世界を1つのグラフデータベースとするトポロジー
第10回の今回は、セマンティックWebの壮大なロマンと、それを実現するための技術について解説します。
2023年11月29日 6:30
はじめに
前回は、セマンティックWebの概要とlayer Cakeの第1層と第2層について解説しました。今回は第3層からの解説を続けながら、セマンティックWebの壮大なロマンとそれを実現するための技術について解説していきます。
オントロジーとOWL
オントロジー(Ontology)とは、コンテンツ(RDFスキーマで定義されたXML形式のデータ)相互の関係(ボキャブラリー)をたくさん定義し、それらをクラスで分類した大きな辞書のようなものです。HTMLのような構造化されたデータだけでなく、非構造化データもオントロジーの対象となります。
オントロジーの肝はクラス化です。コンテンツ(リソース/インスタンス)自体の情報というよりも、コンテンツの情報に基づいてコンテンツ同士を関連付け、その関係性を用いてコンテンツをクラスに分類します。
オントロジーの記述言語として、2004年にwwwコンソーシアム(W3C)によって勧告された「OWL」があります。Web Ontology Languageの略ですが、WOLではなくフクロウの愛称でOWLと呼ばれています。OWLはコンテンツの表す概念をクラスとして分類し、クラス同士は上位、下位、同等、排他などの関連性を持ちます。
図1は鳥というクラスと個々の要素(インスタンス)の関係を表したものです。右側が両者の関係をRDFで示したもので、rdf:typeという述語(プロパティ)を使って鷹は鳥クラスのインスタンス(個体)であることを定義しています。鳩や雀など他の鳥たちも同様に定義することで左側のようなクラスとインスタンスの関係ができるわけです。
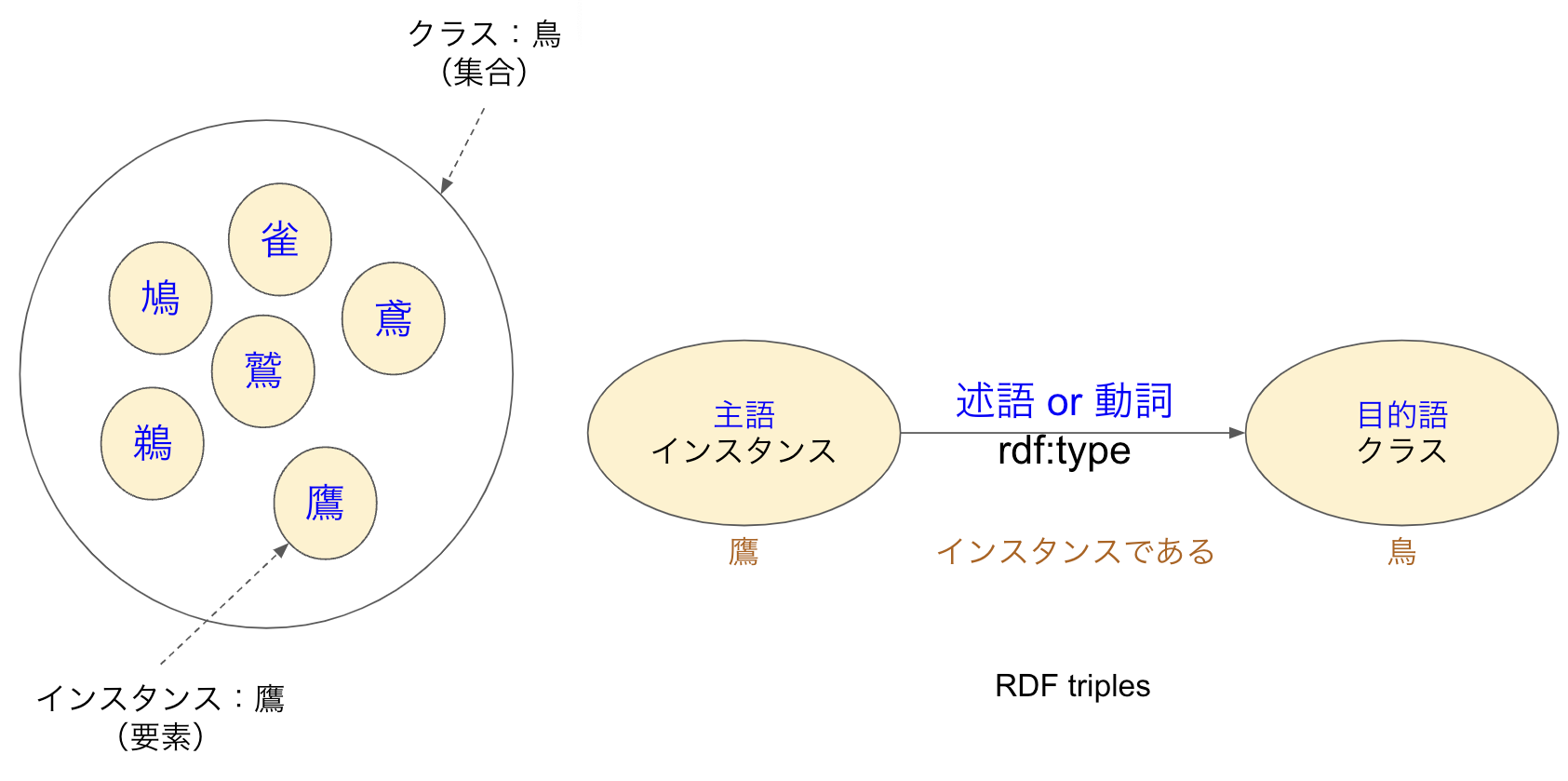
図1:オントロジーのクラスとインスタンス
