Lightbend Reactive Platformによるリアクティブシステムの構築
「リアクティブ」なシステムを構築するための統合プラットフォーム「Lightbend Reactive Platform」を用いたプログラミングを紹介します。
2016年5月30日 1:38
前回は、リアクティブ宣言(Reactive Manifesto)の内容を中心に「リアクティブシステム」とは何かを紹介しました。では、どうすればこのリアクティブシステムを構築することができるのでしょうか? 今回は、JVM上で動くリアクティブシステムを作るためのプラットフォーム「Lightbend Reactive Platform」を紹介します。Lightbend Reactive Platformは、リアクティブシステムの構築においてリーディングカンパニーであるLightbend社が提供するプラットフォームです。Lightbend Reactive Platformを使って、「高レスポンス(Responsive)」「伸縮性(Elastic)」「耐障害性(Resilient)」「メッセージ駆動(Message-Driven)」を備えたシステムの構築をどのように実現するのかを解説していきたいと思います。
Lightbend Reactive Platform
リアクティブ宣言に書かれているようなリアクティブシステムの構築方法は様々ですが、Lightbend Reactive Platformを使用することで構築のハードルをぐっと下げることができます。
Lightbend Reactive Platformは、リアクティブアプリケーションのための統合プラットフォームです。
Play Framework、Akka、LagomなどLightbend社が開発しているフレームワークやライブラリを中心に、リアクティブシステムを開発するために必要な多数のプロダクト群によって構成されています。このプラットフォームを利用して開発する際のプログラミング言語は、ScalaまたはJavaを使用し、構築したアプリケーションはJVM上で動作します。
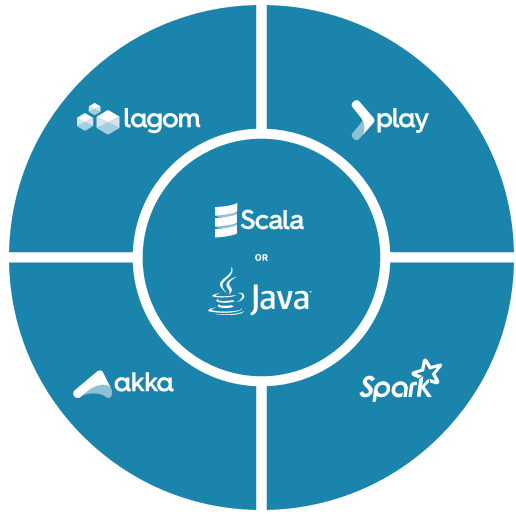
図1:Lightbend Reactive Platform
当プラットフォームの機能は「Community Projects」としてOSS公開されているものと、「Reactive Platform」の一部としてLightbend社のサブスクリプションを購入することによってプロダクション環境で利用できるものの2種類に分けられます。
Play Framework、Akka、Scala、Java、Activator、sbt、Apache Spark、Lagomといった主要プロダクトはCommunity Projectsに含まれます。一方、リアクティブシステムのモニタリングツールである「Lightbend Monitoring」や、オーケストレーションツールである「ConductR」などは、Reactive Platformに含まれます。
表1
| 種別 | プロダクト |
|---|---|
| Community Projects(無償) | Play Framework、Akka、Scala、Java、Activator、sbt、Apache Spark、Lagomなど |
| Reactive Platform(要サブスクリプション) | Lightbend Monitoring、Lightbend ConductRなど |
※執筆(2016年5月)時点。最新情報はLightbend社のサイトにて確認できます。
Reactive Platfromをプロダクション環境で利用するには、Lightbend社のサブスクリプションを購入する必要がありますが、開発環境では、Lightbend.comでアカウント登録さえしておけば、開発者ライセンスIDを取得し、利用することができます。
Community ProjectsとReactive Platformの大きな違いは、利用できる機能の差以外に、Reactive Platformは「認定ビルド(Certified Build)」として提供されているという点があります。通常、いずれかのプロダクトに不具合が見つかると、当然バグフィックスがリリースされるわけですが、そのバグフィックス版は利用者が個別にアップグレードし、自ら他のプロダクトとの整合性を維持していく必要があります。しかしReactive Platformでは、バグフィックス版のプロダクトも他のプロダクトとの整合性が取られており、動作保証された状態で提供されることになります。
