ファインチューニングの課題を解決する「RAG」と「エンべディング」
第13回は、企業データを追加学習する方法の1つであるファインチューニングについて、その課題を解決する「RAG」と「エンべディング」を解説します。
2024年4月3日 6:30
はじめに
前回は、企業データを追加学習する方法の1つであるファインチューニングのやり方について解説しました。今回は、もう1つの有力な方法である「RAG」と「エンべティング」について解説します。「ベクトルデータベース」という難しそうな世界に入り込みますが、質の良い学習データを多数用意しなければならないファインチューニングに比べて利点も多い方法です。
ファインチューニングの課題
RAGを解説する前に、ファインチューニングの課題についておさらいしておきましょう。ここでは、製品マニュアルを追加学習させてユーザーの質問に回答するQ&A botを作る想定とします。
(1)学習が大変
生成AIにマニュアルを読ませるだけでQ&A botができれば楽なのですが、そんな簡単にはいきません。ファインチューニングも機械学習の1つの手法なので、良質な学習データをメッセージの形でそれなりの量用意して、学習精度を確認しながら繰り返しトレーニングする必要があります。
(2)追加学習内容で回答するとは限らない
生成AIは、世の中の大量データを使って事前学習(Pre-training)して最適にパラメータ調整された汎用モデルです。ここに(相対的には)塵のように少量のマニュアルを追加学習(Fine-tuning)してパラメータを微調整したものがQ&A botです(図1)。
ユーザーがbotに対して独自データに関する質問を行った際に、必ず追加学習した中から答えてくれれば良いのですが、そんな保証はなく事前学習されたデータの中からもっともらしい回答を作るかもしれません。
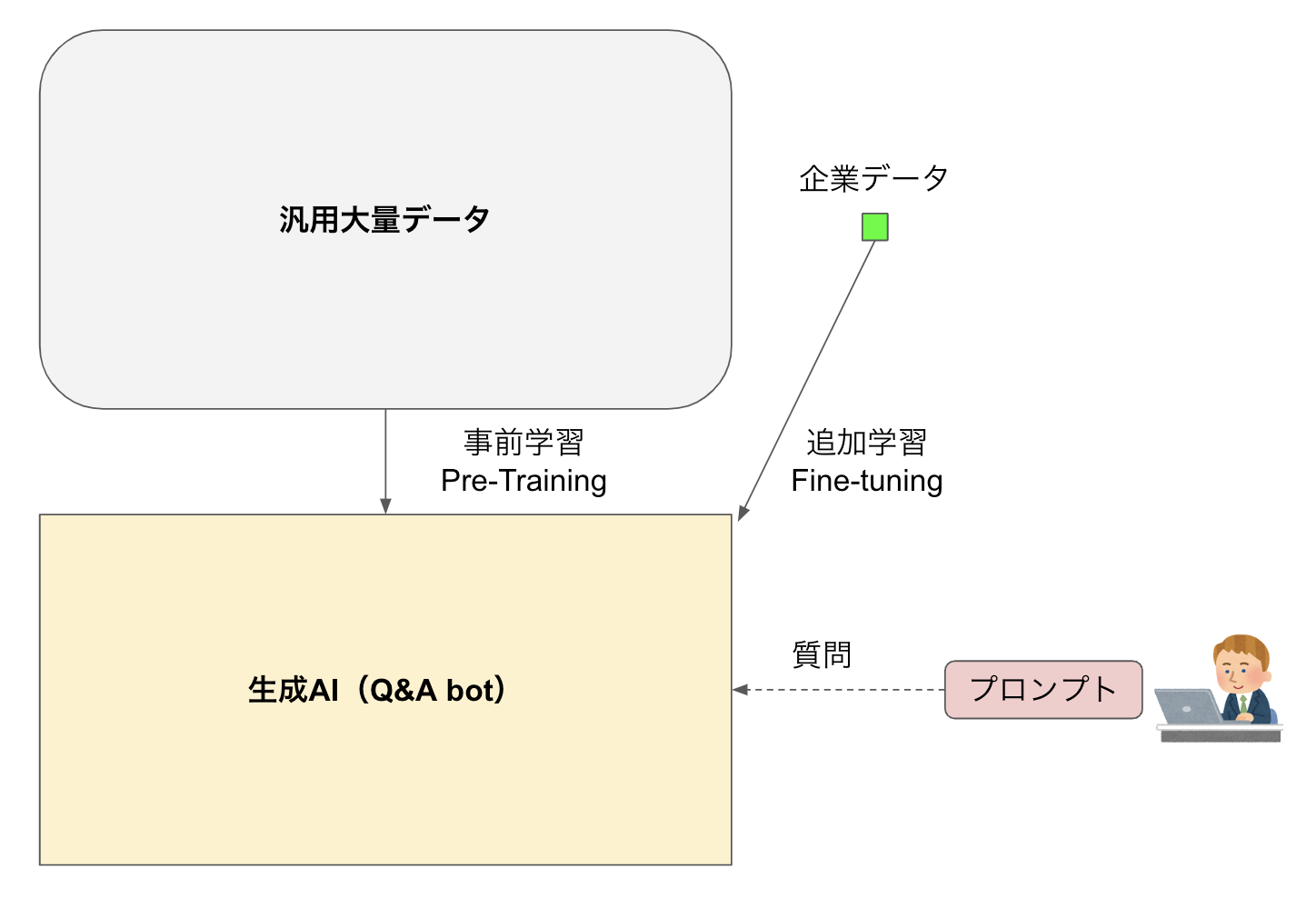
図1:Pre-trainingとFine-tuning
(3)応答の不確定性
生成AIは、ユーザーが同じ質問をしたとしても同じ回答を返すとは限りません。これは、生成AIが多様な訓練データで学習しており、確率的選択アルゴリズムやランダム性を用いていることに起因する現象で「応答の多様性」「出力の不確定性」などと呼ばれていますが、生成AIの柔軟性や創造性を示す特徴でもあります。
この特性は、チャットのような対話においては新鮮で多様な会話が弾む効果をもたらします。しかし、Q&A botのように必ず正解を回答してほしい用途には相性が悪いです。あるときは正解を返したのに、もう1回質問をした際に異なる回答をするようでは、ビジネスで使うための信頼性を確保しにくくなります。
RAGとは
上記のような課題を解決するための全く別のアプローチとして注目されている技術がRAG(Retrieval-Augmented Generation)です。Retrievalは「検索」、Augmentedは「拡張された」という英単語で、生成AIに情報検索機能を組み合わせたモデルを意味します。