図2にオントロジーの例を示したので、これを使って説明しましょう。「鳥」は「動物」のサブクラスで、「鷹」と「鳩」は「鳥」クラスの要素(インスタンス)です。これらの関係を表すのがRDF triplesの述語で「プロパティ」とも呼ばれています。
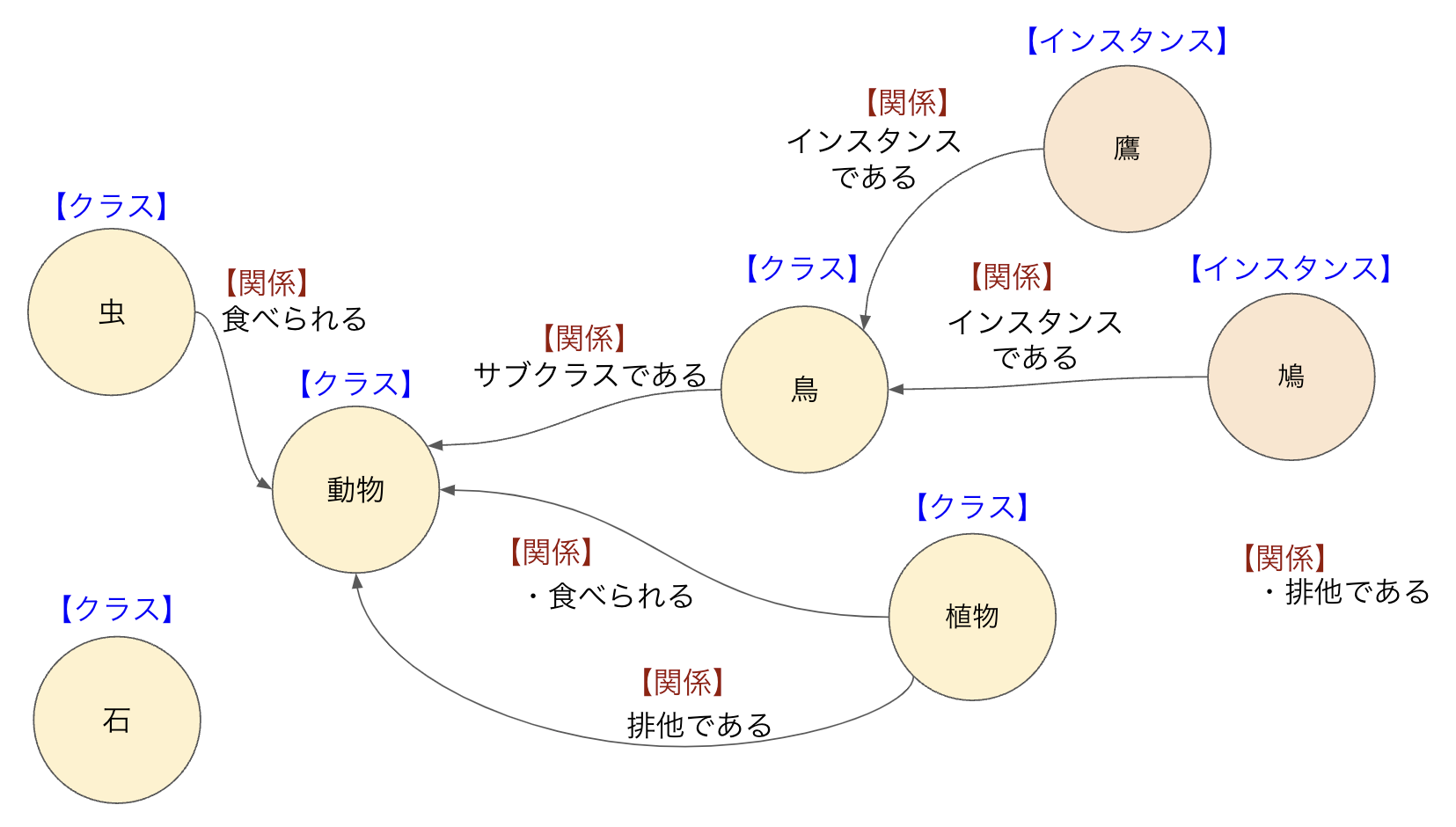
図2:OWLにおけるクラスとプロパティ
オントロジーのクラスには、オブジェクト指向と同じく継承という概念があるので、上位クラスの情報は下位クラスにも継承されます。このオントロジーでは「虫」と「動物」の関係および「植物」と「動物」の関係は「食べられる」なので、継承によって虫や植物は「鳥」やそのインスタンスである「鷹」「鳩」にも「食べられる」ことになります。また「植物」は「動物」とは別のtriplesとして「排他である」とも定義しています。
オントロジーでこのような情報を持つことにより、コンピュータは情報収集ができます。例えば、この後説明するSPARQLというクエリーで「鳥に食べられるもの?」を検索したならば、「植物」と「虫」が検索結果に表示されることになります。
あれ、鳥や動物だって場合によっては鳥に食べられると疑問を持つかも知れませんが、あくまでも検索のための知識ベースです。「鳥に食べられる」で検索したときに「動物」や「鳥」も出てほしければtriplesを付けるべきですし、期待した抽出結果として不適切になると判断したならばこのままにしておきます。
ボキャブラリー
layer cakeの4層目に「VOCABULALY」という文字があります。Vocabularyは語彙のことで、その人が持っている単語の知識とそれを使いこなす能力のことですね。語彙という日本語訳よりも“ボキャブラリーが貧困”などとそのまま使った方がピンとくるかと思います。
