Dockerコンテナ環境のバックアップツール「Convoy」を使う
Docker環境のバックアップツールとして注目されるConvoyのインストールから使用方法までを解説します。
2016年3月30日 12:19
昨今、Dockerの知名度もかなり向上し、数年前に比べるとコンテナ化も進んできた。しかしDockerの利用シーンの大部分は、個人での利用や検証環境という枠を超えておらず、本番環境や開発環境でのコンテナ運用が一般的になるのはまだ先の話になるだろう。
複数のユーザがDocker環境を利用する際には、どのような点に考慮すべきだろうか?まず個人での利用とは異なり、様々な運用を想定する必要がある。その中でもバックアップとリストアは、考慮すべき課題である。
Dockerコンテナ自体は作成と廃棄を繰り返す小さな仮想環境であるが、コンテナの中にあるデータは保護すべき対象なのは疑うまでもない。本記事では「データの保護」つまりコンテナ環境のバックアップについて考える。
これまでのバックアップ
これまでの環境ではどのようなバックアップがあったのか、軽くおさらいしてみよう。
物理環境
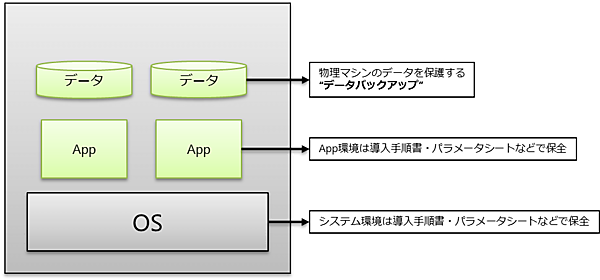
物理環境では、必要なデータは保存領域にバックアップされていたことだろう。しかし環境が動作中に、サーバ全体をバックアップするというのはハードルが高かったはずだ。もちろん技術的には、ddコマンドや商用バックアップ製品を利用して環境全体をバックアップすることは可能だが、環境全体を定常的にバックアップする運用は珍しく、OS部分やアプリケーションの設定等は手順書やパラメータシートで保管されるのが一般的だ。
仮想環境
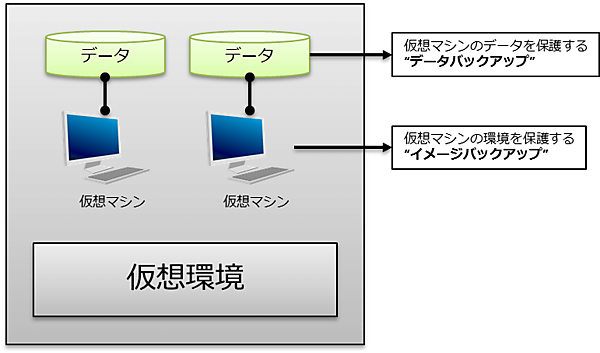
ここで言う仮想環境とは、VMWare等の仮想環境基盤を表している。仮想環境では物理環境と大きく変わり、仮想環境を丸ごとバックアップ出来る「イメージバックアップ」という手段が登場した。加えて物理環境でもあったデータバックアップを組み合わせることで、障害のレベルによってリカバリ方法を定め、復旧時間を短縮できた。
コンテナ全体の保護は必要か
上記でおさらいしたバックアップ手法を踏まえると、コンテナ環境ではコンテナ全体の保護、すなわちコンテナのイメージバックアップが必要に思える。しかし結論から言えば、コンテナ全体の保全は「不要」だと宣言したい。
コンテナ環境も仮想環境の一つだが、従来の仮想環境とは異なる点が随所に見られる。その最たる例が、Dockerの定番とも言える機能「Dockerfileからのコンテナデプロイ」だ。Dockerfileを利用することによって実現される“Infrastructure as Code”により、環境の再作成が容易になっている。さらにDockerfileの機能では不十分ならば、ChefやAnsible等の外部ツールを併用しても良いだろう。
Infrastructure as Codeの台頭によって、システム起因の障害が原因でコンテナ環境自体の復旧が困難な状況でも、コード化されたインフラコード(Dockerfile等)を利用し、全く同じ環境を再作成することが可能になった。そのため、コンテナ環境ではコンテナ全体の保護は不要となる。
端的に言えば「コンテナ環境ではコード化されたインフラを用意して運用することで、環境全体のバックアップは不要となる」ということだ。
コンテナ内の必要なデータの保護
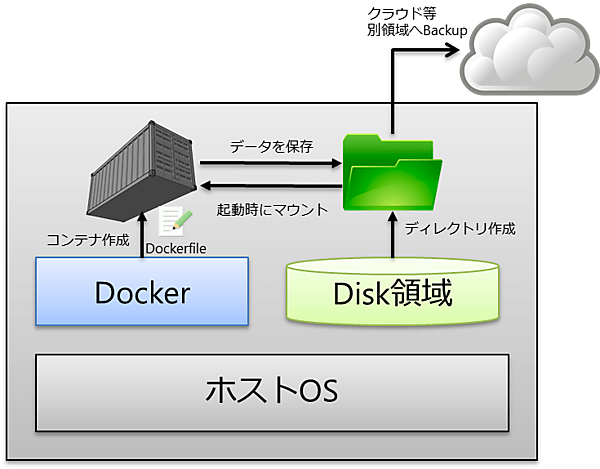
こちらは従来のバックアップで言えば、データバックアップの部分に相当する。コンテナ全体の保護は必要ないと前述したが、もちろんデータ部分のバックアップは必須だろう。