図2にファインチューニングとRAGの違いを示しました。ファインチューニングは独自データを追加学習して生成AI自体を追加学習させる方法です。一方、RAGは生成AIはそのままで外部に独自データを格納したベクトルデータベースを用意し、この情報を検索できる仕組みが拡張されています。
図2:ファインチューニングとRAG
LLM Orchestration Framework
RAGを構成する主役がLLM Orchestration Frameworkです。これは、LLM(大規模言語モデル)を有効活用して、より柔軟にユーザーの要求を実現するフレームワークです。オーケストレーションとは、いろいろなツールやサービス、データベースなどを管理・コントロールして、複数のタスクを組み合わせることです。
図3に主なLLM Orchestratorを4つ示します。これらはまさにRAGの中心的な役割を担うもので、アメフトのクォーターバック、バスケのポイントガードのような司令塔として機能します。
図3:主なLLM Orchestrator
・LangChain
LangChain(ラングチェーン)は、ChatGPTなどの大規模言語モデル(LLM)をより効率的に利用するために機能拡張するオープンソースのライブラリです。モジュール性や拡張性に富み、異なる言語モデルをアプリケーションに統合しやすいフレームワークです。
・LlamaIndex
LlamaIndex(ラマインデックス)は、LangChainと並んで有名なフレームワークで、ベクトルデータベースなどを利用したRAGを構成するのによく使われるほか、モデルの特性やパフォーマンスを評価するLLMOps的な特徴も持っています。
・Sementic Kernel
Sementic Kernel(セマンティックカーネル)は、マイクロソフトによって開発されたオープンソースのSDKです。このツールを使うことでユーザーと対話して自律的にタスクを処理してくれるAIエージェントを構築でき、第8回で紹介したMicrosoft Copilotなどにも利用されています。
・orkes
orkes(オークス)はNetflix Conductorというオープンソースのプラットフォームをベースに構築されたLLM Orchestratorです。orkesという名前もOrchestratorから取ったもので、モジュール設計による複雑なアプリケーション構築とスケーリングに特徴があります。
LLM Orchestrationと同じく、大規模言語モデル(LLM)の運用効率とパフォーマンスの最適化を行う概念にLLMOpsもあります。これはDevOps(開発:Developmentと運用:Operationsの融合)から派生した言葉で、LLMの開発と運用を融合させるものです。具体的には、言語モデルのトレーニング、デプロイ、監視、スケーリング、メンテナンスを統合的に管理して、性能と効率を最適化することを指します。