主語と目的語、述語で関係付けられる知識ベースの1つ1つがボキャブラリーであり、その集合体がオントロジーです。Web上にあるリソースをRDFで定義し、RDFスキーマを使ってボキャブラリーを記述するわけですが、その仕組みを標準化しただけでは何も発生しません。図2に示すような関係(ボキャブラリー)を地道に増やす作業を行って初めて、世界中のリソースが豊かに繋がってゆくわけです。
SPARQL
前回で紹介した食べられない方のLayer Cakeには、RDFやOWLの横にQuery:SPARQLというキーワードがありました。SPARQL(スパークル)はRDFデータを検索するためのクエリー言語で、SPARQL Protocol and RDF Query Languageの頭文字からネーミングされています。OWLが順番を入れ替えた略語で珍しいと思ったのですが、こちらも再帰的な略語でかなり珍しいですね。
エンジニアのみなさんは、リレーショナルデータベース(RDB)のデータを検索するための言語としてクエリーを知っていると思いますが、そのRDFデータ版だと思ってください。RDBのクエリーに合わせて作られており、SELECT FROMやWHERE、GROUP BY、HAVING、ORDER BYなども使えます。
理解しやすいように、下表でSPARQLとSQLを対比してみました。SQLの検索対象がRDBデータなのに対し、SPARQLはRDFデータが検索対象となります。RDBはテーブルにデータが入りますが、RDFはtriplesの形でデータが格納されます。大雑把に対比させると、主語がテーブル、述語(プロパティとも言います)がカラム、そして目的語が実データとなります。RDBデータと違って、RDFデータはさまざまなフォーマットのファイルなど異種データを対象にできます。
表1:SPARQLとSQLの対比
thead>| SPARQL | SQL | |
|---|---|---|
| 対象データ | RDF | RDB |
| スキーマ情報(オントロジー) | 主語 | テーブル |