Dockerの運用で一般的なのは、コンテナ起動時に「-v(volume)」オプションを付けてホストOS上の一部の領域をマウントし、そこにデータを保存することでコンテナ内のデータ消失に備える手法だろう。しかしながらこの方法で運用出来るのは、個人利用の場合に限られるであろう。
複数人でDockerを利用すると、まずホストOS内の「汚染」が始まる。コンテナにマウントするためのディレクトリが乱立し、どのパスのディレクトリをバックアップすれば良いかすら分からない状態となるだろう。
このようにホストOS内が無法地帯の状態では、Dockerの運用どころではない、それを防ぐために次は、マウント専用の領域が用意され、「この領域の配下にマウント用ディレクトリを作成してください」というようなルールが出来上がるはずだ。
しかし、それでもバックアップはうまくできないだろう。なぜなら、管理者には必要なディレクトリと不要なディレクトリの判断がつかないからだ。それこそマウント専用の領域全体をバックアップしても良いのだろうが、不要なファイルをバックアップするのは、バックアップ設計としては好ましくない。
このような状態が生じる原因は、Dockerコンテナとコンテナにマウントさせるディレクトリが分離している点にある。そこで、この問題の解決策となりうるConvoyを紹介しよう。
Convoyという選択肢

Convoyとは
Convoyは、Dockerのプラグインとして開発されたストレージドライバ兼バックアップソフトウェアである。
Convoy Github
https://github.com/rancher/convoy
Convoyの特徴を、以下に示す。
- 2015/08/19 初公開
- 開発元はRancher.Labs社
- Dockerのプラグインとして提供
- 執筆時の最新バージョンはv0.4.2rc1
- 動作環境はDocker v1.8以上
- 独自のストレージドライバを提供
- 独自のコマンド「convoy」を利用してバックアップとリストアを実行
- バックアップの保存先にクラウドを利用可
- 執筆時はRancherとの連携はない
今後の展望として、Rancherへの統合とKubernetesへの連携がConvoyリリース時に話されている。
Introducing Convoy a Docker Storage Driver for Backup and Recovery of Volumes
Convoyの動作
Convoyを利用した領域マウントされたコンテナ起動
Convoyは導入時にDocker及びストレージドライバと連携し、コンテナ起動時に自動で領域を確保してくれる。Convoyを利用したコンテナの起動は、下図のようになる。
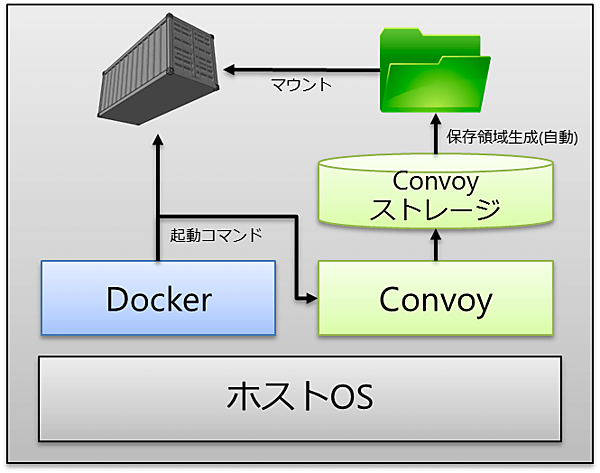
その挙動は以下の通りだ。
- Dockerコマンド(convoyオプション付与)でコンテナ起動
- Convoyストレージからコンテナに割り当てる領域を自動でアサイン
- コンテナへ割り当て
今までの「ホストOSにディレクトリを作成してコンテナ起動時にマウント」という工程が、Dockerコマンドワンラインに集約される。==== Convoyを利用したバックアップ
Convoyによるバックアップは、convoyコマンドを利用してスナップショットを取得し、その後バックアップを取得する形となる。
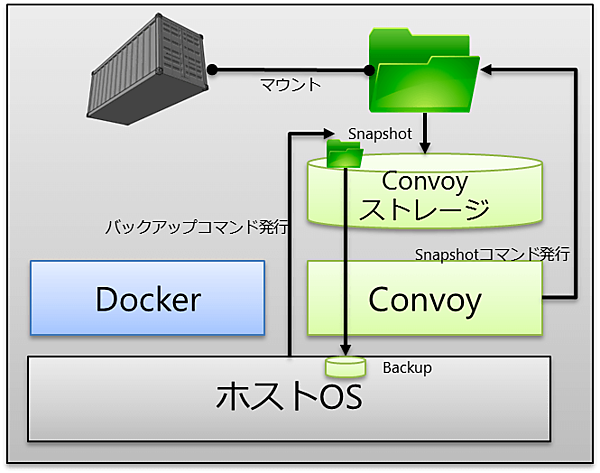
その挙動は以下の通りだ。
- Convoyからスナップショットのコマンドを発行
- Convoyストレージの中にスナップショットを取得
- Convoyからバックアップコマンド発行