LLMOpsとLLM Orchestrationは、ほぼ同じニュアンスで使われますが、厳密に言えばLLMOpsの方が少し広範な意味合いで使われます。LLMOpsが開発、トレーニング、デプロイ、メンテナンスなどLLMの開発と運用全般をカバーしているのに対し、LLM Orchestrationはもう少し具体的に、言語モデルの統合や情報検索、タスク処理に焦点を当てています。つまり、LLMOpsはLLMの開発と運用に関する包括的アプローチなのに対し、LLM Orchestrationはその中の特定の実装戦略になります。
なお、このようなLLMを活用するためのアプリケーションのことをLLM駆動アプリケーション(LLM-Driven Applications)とも呼びます。
LangChain
LLM Orchestratorの役割を理解するために、Langchainの機能について説明します。LangChainには図4のような機能が備わっており、目的に応じてこれらを組み合わせて生成AIを柔軟に使いこなすことができます。
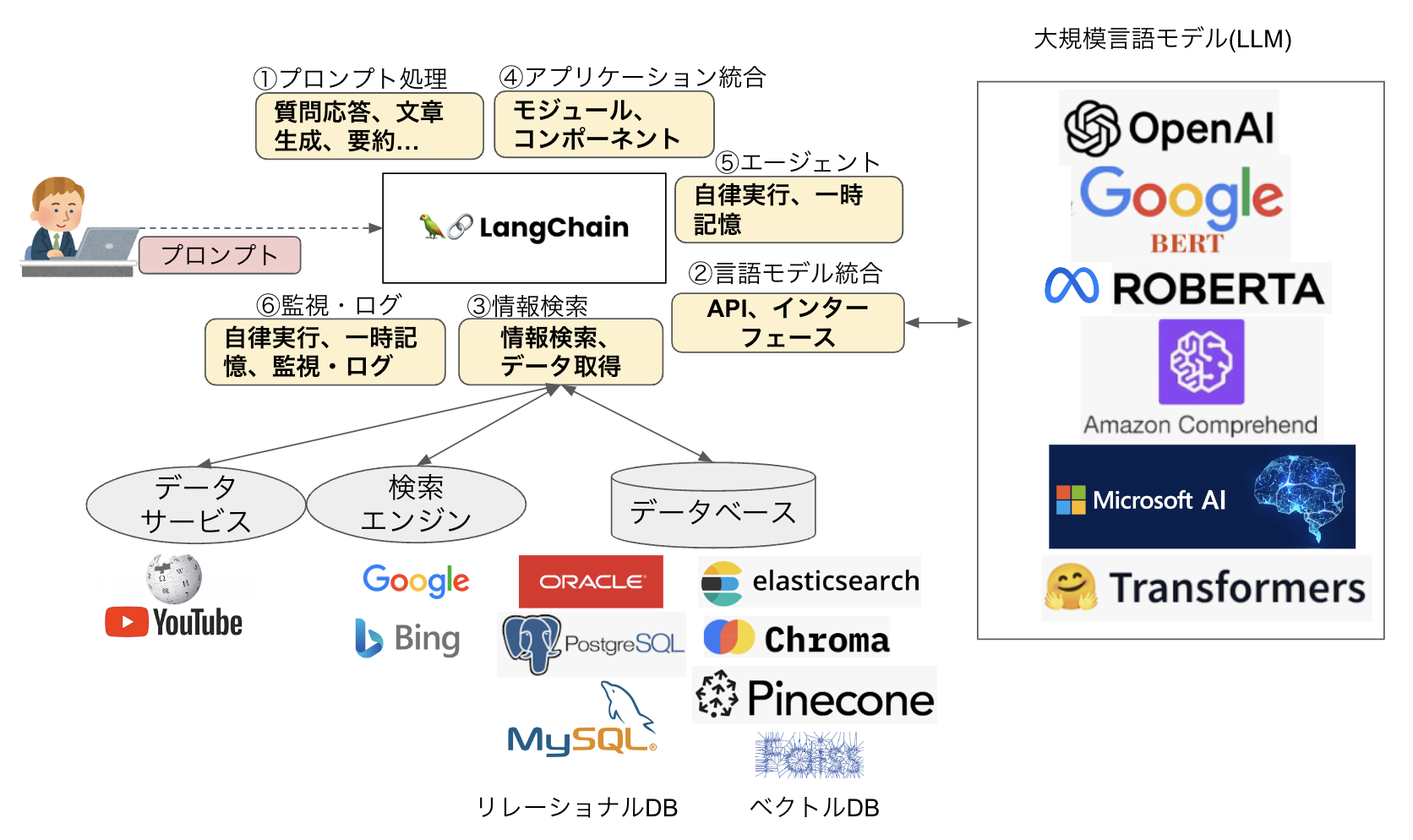
図4:LangChainの主な機能
①プロンプト処理(Prompt Engineering)
ChatGPTのような大規模言語モデル(LLM)はユーザーからのプロンプトを直接受けて、その要求に適した回答を返します。一方、LangChainはユーザーと大規模言語モデル(LLM)の間に入り、ユーザーからの要求を解決するためにさまざまなツールやリソースを駆使して、LLM単体よりさらに効果的な回答を返します。
②言語モデル統合(Model Management)
LangChainは、ChatGPTやGoogle BERT、Meta RoBERTa、AWS Comprehend、Azure AIなどさまざまなLLMのインターフェースやAPIを持っています。また、多くのLLMをサポートするHugging FaceのTransformersというオープンソースのライブラリとも連携できます。
一般にユーザーが複数のLLMを使い分ける場合はそれぞれにログインして利用することになりますが、LangChainを使えば簡単に言語モデルを切り替えたり、組み合わせたりができます。実際にはLLMを使い分けるような利用方法はあまり思い浮かびませんが、各種LLMに接続できるインターフェースを持っていることは大きな特徴と言えます。
③情報検索(Data Management)
LangChainは、外部データベースと連携して独自データを取得したり、検索エンジンと連携してネット上の情報を取得したりできます。PDFやCSV、Word、PowerPointなどほとんどのデータ形式に対応しており、NotionやFigma、Youtube、Wikipediaなどさまざまなアプリケーションデータもサポートしています。
データベースはOracleやPostgreSQL、MySQLなどのRDBMSの他に、elasticsearch、Choroma、Pinecone、Faissなどのベクトルデータベースとの連携もサポートしています。