| 述語 | カラム | |
| 目的語(異種) | 実データ(単種) | |
| データ型 | 述語により決まる | カラムのデータ型 |
| 別名 | プレフィックス | エイリアス |
図3は、米国Wikiで紹介されているSPARQLの例です。この例を使って説明しましょう。

図3:SPARQL(米国Wikiに掲載されている例)
最初のPREFIXは略語(別名)です。RDBのクエリーでテーブル名にエイリアス(別名)を付けるのと同じようなものだと思ってください。この例ではexというプレフィックス(接頭語)が次のURIの別名ですよと宣言しています。
<http://example.com/exampleOntology#>
<http://example.com/exampleOntology/Africa#>.
このSPARQLは、exで示されるURIのすべてのtriplesの中から、条件(WHERE節)にマッチした値(SELECT句)を取り出します。頭に“?”が付いたものが変数で、SELECT句の?capitalと?counryが取り出されるデータです。
WHERE節はAND条件なので、このSPARQLは図4のような4つのtriples(主語・述語・目的語のセット)すべてに合った?capitalと?counryは何かというクエリーです。triplesは主語-述語-目的語の順で記述しますが、最後にセミコロン(;)が付いた場合は、次のtriplesの主語は省略できます。
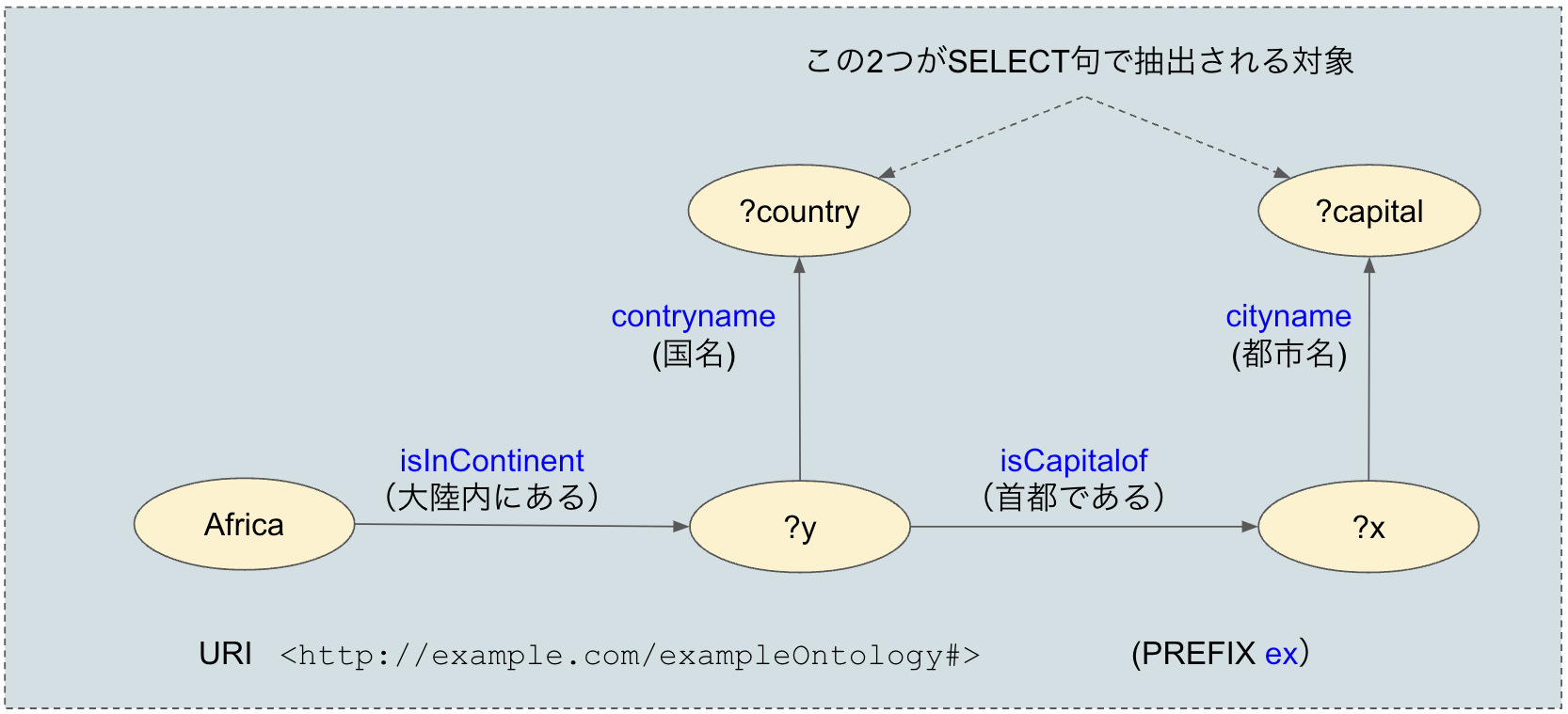
図4:4つのtriples
4つの関係を整理すると、Africaの大陸内にあるy、yの首都であるxという条件で、yの国名である(?counry)とxの都市名である?(?capital)を求めるクエリーなので、アフリカ大陸内の国名と首都名がリストで返されるわけです。