Reactive Platform(要サブスクリプション)の詳細は別の回で紹介するとして、今回はLightbend Reactive Platformとして提供されるプロダクトの中核となるPlay FrameworkとAkkaに加え、DBMSを利用するアプリケーションの構築には欠かせないデータベースアクセスフレームワークSlickを順に解説していきます。
Play Framework
Play Frameworkはサーブレットを利用せず、代わりにNettyをベースに実装されたWebアプリケーションフレームワークです(Nettyは、非同期でイベント駆動のネットワークアプリケーションフレームワークです)。Play Frameworkは、以下のような特徴を備えています。
- 非同期、ノンブロッキング
- Nettyの組み込み
- ステートレス
- ScalaとJavaに対応
Play Frameworkは主にScalaで実装されていますが、Scalaだけでなく、Javaからも利用できます。スクリプト言語のような開発容易性を備え、Ruby on Railsのようなテンポの良い開発をもたらしてくれます。
また、これまでのWebアプリケーションの多くで採用されていたサーブレットは使用せず、Nettyをベースとして実装されているため、Webコンテナを用意する必要がありません。そして、リアクティブシステムには欠かせない非同期、ノンブロッキングという特徴を持っています。
Akka
Akkaは、並行・分散処理ランタイムで以下に示すような特徴を備えます。
- Actorモデル
- 障害制御
- 位置透過性(Location Transparency)
- ScalaとJavaに対応
Actorモデルは「全てのものはActorである」という基本理念をベースに、Actor同士がメッセージパッシングでやり取りを行うモデルです。

図2:Actorモデル
メッセージを送信したActorは、応答が戻るのを待つことなく次の作業を行い、メッセージを受信したActorは、自分のメールボックスにあるメッセージをただひたすら処理していくというモデルで、並列性を持つことが特徴です。
Actorは1つだけの存在では価値はなく、親子関係を持ち、ヒエラルキーを構成します。親Actorが子Actorを監視しエラー制御を行うことで、監視するヒエラルキーの外部にエラーを波及させず、障害を最小限に抑えるという障害制御の仕組みを備えます。
そして、Actorの追加・削除によりスケールアウト・スケールインが容易にできます。さらにメッセージの送信先となるActorは、同じJVM上にいても、別のJVM上であっても、同じようにメッセージを送ることができるという位置透過性を持っています。
AkkaもPlay Frameworkと同様に、ScalaとJavaの両言語に対応しています。
Slick
Slickは、Scalaのデータベースアクセスライブラリで、以下に示した特徴を備えます。
- Functional Relational Mapping(FRM)ライブラリ
- Scalaのコレクションを扱うような操作性
- 非同期なデータベースアクセス
Slickにより、データベースクエリの記述をScalaのコレクションを扱うように操作することができます。また、それぞれのデータベースアクセスを非同期の実行が可能で、クエリを発行した際にその結果が返ってくるのを持つことなく、次の処理に移ることができます。
Slickはおおよその主要データベースをサポートしており、現バージョンではOracle、DB2、Microsoft SQL Serverを利用する場合は、Lightbendサブスクリプションが必要になりますが、次バージョンよりライセンスが変更となり、これらのDBMSへアクセスするドライバもオープンソースとして利用できるようになる予定です。
表2:Slickがサポートするデータベース
| Slick(無償) | Slick Extentions(要サブスクリプション) |
|---|---|
| PostgreSQL、MySQL、H2、HSQLDB/HyperSQL、SQLite、Derby/JavaDB | Oracle、DB2、Microsoft SQL Server |
ノンブロッキングなWebアプリケーションフレームワーク「Play Framework」、並行・分散処理の「Akka」、非同期なデータベース・アクセスライブラリ「Slick」。これら3つは、Lightbend Reactive Platformの主要なコンポーネントであり、JVM上でリアクティブシステムを実現するためのそれぞれの役割はご理解いただけましたでしょうか?