④アプリケーション統合(Integration with Applications)
LangChainは、さまざまな機能を持つモジュールやコンポーネントで構成されており、特定のタスクに必要な機能を実現するために、これらを柔軟に組み合わせることができます。入力されたプロンプトは、前回解説したプロンプトチェーン技術により複数のプロンプトに分けられ、エージェントによって実行されます。
⑤エージェント(Agents)
エージェントは、自律的にさまざまなタスクを実行します。Memory機能により実行途中の状態を保持することもできます。例えばLLMが学習していない新しい情報が必要な場合はWeb検索を実行して最新データを取得してLLMに渡したり、データベースにクエリを発行して情報を取得したり、コードを実行して技術的な問題を解決したりできます。
⑥監視・ログ(Monitoring & Observability)
Callbacks機能により実行状態やパフォーマンスをモニタリンできます。また、ログを取得してトラブルシューティングに利用することも可能です。LLMを不正アクセスや悪意のある攻撃から保護し、データの暗号化やマスキングを行うセキュリティ機能も有しています。
つまり、LangChainはユーザーからのプロンプトに適切に対応するために、大規模言語モデル(LLM)を使ったり、GoogleやBingなどの検索エンジンでネット検索したり、独自データベースの情報を使ったりしながら、質問応答や文章生成、要約などを行える“有能なコンシェルジュ”なのです。
RAGを使った独自データ検索
図5にRAGの構成例を示します。ここでは自社製品マニュアルをベクトルストアに格納したQ&A botを作成することとします。LLMにGPT-4 Turbo、LLM OrchestratorにLlamaIndex、ベクトルデータベースにElasticsearchを使っていますが、他の製品の組み合わせでも同じように独自データを使った応答処理を構築できます。RAGがユーザーからのプロンプトを受け取ってどのように処理するのか、順を追って説明しましょう。

図5:RAGを使った独自データ検索
①ベクトルデータベース
RAGは生成AIそのものを追加学習するのではなく、独自データをベクトルデータベースに格納して生成AIが検索できるようにします。そのため、最初に製品マニュアルをベクトル形式に変換(Embedding)し、ベクトルデータベースに格納しておきます。ファインチューニングの学習データと違って1メッセージずつ学習データを作る必要がなく、いっきに読み込ませることができるのがEmbeddingの楽なところです。
②プロンプト入力
ユーザーからプロンプトが入力されると、LLM Orchestrator(LlamaIndex)はプロンプトチェーンなどのプロンプト処理技術を用いて、ユーザーがどのような内容を問い合わせているのか適切に解釈します。
③LLMに問い合わせ