検索はクラスの述語(プロパティ)の関係を見て行なわれるので、矢印の向きは重要です。また、図を見ればわかりやすいのですが、プロパティは検索対象とはならず、あくまでもリソースが検索結果として表示されます。
LODとSPARQLエンドポイント
データをRDF化してオントロジーを作成したものを、どのように公開するか説明しましょう。図5はデータをオープンに公開する流れを示したものです。世界中で政府や研究機関、美術館、博物館などが自分たちの持っているデータコレクションをRDF化し、それをLOD(Linked Open Data)として公開しています。これらのLODにアクセスするために、SPARQLエンドポイントと呼ばれる検索サイトでWeb APIが提供されています。利用者はこれを使って公開されているデータを検索・取得できるのです。
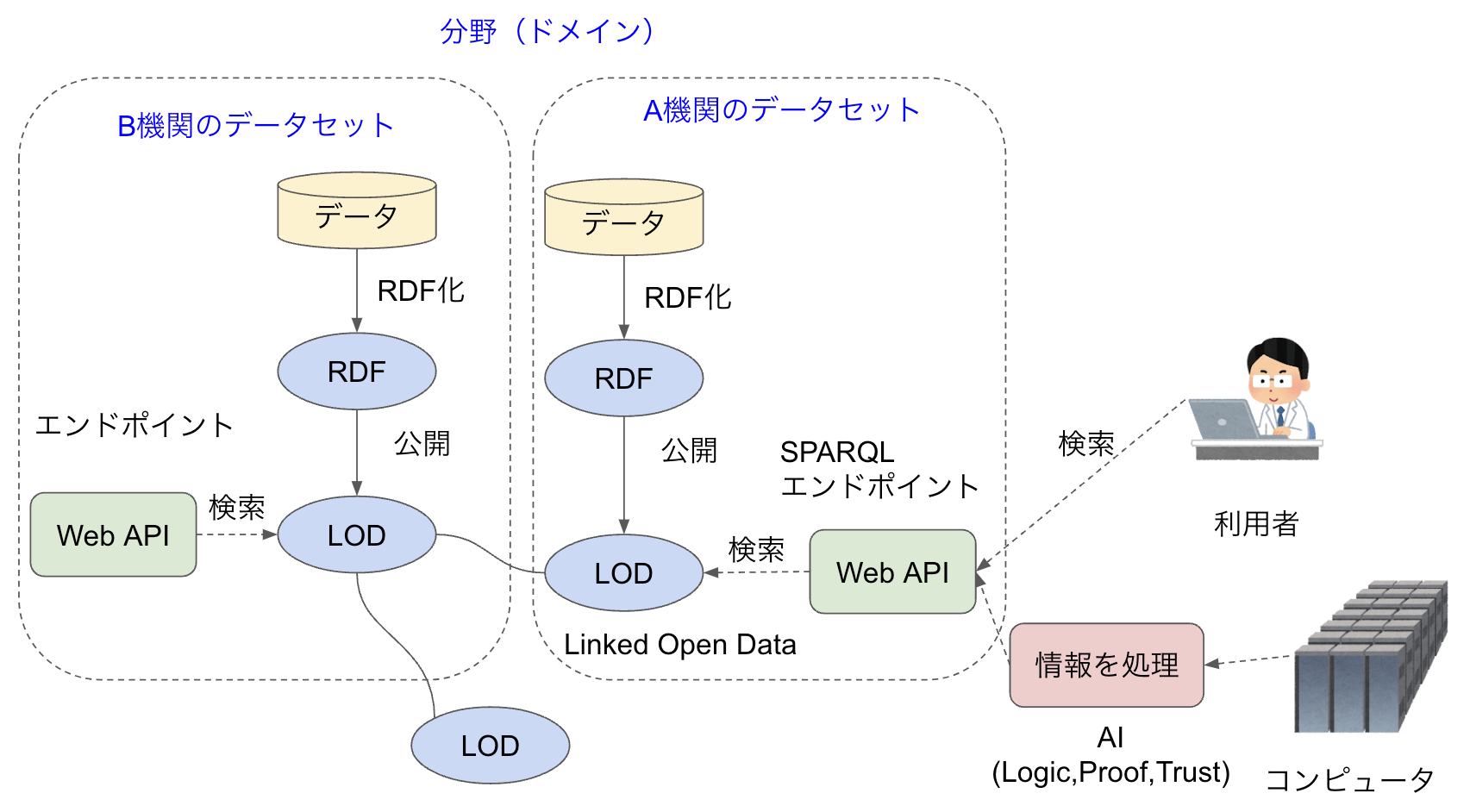
図5:OWLのクラスとプロパティ
セマンティックWebの理想は、この図のように複数のデータベース(LOD)を相互リンクして、世界中を1つのデータベースとして検索することです。しかし、残念ながらまだ発展途上なので、ほとんどのエンドポイントはその外側にアクセスできない状況です。
Layer cakeの上層部分とAI
Layer cakeの上層はこれからの課題です。Logicは検索されたデータをエージェントが処理するためのロジックです。人間がググった場合は検索結果のタイトルや説明(description)を見て情報の取捨選択を行いますが、セマンティックWebはコンピュータが自律的に推論して処理します。cakeを描いたときはAIはここまで進化していませんでしたが、今ならAIのClassificaion(分類)などで対応できそうです。
Logicに関係するのがProof(根拠・証明)とTrust(信頼性)です。AIの世界でも最近はExplainable AI(説明可能なAI)が求められていますが、エージェントが取得した情報を処理した根拠と信頼性を示す必要があります。