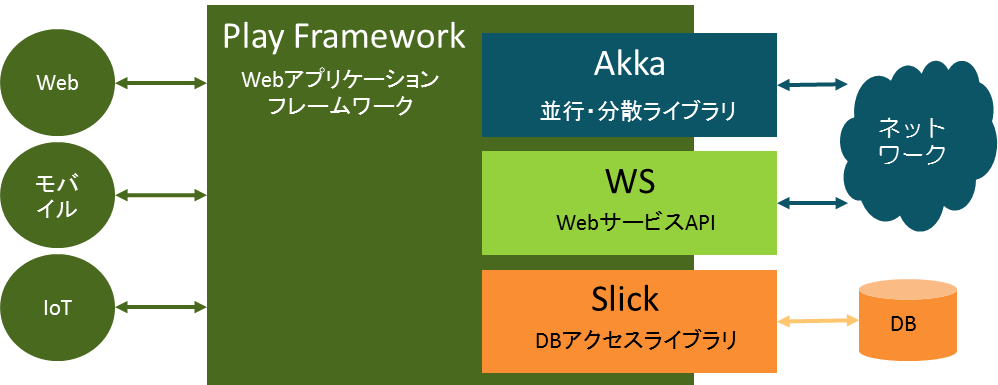
図3:Lightbend Reactive Platformを構成するPlay Framework、Akka、Slick
それぞれの詳細な内容に移る前に、Lightbend Reactive Platformが提供する、その他の主なプロダクトをいくつか紹介しておきます。
Scala
Lightbend Reactive Platform上でアプリケーションを開発する際には、プログラミング言語としてScalaかJavaを利用します。Play Framework、Akka、SlickがいずれもScalaで実装されていることもあり、Lightbend Reactive Platformと最も親和性が高いのが、このScalaです。Scalaは従来のオブジェクト指向スタイルに加えて、関数型プログラミングをサポートするハイブリッド言語です。イミュータブルデータを重視し、副作用を持たない関数を組み合わせることによりロジックを組み立てるため、並列処理を容易に実装できます。つまり、メニーコアを活用するスケールしやすいコードを、より簡潔に、よりエレガントに実装できるのです。また、Javaとは互いのAPIを呼び出すことができるため、Javaの資産を活用できるのも特徴と言えます。
Activator
Activatorは、Play FrameworkやAkkaなどLightbend Reactive Platformのプロダクトを利用して開発する際の開発支援ツールです。Lightbend社のWebサイト上では400を超えるテンプレートが提供されており、開発者は構築するシステムにあったテンプレートをベースに開発を進められます。テンプレートにはプロジェクトのひな形に加えて、チュートリアル(利用ガイド)も合わせて提供されており、初心者でもLightbend Reactive Platformを気軽に体験できます。また、UIはWebブラウザとコマンドラインの2種類が提供されています。
sbt
sbtはインタラクティブなScalaのビルドツールで、ビルドやテストをはじめとした様々なタスクをコマンドラインから実行できます。sbtはActivatorにも内包されています。
Lagom
Lagomは、マイクロサービスベースのシステムを構築するためのフレームワークです。サービスインターフェースの定義と実装方法を提供するサービスAPIと、データを保管する必要のあるサービスのためにイベントソースの永続化エンティティを提供し、CQRSのリードサイドもサポートする永続化APIを備えています。また、1つのコマンドでサービスを実行できる開発環境とConductRによる本番環境のデプロイ、モニタリング、スケールをサポートしています。
Apache Spark
Apache Sparkは、オンメモリデータ処理によって大量のデータを高速に処理できる分散処理基盤です。Spark Coreをベースに、SQL処理のためのSpark SQL、ストリーム処理のためのSpark Streaming、機械学習のためのMLlib、グラフ処理のためのGraphXなどで構成されています。