「エージェント」は「アプリケーション」の設定内容に応じて自律的にタスク処理を行います。プロンプトが質問だった場合、エージェントは「言語モデル統合」により接続されているLLM(GPT-4 Turbo)に問い合わせを行います。
④セマンティック検索
プロンプトの内容が自社製品に対する問い合わせだった場合、LLMにはそのような独自情報がないため適切な回答を返すことができません。そこで、エージェントはベクトルデータベースをセマンティック検索し、問い合わせ内容に近いデータを返します。
⑤LLMに再問い合わせ
エージェントはデータベースから得られた情報を再度LLMに送信し、LLMから適切な回答(Completion)を受け取ります。このやり取りは1回だけとは限らず、適切な回答が得られるまで何回か行います。
⑥回答を出力
エージェントはLLMとやり取りして得た回答をユーザーに応答します。ユーザーと分かりやすい自然言語でやり取りするのはLLMの十八番(おはこ)ですね。
ベクトルデータベース
RAGでは検索対象となる独自データをデータベースに格納しますが、ここで使うのは我々が慣れ親しんでいるリレーショナルデータベース(RDB)ではなくベクトルデータベースです。概念自体は2000年代からありますが、AIの急速な発展に伴い脚光を浴びている技術なので説明しておきましょう。
ベクトルデータベースとは
ベクトルデータベースは、文書や画像などのデータを高次元ベクトル形式で格納するデータベースです。ここで文章などの自然言語データをベクトル空間に配置することをエンべディング(Embedding)と言います。ベクトルデータベースの特徴は類似検索に強いことです。図6のようにベクトル変換されたクエリと格納されているベクトルデータとのポイント間の距離(類似度)を計算し、最も近いデータを検索結果として出力します。
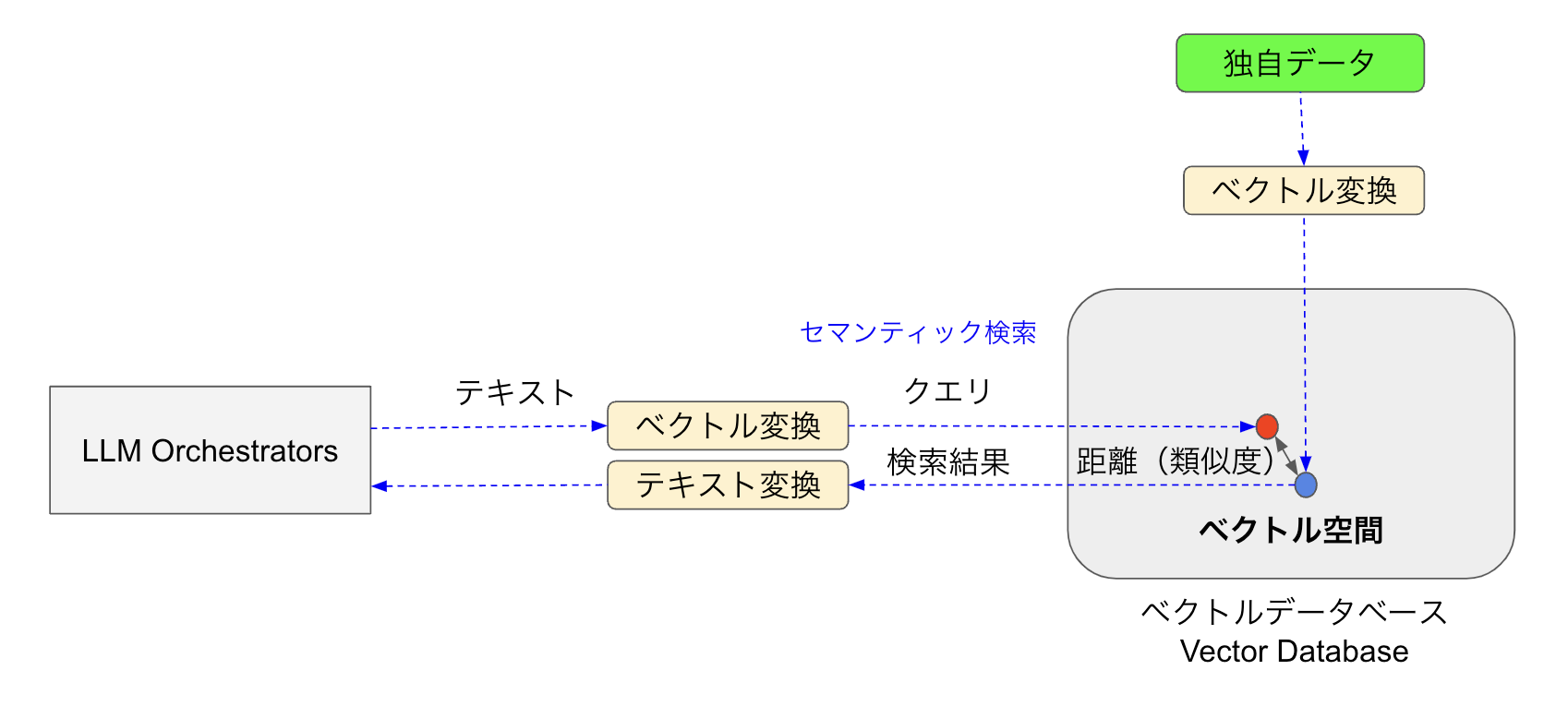
図6:ベクトルデータベースの類似検索
RDBやNoSQLとの比較
ベクトルデータベースの特徴を理解するため、表にRDBおよびNoSQLとの比較を示します。以下、主な違いを説明しましょう。
表:RDBとNoSQLとベクトルDBの比較
| RDB | NoSQLデータベース | ベクトルデータベース | |
|---|---|---|---|
| 用途 | 業務データベースなど | ビッグデータや分散システムなど | 類似検索やレコメンデーションなど |
| データ構造 | テーブル形式(行と列) | キーバリュー、ドキュメント、グラフなど | ベクトル形式(多次元配列) |
| 検索機能 | SQLに完全一致するデータのみ取得 | 大量データを高速で読み書き | 類似度ベース検索に特化(高速) |
| スケーラビリティ | 限定的。水平・垂直ともスケーリングが弱い | 高い。分散処理に強い | 高い。大規模なベクトルデータを格納 |
| トランザクション | 強い(ACID特性) | 弱い | 弱い |
| データの整合性 | 強い | 弱い | 弱い |
