オンラインリカバリ
オンラインリカバリ
オンラインリカバリは、pgpool-IIのレプリケーションへの新しいノードを追加や、一度レプリケーションから切り離されてしまったノードをサービスを停止することなく復帰する機能です。これは、pgpool-IIの最も新しい機能の1つで、また以前から要望が多かった機能でもあります。
オンライリカバリを使うと、これらをpgpool-IIを稼働中にpgpoolAdminや、あるいはpcp_recovery_nodeコマンドを使って行うことができます。
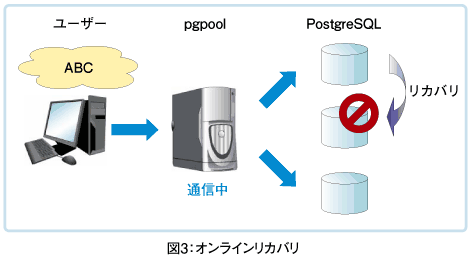
レプリケーションに新なノードの追加を行うには、データベースの状態を完全に一致させなければなりません。これを行うには、データベースインスタンスを丸ごとコピーする必要があります。
しかし、コピーをしている間にデータベースが更新されてしまうと、コピー先との間で不整合が発生してしまいます。かといって、コピーをしている間クライアントからの要求をブロックすると、非常に長い時間クライアントが待たされてしまうことになります。
このため、pgpool-IIのオンラインリカバリでは、リカバリの作業を二段階に分けて実行します。第一段階ではデータベースインスタンスの丸ごとコピーを行いますが、この間クライアントからのクエリは通常通り受け付けます。
第二段階では、新たなクライアントからの要求をブロックし、第一段階でコピーを開始した以降に行われた差分のみを反映させ、新たに追加されたノードを起動します。このようにして、最小限の待ち時間でオンラインリカバリを実現しています。
リカバリの第一段階、第二段階で実際に実行するのは、pgpool.confのrecovery_1st_stage_commandおよびrecovery_2nd_stage_commandで設定したシェルスクリプトとなります。
これらはマスタノードの$PGDATA以下に配置します。また、第二段階終了後に新しいノードを起動するためのスクリプトは、同じくマスタノードの$PGDATA以下にpgpool_remote_restartという名前で配置します。
PostgreSQLのバージョンに応じて、PITRを使ってリカバリを行う方法とrsyncを使ってリカバリを行う方法があります。詳しくはpgpool-IIのドキュメントを確認してください。また、ソースツリーのsampleディレクトリには、リカバリ用のシェルスクリプトのサンプルが収録されていますので、あわせて確認してください。
最後に
本連載では5回にわたってpgpool-IIの活用法を紹介してきました。
2004年にコネクションプーリングサーバーとしてpgpoolのファーストバージョンがリリースされてから、pgpool自体の機能の追加やPostgreSQLの新機能との組み合わせ、Slony-Iなどほかのソリューションとの組み合わせなど、pgpool-IIは活躍するステージを次々と広げてきました。
読者の皆さまにpgpool-IIの可能性を感じていただければ幸いです。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
