ウォームスタンバイとの組み合わせ
ウォームスタンバイとの組み合わせ
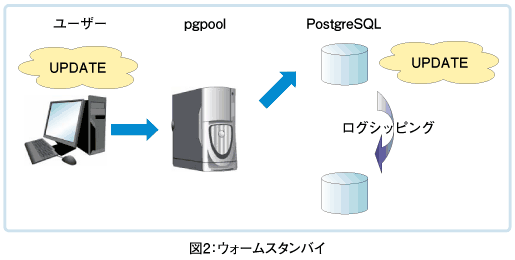
ウォームスタンバイとは、可用性の向上のための機能で、PostgreSQL 8.2で実装されました。PostgreSQLは、データベースに対する変更をWAL(Write Ahead Log)というバイナリログに記録しています。
まず主系のデータベースを待機系にベースバックアップとしてコピーし、その後のこのWALを待機系で次々と再生することによって、主系が故障してしまった場合に素早く代替機を用意することができます。
このウォームスタンバイの機能をpgpool-IIと組み合わせることで、故障の検出から待機系サーバーの起動、そして系の切り替えまでをクライアントが意識することなく自動で行うことができます。
これはちょうど「第4回:非同期レプリケーション!(http://www.thinkit.co.jp/article/98/4/)」で紹介した、Slony-Iとpgpool-IIの組み合わせの構成とよく似ています(Slony-Iとの組み合わせとの違いは後述)。
ウォームスタンバイを構成するには、主系ではpostgresql.confをアーカイブログに出力するよう設定します。
そして、主系のデータベースのある時点での完全なバックアップを待機系にコピーします。これらの手順については、PostgreSQLのドキュメント「高可用性のためのウォームスタンバイ(http://www.postgresql.jp/document/current/html/warm-standby.html)」を確認してください。
待機系の設定
次に、待機系の$PGDATAディレクトリにrecovery.confを設定します。
ウォームスタンバイの待機系は、PostgreSQL 8.3からcontribに収録されているpg_standby
というプログラムを使って、アーカイブされたログの再生を行います。recovery.confは、以下のような設定を行います。
restore_command = 'pg_standby -l -t /path/to/trigger /path/to/archivedir %f %p %r'
pg_standbyの-tオプションはトリガファイルと呼ばれ、pg_standbyに対して主系の故障を知らせるトリガとなるファイルです。このファイルを発見すると、待機系はそれ以上ログファイルの到着を待つのをやめて、通常モードでPostgreSQLを起動します。
ウォームスタンバイとpgpool-IIを組み合わせて使う場合、pgpool-IIが主系の故障を検出した時に、pgpool.confのfailover_commandを使ってpg_standbyのトリガファイルを作成することで、待機系に主系の故障を通知します。pgpool.confのfailover_commandは、以下のような設定を行います。
failover_command = 'ssh [待機系のホスト名] touch /path/to/trigger'
これで、主系の故障を検出した時に待機系の起動を自動で行うことができます。
「第4回:非同期レプリケーション!(http://www.thinkit.co.jp/article/98/4/)」で紹介したSlony-Iとpgpool-IIとの組み合わせと似た機能ですが、両者を比較すると、以下のような違いがあります。
・ウォームスタンバイはPostgreSQLの標準機能であるため、Slony-Iと比べて導入は簡単です。
・ウォームスタンバイは待機系でクエリを実行することはできません。このため負荷分散の目的で使うことはできません。
・ウォームスタンバイもSlony-Iも非同期のレプリケーションですが、通常ウォームスタンバイの方がタイムラグが長くなります。
次はオンラインリカバリについて説明します。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