こうして上層部分を見ると、Logic、Proof、TrustともAIの得意領域です。AIが進化して実用化されてきた今になって、セマンティックWebが再び注目されている理由がここにあります。
なお、Layer cakeの右側のdigital signatureはコロナ禍で急速に普及が広まったデジタル署名(公開鍵暗号技術)で、前回のLayer cakeではこの部分はCrypto(暗号技術)となっていました。ブロックチェーンやNFTと通ずる部分であり、ここにきて両者およびAIがつながったことがちょっとわくわくさせられます。
RDF普及の現状と実用例
2005年前後のブームは、ガートナーのハイプ・サイクルにおける“「過度な期待」のピーク期”だったと思います。“幻滅期”を迎えてブームは沈静化しましたが、その後も世界中の人たちが地道に努力を続けてきています。データをRDFで公開している事例は世界中にたくさんありますが、ここでは日本の状況について、いくつか紹介します。
「e-Stat 統計LOD」
政府統計情報をワンストップサービスで提供することを目指した政府統計ポータルサイト(e-Stat)の開発者向けページで、国勢調査や人口推計、消費者物価指数などさまざまな統計LODのデータ提供が行われています。
・Linked Open DataチャレンジJapan
LODの技術普及の促進を目指したLODチャレンジというイベントが2011年から毎年行われています。「データ作成部門」と「データ活用部門」の2部門で多くの応募作品が寄せられていますので、興味のある方はご覧ください。ちなみに「LODチャレンジ2022」の最優秀賞はPatient Locational Ontology-based Data (PLOD)というもので、場所や行動に紐づくCOVIT-19感染リスクの推論が可能なオントロジーをテーマにしたものでした。LODチャレンジは2023年も行われており、12月16日に授賞式が予定されています。