それでは、ここからはそれぞれが実現するリアクティブな世界をもう少し詳しく解説していきます。
Play Frameworkのリアクティブ
Play Frameworkの基本的な構成は、Model、View、ControllerによるMVCのアーキテクチャです。Routerに、URLと呼びだされた時に実行するアクションメソッドのペアを定義します(図4)。Controllerにはアクションメソッドを定義し、ViewはTwilと呼ばれるテンプレートエンジンを使用して実装することができます。さらにアプリケーションで扱うデータは、Modelで管理します。
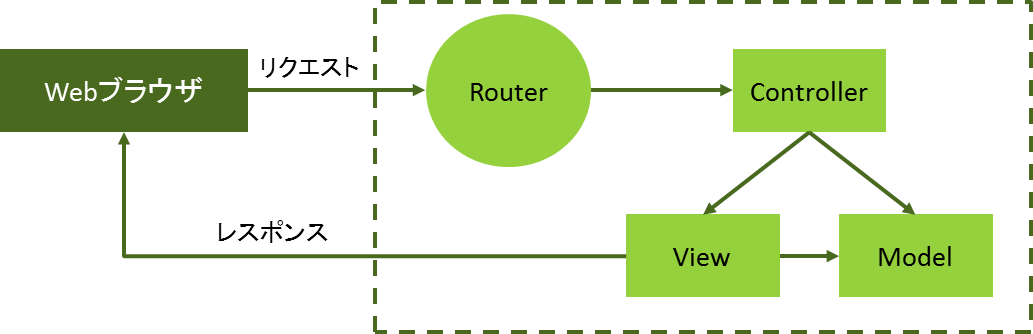
図4:Play FrameworkのMVCモデル
Play Frameworkの特徴を知るためにまず注目すべきは、サーバがクライアントからのリクエストを受け付ける部分です。その特徴である「ノンブロッキングなシステム」とはどういったシステムなのでしょうか。ノンブロッキングを知るために、対語となる「ブロッキング」はどういった仕組みかをお話します。文字通り、クライアントからサーバへのリクエストがブロッキングされています。

図5:「ブロッキング」なシステムとは?
わかりやすくするために、簡単なメタファを用いてブロッキングとノンブロッキングの違いを説明しておきましょう。
行列のできる「ブロッキングカフェ」というコーヒーショップで、コーヒーを注文するとします。ブロッキングカフェにはレジが2台あり、お客様の長い列ができています。順番が来たお客様は、次のような流れでレジでコーヒーを注文します。
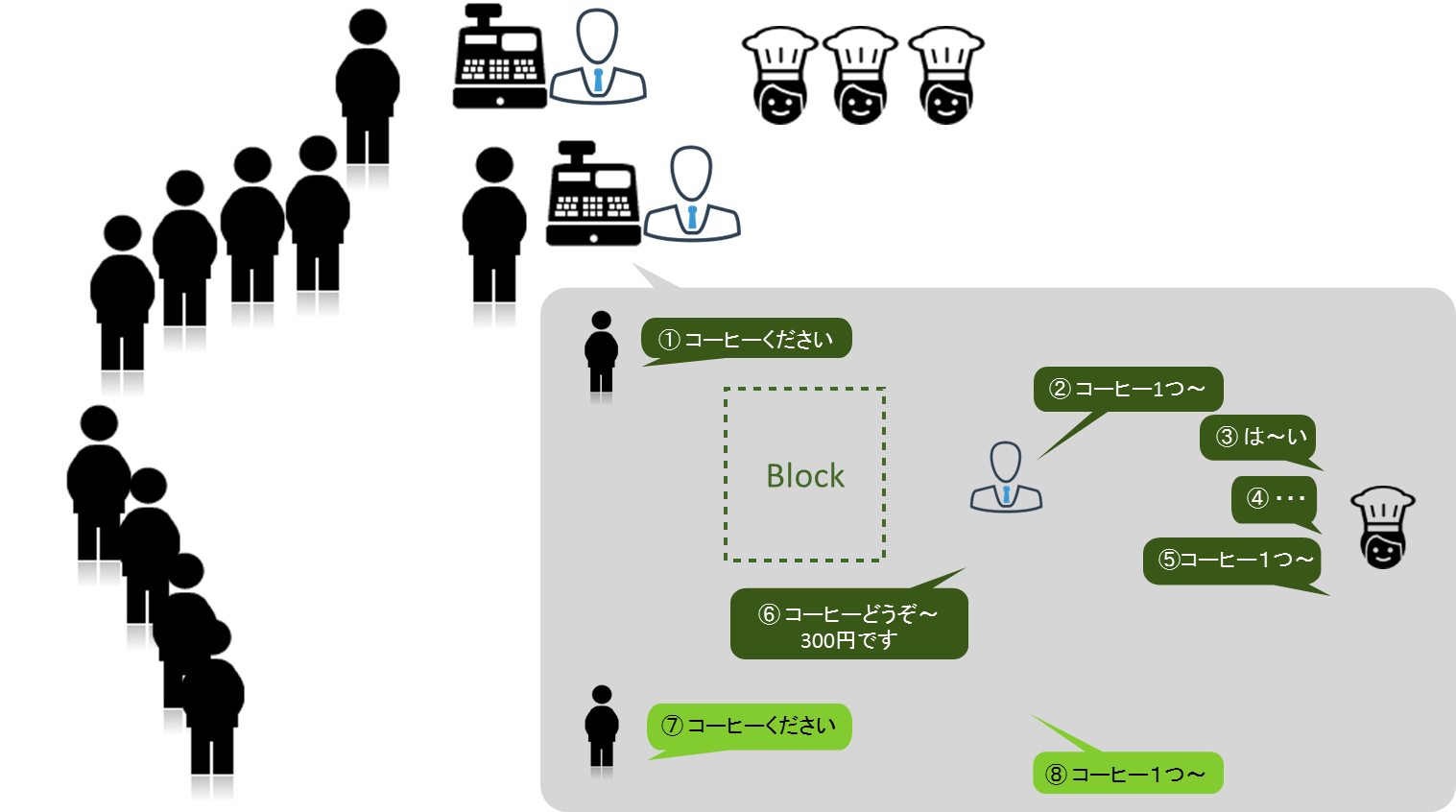
図6:レスポンスが低いブロッキングカフェ
ここでのポイントは、緑色の破線で囲まれている「Block」の部分です。厨房がコーヒーをドリップしている間、レジ係とお客様はコーヒーが出来上がるのをただ待つだけです。
これをシステムに置き換えてみましょう。お客様はリクエスト、レジ係はスレッド、厨房の作業はI/Oに相当します。I/O処理の間、リクエストはブロックされ、スレッドはアイドル状態になっています。これがいわゆるブロッキングされている状態であり、まったく高レスポンスとは言えません。
ブロッキングカフェに行列が出来た理由は、人気があったからではなく、ただ店員の作業効率が悪いことによるものでした。行列をなくすためには、レジ係を増やせばよいかもしれませんが、新たな店員を雇うためにはコストも増加してしまいます。では、人気の「ノンブロッキングカフェ」での注文の流れはどうなっているのでしょうか?
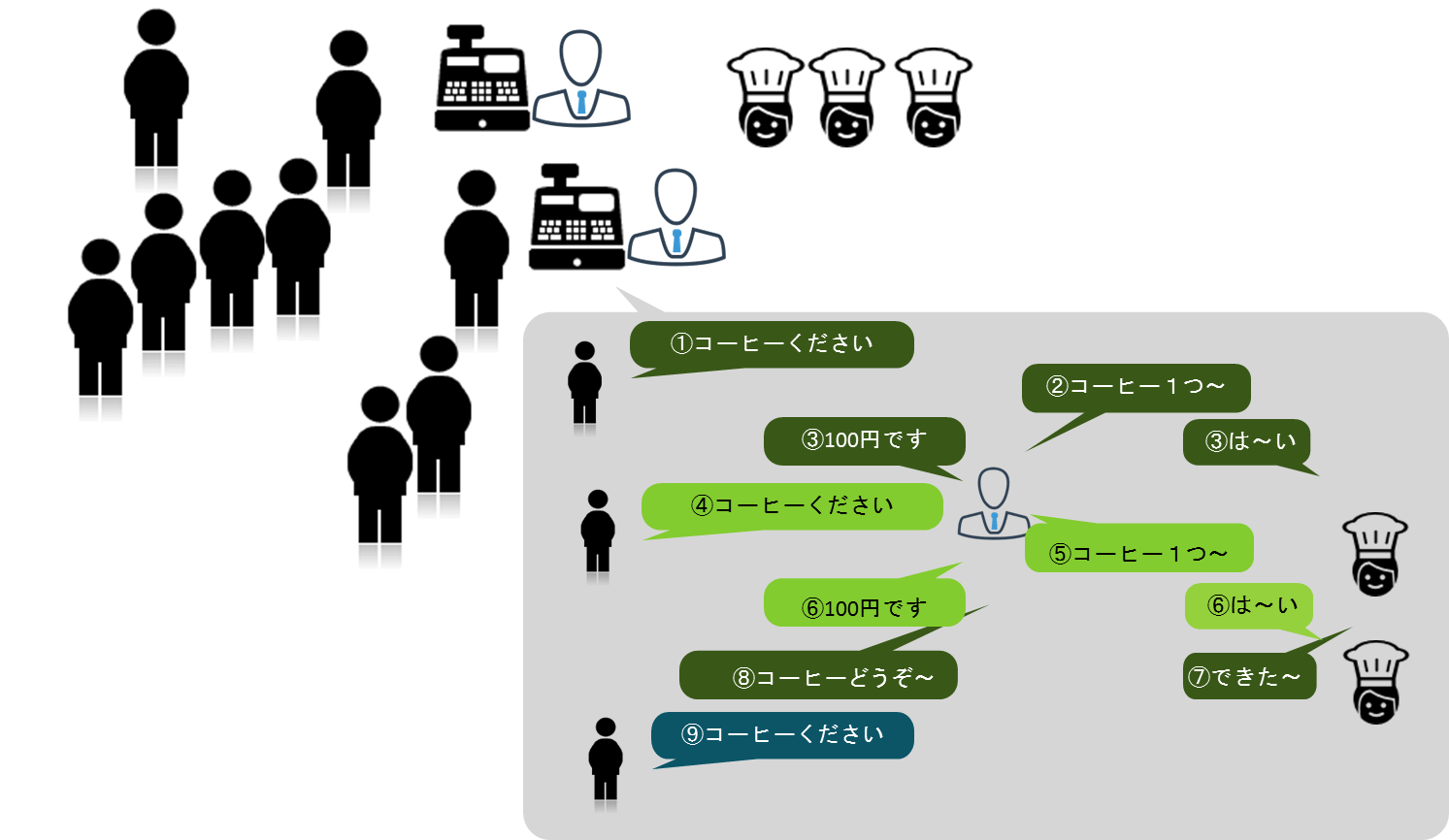
図7:レスポンスが高いノンブロッキングカフェ