| 主な製品 | Oracle、SQL Server、MySQL、PostgreSQL | MongoDB、DynamoDB、Redis、Cloud Datastore | Faiss、Milvus、Elasticsearch、Annoy |
①データ後続と検索機能
RDBはデータを構造化してテーブルに格納し、クエリに完全に合致したデータを検索結果として出力します。NoSQLのキーバリューストアも同じく、キーに完全に一致したデータを返します。これに対して、ベクトルデータベースはクエリに最も類似したデータを返すので、少し曖昧な(AIっぽい)検索となります。
②スケーラビリティと検索速度
RDBは水平、垂直ともスケーラビリティが限定的で、データ量が大きくなると検索速度も低下します。これに対してNoSQLとベクトルDBはスケーラビリティが高く、データ量が大きくなっても高速に検索できます。
③トランザクションとデータ整合性
RDBはACID特性で表されるようなトランザクション処理が保証されており、データ整合性を担保する必要のある業務システムなどで幅広く使われています。一方、NoSQLやベクトルDBはトランザクションが弱く、一時的に整合性が取れなくなる場合もあるため、ミッションクリティカルな業務システムではなく、大量データの格納や類似検索などの目的で利用されます。
ASID特性は、データベース管理システム(DBMS)がトランザクション処理を保証するための下記の4つの基本特性です。RDBMSはこれら4つの特性をカバーしていますが、NoSQLやベクトルDBはこのうちのどれかを犠牲にしていたりします。
- Atomicity(原子性):トランザクションは成功するか、失敗するかのどちらかであること
- Cosistency(一貫性):トランザクションが完了すると、一貫した状態を保つ(結果の揺れがない)
- Isolation(独立性):複数のトランザクションが同時実行される場合、互いに影響を与えない
- Durability(永続性):トランザクションがコミットされると、その結果は永続的に保持される
セマンティック検索
図6のセマンティック検索について説明しましょう。semanticは「意味の」という単語で、セマンティック検索は「意味的検索」と訳されます。RDBでよく使われるキーワード検索は、キーワードに(前方/部分)一致するテキスト文を探します。一方、ベクトルDBに対するセマンティック検索は、単にキーワードの一致だけでなく、クエリーの意図や文脈(これが意味)を理解して、関連性の高い情報を抽出します。
例えば「セマンティック検索とは?」というクエリをベクトルDBに発行した場合、クエリのキーワードが直接含まれていなくても「ベクトルデータベースの類似性検索とは」「ベクトル間の距離と類似度の関係」などのデータポイントの中から、最も類似度の高いものを検索結果として返してくれます。
セマンティック検索のプロセス
ベクトルデータベースに対するセマンティック検索は、次の3つのステップで実現されます。
①データのベクトル化