- 指定した領域にバックアップデータを取得
バックアップを行うためには、スナップショットを取得してからバックアップファイルを作成する必要がある点に注意したい。
Convoyを利用したリストア
convoyコマンドで取得したバックアップデータを用いてリストアを行う。厳密に言えばConvoyのリストアは、バックアップデータを別のConvoyストレージにコピーする所までである。
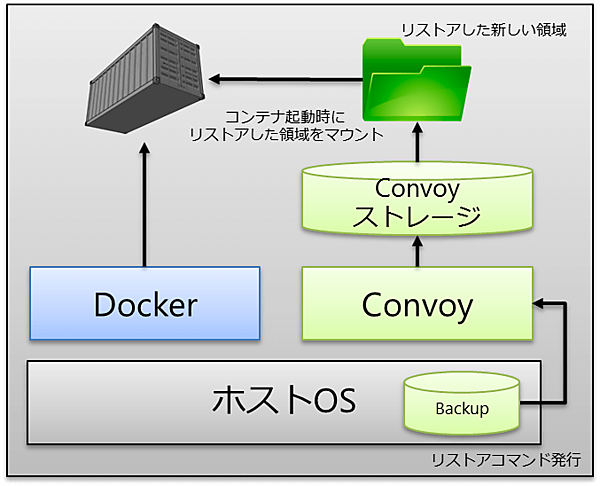
リストア時の挙動は以下の通りだ。
- Convoyのリストアコマンドを発行
- バックアップデータから新しいConvoy領域を作成
- Dockerコマンドでリストアした領域をマウントしてコンテナ起動
Convoyは、あくまでもデータバックアップを行うツールなので、Dockerコンテナ自体は別途用意する必要がある。
Convoyの基本的なオプション
| オプション | 説明 |
|---|---|
| deamon | Convoyのデーモンを起動する |
| info | Convoyの設定状況を表示する |
| create | 新規ボリュームの作成 |
| delete | ボリュームの削除 |
| mount | ボリュームのマウント |
| umount | ボリュームのアンマウント |
| list | Convoyが管理している全てのボリュームを表示 |
| inspect | 指定したボリュームの詳細を表示 |
| snapshot | スナップショットの操作 |
| backup | バックアップの操作 |
| help | ヘルプの表示 |
Convoyのオプションは、現状このくらいだろう。独自のコマンドを用いてはいるが、Convoy自体がシンプルな思想と仕様になっており、学習コストもそれほど高くないと考える。
Convoyの導入
では実際にConvoyを導入し、バックアップとリストアまでをConvoyのチュートリアルに沿いながら解説する。本解説は基本的にはConvoyのQuick Start Guideを参考にしている。参考:https://github.com/rancher/convoy#quick-start-guide
実施環境
今回は以下の環境で検証を行った。なお本記事ではCentOSとDockerは導入済みと想定し、導入手順の解説は行わない。
| 利用ソフトウェア | バージョン |
|---|---|
| CentOS | v7.2 |
| Docker | v1.9.1 |
| Convoy | v0.4.1 |
執筆時点(2016年1月)のConvoyの最新バージョンはv0.4.2rc1だが、本記事ではrc版ではなくリリース版を利用する。記事公開時点ではDocker1.10.3、Convoy0.5.0がリリースされているので、ご留意願いたい。※作業は全てrootで行うものとする
Convoyのダウンロード
# wget https://github.com/rancher/convoy/releases/download/v0.4.1/convoy.tar.gz
展開とDockerとの関連付け
# tar xvf convoy.tar.gz
# cp convoy/convoy convoy/convoy-pdata_tools /usr/local/bin/
# mkdir -p /etc/docker/plugins/
# bash -c 'echo "unix:///var/run/convoy/convoy.sock" > /etc/docker/plugins/convoy.spec'
Convoyが利用するボリュームとメタボリュームの作成と設定