こちらでは、図6の「Block」によるレジ係の「コーヒー待ち」がなくなりました。厨房に依頼し、コーヒーが出来上がるまでの間、レジ係はただコーヒーを待つのではなく、次の作業に移っていることがわかります。I/O処理の間もリクエストがブロックされるわけではなく、スレッドを有効活用し次のリクエストを処理しています。これがノンブロッキングです。ブロッキングカフェとノンブロッキングカフェ、作業効率が高いのはどちらでしょうか。レジの数が同じでも、単位時間あたりに受け付けられる注文数は、ノンブロッキングカフェのほうが多くなるのは明白でしょう。同じスレッド数でも同時に捌くことができるリクエストの数がまったく違います。これがノンブロッキングが高レスポンスを実現できる理由です。
トラフィックの高いサイトを実現するためにサーバを複数台並べ、トラフィックが増加した際には、さらにサーバを追加するという方法もありますが、ハードウェアへのコストを惜しまない裕福な企業でない限り、多くの企業は倒産してしまうのではないでしょうか? そこで、ハードウェアリソースを有効活用しハードウェアコストを削減してくれるのが、このノンブロッキングなアーキテクチャなのです。今後デジタルトランスフォーメーションにより爆発的にアクセスが増えることを考えるとこのようなアーキテクチャは欠かせないものとなるでしょう。
Play Frameworkでは、Controllerにアクションメソッドを次のように実装することで、容易にノンブロッキングが実現できます。
以下のアクションはイベント情報を検索し、取得したイベント一覧をレスポンスとして返却します。
リスト1: 通常のHTTPリクエストに対するControllerの実装
def search = Action.async { implicit request =>
// Eventの一覧(Seq[EventRow])をFutureで取得
val future: Future[Seq[EventRow]] = getEvents
future.map { events =>
Ok(views.html.sample.eventSearch(events))
}
}
さらにPlay FrameworkではWebSocketも容易に実装でき、リクエストに対するレスポンスだけでなく、プッシュ型のレスポンスもユーザーに提供します。
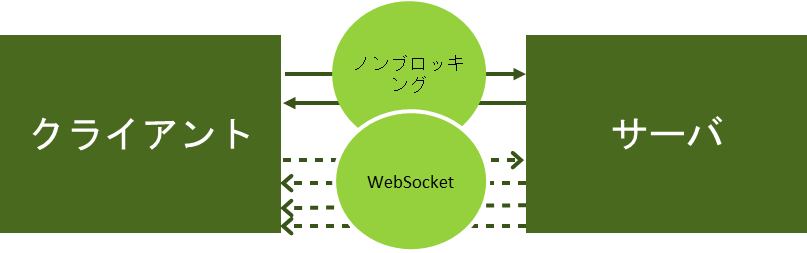
Play FrameworkによるWebSocketの実装
以下は、サーバに送信されたメッセージの内容は無視して「Hello!」という文字列のみをレスポンスするシンプルなアクションメソッドの実装例です。
リスト2: WebSocketリクエストに対するControllerの実装
def hi = WebSocket.using[String] { request =>
// 受信メッセージは無視して、「Hi!」という文字列を返す
val in = Iteratee.ignore[String]
val out = Enumerator("Hi!").andThen(Enumerator.eof)
(in, out)
}
※WebSocket.usingはPlay2.5では非推奨となっています。
AkkaのActorを使うと、Actor(正確にはActorRef)に対してメッセージを送信することで、クライアントに対してレスポンスできます(Akkaについては、次回以降にもう少し解説します)。