・DBCLS
・DBPedia
DBPediaは、Wikipediから情報を抽出してLODとして公開するコミュニティプロジェクトです。本家のDBPediaはWikiPedia英語版を対象としていますが、Wikipedia日本語版を対象としたDBPedia Japaneseもサービス提供してくれています。例えばDBPedia Japaneseのリソース例から「ももいろクローバーZ」をクリックして見ると、プロパティとしてabstract(概要)、メンバー、レーベル、事務所、公式サイト、名前、活動機関などさまざまなデータが取得されているのがわかります。
おわりに
セマンティックWebは、もしこれが実現すれば、世界中のWeb上の情報が1つのデータベースとして利用できる壮大なロマンです。そして、その夢の実現のために世界中で多くの人たちが一生懸命取り組んでいます。
一方で「そんな時代は来ない」と考える人もいるでしょう。ここに来てChatGPTのようなLLM(大規模言語モデル)が急に出現し、わざわざコンピュータ向けにメタデータを付加しなくても、生成AIが良い塩梅に解釈できそうにもなっています。
しかし、生成AIのような優れたAIが出現したからこそ、AIが世界中のデータを最適に使いこなして素晴らしいベネフィットを生み出すためにセマンティックWebの存在価値が増したとも考えられます。現在のWebだって一昔前までは考えられないような奇跡的な出来事です。セマンティックWebのメタデータ作成を生成AIが行ってくれれば、セマンティックWebが当たり前になる世界が来るかもしれません。エンジニアの1人として、そんなロマンの実現を信じたいと思っています。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