# truncate -s 10G data.vol
# truncate -s 1G metadata.vol
# losetup /dev/loop5 data.vol
# losetup /dev/loop6 metadata.vol
Convoyのデーモンを起動
デーモン起動時に、利用するストレージドライバを指定する。今回はdevicemapperを利用するが、Convoyは様々な形式をサポートしている、今後の拡張性を考慮しているのだろう。
# convoy daemon --drivers devicemapper --driver-opts dm.datadev=/dev/loop5 --driver-opts dm.metadatadev=/dev/loop6 &
ここまででConvoyの導入は完了だ。
Convoyを利用したバックアップ/リストアの実際
バックアップ
まず、バックアップの対象となるコンテナを作成する。コンテナ作成時のオプションに「--volume-driver=convoy」を指定することで、Convoyと連携されたdevicemapperのストレージドライバが利用される。同時に、Convoyのプラグインが対象のコンテナ専用のシンプロビジョニング領域を作成してくれる。
# docker run -it -v vol1:/vol1 --volume-driver=convoy --name=test01 --hostname=test01 centos /bin/bash
起動後に、マウント先である「/vol1」を確認してみよう。
[root@test01 /]# ls -l /vol1/
total 16
drwx------ 2 root root 16384 Jan 20 04:38 lost+found
またテストのためにファイルを作成し、文字を書き込んでみる。
[root@test01 /]# echo "aaa" > /vol1/backuptest
[root@test01 /]# cat /vol1/backuptest
aaa
Convoyが提供しているconvoyコマンドを利用して、コンテナにマウントしたストレージのスナップショットを取得する。
# convoy snapshot create vol1 --name snap1vol1
次にバックアップを保管するディレクトリを作成し、convoyコマンドを用いてスナップショット(snap1vol1)からバックアップを取得する。以下の例ではローカルディレクトリ(/opt/convoy)に取得しているが、AWS S3などにも対応しているためバックアップデータの機密性によって使い分けると良いだろう。
# mkdir -p /opt/convoy/
# convoy backup create snap1vol1 --dest vfs:///opt/convoy/
たとえばS3上へバックアップを行いたい場合には、下記のように指定する。
# convoy backup create snap1vol1 --dest s3://backup-bucket@us-west-2/
先ほどの例と異なる点は、保存先に指定するURLのみである。非常にシンプルでわかりやすい。
リストア
上記で取得したバックアップデータを用いて、今度はリストアを行ってみよう。convoyコマンドを用いて現在存在しているバックアップの一覧を表示する。
リストアに必要な情報は、リストアしたいデータの「BackupURL」だ。以下の例ではconvoyコマンド実行後に、grepで抽出している。