テキストや画像、音声などのデータを多次元ベクトルに変換してベクトルDBに格納します。この変換には自然言語処理(NLP)技術が用いられ、データの意味的な内容がベクトル空間上の点として表現されます。
②類似度の計算
ベクトル変換されたクエリとデータベース内の各データポイントの間の類似度を計算します。類似度はベクトル間の距離に基づいてスコア化されますが、「クエリの意味」と「データの意味」というようにそれぞれの“意味”の関連性で測定されるのがセマンティック検索の特徴です。
③関連性の高い情報の抽出
各データポイントとの類似性スコアに基づいて、最も関連性の高いデータポイントを検索結果として出力します。
ベクトルデータベースは高次元のベクトルデータを格納します。ここで言う「次元」とは、ベクトル空間内のデータポイントが持つ特徴や属性を意味します。
例えば「赤丸」という画像データを次元で表してみましょう。形状:円、半径:5cm、線の太さ:2mm、色:#FF0000、透明度(アルファ値):1、線種:実践という6つの次元を持てば、誰でも同じ赤い丸線を描くことができます。では「ペンギン」という単語はどうでしょうか。このデータの特徴は「鳥である」「飛べない」「立って歩く」「泳げる」「背中が黒」「腹が白」…というようなもので、300くらい示せばペンギンを定義できそうです。そして、これらの特徴を次元として数値化することがベクトル化なのです。
ベクトルデータベースは文章や画像、音声などのデータを高次元で数値化してベクトル空間に格納します。次元が高次元になるほど細かな意味の違いを表現できますが、計算量やメモリも増加します(次元の呪いと言います)ので、ある程度で抑えてベクトル化します。
まとめ
今回は、以下のような内容について学習しました。
- ファインチューニングには「学習が大変」「追加した内容で回答するとは限らない」「応答が不確定」という課題がある
- RAGは生成AIに独自データの検索機能を拡張したモデル
- RAGを構成する主役がLLM Orchestration Frameworkで、LangChain、LlamaIndex、Semantic Kernel、orkesなどがある
- LLM Orchestrationと似たような言葉にLLMOpsやLLM駆動アプリケーションなどもある
- LangChainは主な機能として、プロンプト処理、言語モデル統合、情報検索、アプリケーション統合、エージェント、監視・ログなどがある
- RAGはプロンプトの意味を解釈し、独自データを格納したベクトルデータベースにセマンティック(意味)検索してLLMと相談しながら適切な回答を返す
- 文章などの自然言語データをベクトル空間に配置することをエンべディングと言う
- ベクトルデータベースは情報を高次元ベクトルデータで格納し、クエリとの類似度(距離)の近いものを返す
次回は、生成AIを利用したプログラミング支援について解説します。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