リスト3: WebScoketリクエストに対するActorを用いるControllerの実装
def hello = WebSocket.accept[String, String] { request =>
// HelloActorの生成
ActorFlow.actorRef[String, String] { out =>
HelloActor.props(out)
}
}
リスト4: Actor
object HelloActor {
def props(out: ActorRef) = Props(new HelloActor(out))
}
class HelloActor(out: ActorRef) extends Actor {
// Actorがメッセージを受信した時の処理
def receive = {
case msg: String =>
// 「Hello XXX」という文字列を返す
out ! (s"Hello $msg")
}
}
Reactive Slick
データベース・アクセスライブラリのSlickは、バージョン3.0から「Reactive Slick」と呼ばれるようになりました。Reactive Slickは、データベース処理を非同期に実行することができます。DBIOActionを実行し、run()メソッドによりその結果を得ます。run()が呼ばれるとデータベース処理は非同期に実行され、その結果はFutureに包まれて返ってきます。
Futureを受け取った開発者は、非同期に別の処理を実装したり、あるいは、処理の応答を待ってデータベースからの結果を利用した処理を実装したりと、ケースに応じた実装をしていきます。
リスト5: scala
def search = Action.async { implicit request =>
// コレクションを扱うようにfilterでeventNmが「ScalaMatsuri」のデータのみに絞り込む
val query = Event.filter(_.eventNm === "ScalaMatsuri")
val action = query.result
// db.runを実行するとFutureを返す
val future: Future[Seq[EventRow]] = db.run(action)
// 結果を返す
future.map { events =>
Ok(views.html.sample.eventSearch(events))
}
}
また、Reactive Slickにはストリーミングの結果を返す機能も備えています。データベースからの結果はSlickのパブリッシャーを介して返却され、サブスクライブできます。SlickのパブリッシャーDatabasePublisherは、「Reactive Streams」のPublisherの実装です。第1回でも少し紹介しましたが、Reactive Streamsはノンブロッキングなバックプレッシャーを備えた非同期ストリーム処理の標準を提供するための取り組みであり、Slickのパブリッシャーもこの仕様に準拠しています。