# convoy backup list vfs:///opt/convoy/ | grep BackupURL
"BackupURL": "vfs:///opt/convoy/?backup=6c5742f3-3fb7-4c5b-9081-bd271a3836df\u0026volume=02ef1725-e734-4fc4-ba19-3d8dd37aa9be",
バックアップの一覧からリストアしたいデータを選び、そのBackupURLを用いてConvoyの中に新しい領域を作成する。
# convoy create res1 --backup vfs:///opt/convoy/?backup=6c5742f3-3fb7-4c5b-9081-bd271a3836df\u0026volume=02ef1725-e734-4fc4-ba19-3d8dd37aa9be
先の手順で作成した領域を指定して、新たにコンテナを作成する。
# docker run -it -v res1:/res1 --volume-driver=convoy --name=test02 --hostname=test02 centos /bin/bash
コンテナの中を確認し、データが復元できていればリストアは成功である。
[root@test02 /]# cat /res1/backuptest
aaa
Convoyの価値とは
ここまでConvoyの基本チュートリアルを行ったわけだが、いかがだったろうか? Dockerの標準機能では行えない部分をうまく実装しており、加えてシンプルな利用方法で簡単に使えることがわかるだろう。まとめとして、Convoyの価値やメリット/デメリットについて少し触れていく。
メリット
Convoyのメリットとしては、以下の項目が挙げられる。
- ストレージドライバの追加
- シンプロビジョニング形式の領域作成による不要領域の削減
- 運用上起こり得るホストOS側の汚染の回避
- 一貫されたバックアップとリストア
- ハイブリット環境に対応したバックアップ
Convoyではストレージドライバを追加することによって、「コンテナに保存領域を付与する時にホストOSのディレクトリを用意する」という工程が省ける。すなわち、ホストOSが不特定多数のユーザによって汚されないことを意味する。さらにバックアップ/リストアも専用のコマンドが用意されているので、シンプルに実施できる。=== デメリット
一方Convoyのデメリットとしては、以下が挙げられる。
- ストレージドライバの追加
- リストア時にコンテナの新規作成が必須
「ストレージドライバの追加」についてはメリットとしても挙げたが、同時にデメリットにもなると考えている。すなわちストレージドライバとバックアップのツールロックインだ。もちろんガチガチにロックされているわけではないので、そこまで心配する必要はないが、汎用的な使い方に比べれば自由度が下がるのは確かだ。
また次に挙げた「リストア時にコンテナの新規作成が必須」となる仕様だが、これだけは早い段階でなんとかしていただきたい。既存のコンテナにリストアデータをアタッチやデタッチ出来るようになると、理想的なツールとなるだろう。
最後に
Dockerは2014年から2015年にかけて機能を増やし、洗練してきた。Dockerにはより良いアプリ実行環境となる可能性があり、それを助けるオーバーレイネットワークやタスクシステム、マルチホストでの利用等様々な周辺ツールもあるのだ。 現在はまだ少ないが、実際の業務でDockerを活用し始めた例もある。
こうなると冒頭にも述べたように、今後はDocker運用を考えなくてはならない、2016年は、Dockerの運用も踏まえ仕組みを考えていきたい。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
