のコラムで必要なデータと、その作成物の一式です。
| ファイル名 | 分類 | 説明 |
|---|---|---|
| project.json | UiPath | プロジェクトファイル |
| Main.xaml | UiPath | ワークフロー |
| classifier.py | Python | 機械学習のPythonコード |
| note.ipynb | Python | 機械学習のJupyter Notebookでの検証ファイル |
| thinkit_category.csv | テストデータ | 機械学習用のテストファイル。ThinkITのサイト内の記事のタイトルとそのカテゴリをスクレイピングにて収集したもの |
scikit-learn
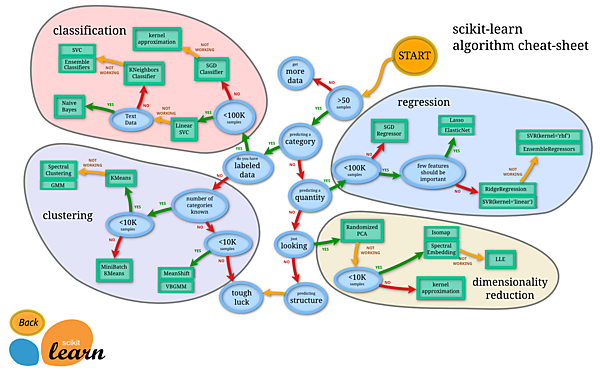
Pythonは現在、機械学習で使用されるプログラミング言語のデファクトスタンダードといえます。その理由は機能学習関連のライブラリの豊富さによるものです。中でも「scikit-learn」は機械学習のライブラリとして多くの機能を提供しており、今回もこのライブラリを利用して機械学習に取り組みます。以下は、scikit-learnで利用可能な分類モデルの一覧です。
AnacondaでPython実行環境を構築する

「Anaconda」はデータサイエンス向けのPythonパッケージなどを提供するプラットフォームで、導入することでPythonの実行環境、NumPy、Pandasといった数値解析ライブラリ、scikit-learn、TensorFlowといった機械学習ライブラリ、Jupyter Notebook、matplotlibといった便利なツールなど、機械学習に必要なものが一式で揃います。
今回は、Windows用のPyhton 3.6 64bitが含まれる「Anaconda3-5.2.0-Windows-x86_64.exe」をダウンロードし、インストールします。 最新のPyhton3.7については、現時点ではUiPathでサポートしていませんので、下記サイトより過去のアーカイブされたインストーラを取得します。
インストールは、「Anaconda3-5.2.0-Windows-x86_64.exe」をダブルクリックて実行し、インストールウィザードに従います。
Windowsにログイン中のユーザで使用する場合は、「Just Me」を選択したまま「Next」で次へ進みます。
Microsoft Visual Studio Codeのインストールもこちらで合わせて実行するか聞かれますが、必要が無ければ「Skip」で次へ行きます。
「Finish」でインストールを完了します。
以上で、インストール作業は終了です。Windowsのスタートメニューから「Anaconda Navigator」が利用できるようになります。
Janomeライブラリの追加
Anaconda Navigatorを起動します。「Environments」→「Base(root)」から、「Open Terminal」でターミナルを起動します。
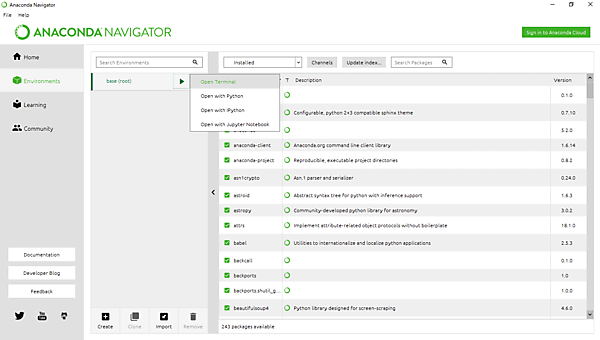
日本語を扱う上で必要となる「Janame」というライブラリをさらに追加します。こちらはAnacondaで追加できないため、コマンドプロンプト上でpip install janomeというコマンドを使って追加します。
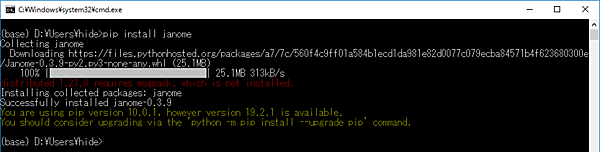
Janomeは、形態素解析を行うライブラリで、Wikipediaによると以下の通りです。
形態素解析(けいたいそかいせき、Morphological Analysis)とは、文法的な情報の注記の無い自然言語のテキストデータ(文)から、対象言語の文法や、辞書と呼ばれる単語の品詞等の情報にもとづき、形態素(Morpheme, おおまかにいえば、言語で意味を持つ最小単位)の列に分割し、それぞれの形態素の品詞等を判別する作業である。(出典: フリー百科事典『ウィキペディア』)
Jupyter Notebook
Anaconda NavigatorのHomeから、「Jupyter Notebook」を起動します。「Jupyter Notebook」は、ブラウザ上でPythonのコードを編集、実行できるソフトウェアです。数値計算の領域などで広く利用されているツールで、これ以降は「Jupyter Notebook」上で機械学習のコードを検証していきます。

今回のプロジェクトのフォルダに遷移し、右上の「New」から「Python 3」をクリックし、Pythonの実行が可能となる新規のノートを作成します。または、プロジェクトのフォルダ内の「note.ipynb」を開いても構いません。「note.ipynb」には、今回紹介するコードが全て含まれています。
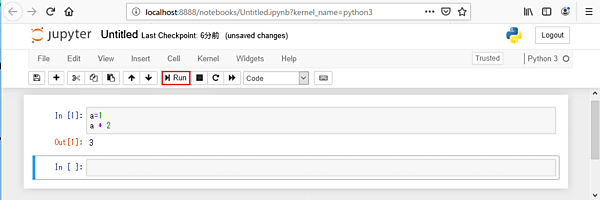
Jupyter Notebookは、Webブラウザ上でPythonを利用したプログラミング開発・実行が可能なもので、数値計算や機械学習の現場でよく使われています。使い方は「In」の項目へPythonのコードを書き込み、その状態で上段の「Run」ボタンをクリックするとPythonのコードが実行され、結果が「Out」へ表示されます。一度実行したコードの変数などはJupyter Notebook内で保持されており、次の「In」の中でも利用できます。
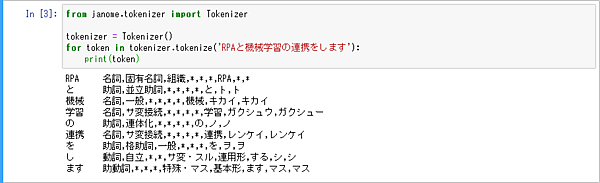
試しに、先程追加したJanomeを利用できるかをこちらのコードで確認します。
from janome.tokenizer import Tokenizer
tokenizer = Tokenizer()
for token in tokenizer.tokenize('RPAと機械学習の連携をします'):
print(token)以下のように「RPAと機械学習の連携をします」という文章が日本語として正しく構造分解されることを確認します。この通り、日本語の文章がきちんと解釈され、品詞、種類、基本形までがわかるようになります。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