リスト6: scala
// 全Eventの一覧を取得
val query = Event
val action = query.result
// Eventの一覧をDatabasePublisherで取得
val dbPublisher: DatabasePublisher[EventRow] = db.stream(action)
// 全イベント名を出力
dbPublisher.foreach { event =>
println(s"Event name: ${event.eventNm}")
}
Slickを使うことでデータベースの処理結果をFutureで取得でき、データベース処理も非同期に実行できます。アプリケーションの端から端まで非同期で動く、リアクティブアプリケーションを構築することができるのです。
では結果をFutureで取得すると、実装はどのように変わるのでしょうか? 先ほどのコーヒーショップの例で、厨房にコーヒーをオーダーする部分をデータベースへの問い合わせと考えると、出来上がったコーヒー(データベースからの応答結果)は「出来上がったらお客様にお渡しする」ということだけ決めておいて、出来上がりを待たずに会計処理を行うことができます。
データベースへ問い合わせをして、その結果を元に何か処理する場合は、mapコンビネータを使用して次のように実装できます。問い合せの結果が返ってくるまでの間は別の処理を行います。コーヒーが出来上がるまでの間は別の応対をし、出来上がり次第お客様にお渡しするという部分ですね。
リスト7: データベース問い合わせの結果を元に処理を行う(mapコンビネータ)
// 2016/01/30のイベントを取得するクエリ
val query = Event.filter(_.eventDate === Date.valueOf("2016-01-30"))
val action = query.result
// db.runを実行するとFutureを返す
val future: Future[Seq[EventRow]] = db.run(action)
val eventNms: Furure[Seq[String]] = future.map { events =>
// データベースからの応答が返ってきたら実行したい処理を定義
events.map { event =>
// イベント名を出力
println(s"Event name: ${event.eventNm}")
event.eventNm
}
}
// データベースからの応答を待たずに実行したい処理を定義
sendMail()
もし何らかの理由でデータベースアクセス処理の完了を待って、別の処理を行いたい場合、同期処理になるためオススメはしませんが、Await.resultやreadyを使用して応答を待ちます。コーヒーが出来上がるまでの間、待ち続けることになります。
リスト8: データベースの処理が完了したら次の処理を実行
// 2016/01/30のイベントを取得するクエリ
val query = Event.filter(_.eventDate === Date.valueOf("2016-01-30"))
val action = query.result
// db.runを実行するとFutureを返す
val future: Future[Seq[EventRow]] = db.run(action)
// データベースからの応答が返って来るまで(Duration.Inf)待つ
val events = Await.result(future, Duration.Inf)
val eventNms: Seq[String] = events.map { event =>
// イベント名を出力
println(s"Event name: ${event.eventNm}")
event.eventNm
}
// データベースからの応答後に実行したい処理を定義
sendMail(eventNms)
このように、非常に簡単に非同期処理が実装できることがお分かりいただけると思います。これまでは、データベース処理の間、当然のように応答を待ち、同期的に実行されるよう次の処理を実装していたと思います。そして性能問題が発生した際には、並列処理の実装などにより性能改善を試みるという対策を施していたのではないでしょうか?
しかし、Reactive SlickからのレスポンスはFutureで戻るため、次に実装する処理は、その応答が返ってきた未来の処理として実装するのか、応答とは関係なく並列で処理できるように実装するのか、それとも応答を待ってから実行するか、ケースに応じて選択できるようになりました。この仕組みを利用することで、メニーコアを遊ばせずに有効活用するアプリケーションが、自ずと実装することができるのではないでしょうか?
Webサービスの呼び出し
データベース処理だけでなく、サービスの呼び出しも同様です。Play FrameworkのWS APIを使用してサービスを非同期に呼び出します。
リスト9: Webサービスを呼び出すControllerの実装
def search = Action.async { implicit request =>
// Webサービスの呼び出し
val wsRequest: WSRequest = ws.url("http://example.com/")
val future: Future[WSResponse] = wsRequest.get()
future.map { response =>
Ok(response.body).as(HTML)
}
}
いかがでしたでしょうか? 今回はPlay FrameworkとSlickを中心に、Lightbend Reactive Platformで作るリアクティブシステムを紹介しました。次回は、Akkaについて詳しく紹介していきたいと思います。
なお、本記事で紹介したサンプルコードはGitHub上で公開しています。
参考資料:
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
