本書の読み方のプラン

本書の読み方のプラン
以上で説明した本書の構成や章ごとの難易度をもとに、本書の読み方についてここでは2つのプランを提示します。
●プラン1. 速習コース:最初は関数やクラスを定義してアルゴリズムを記述したり、数式を丁寧に追ったりすることよりも、ライブラリの使用方法を覚え、一通り機械学習を使いこなすことを優先します。Pythonのクラスや数学の知識があまりない場合は、このプランに従って本書を読み進めるとよいと思います。
●プラン2. 特訓コース:関数やクラスを用いたアルゴリズムの記述、数式に抵抗感がない場合はこのプランに従って読み進めるとよいと思います。
以下ではそれぞれのプランについて説明します。
●プラン1. 速習コース
このプランでは、図2に示す順に読み進めていきます。
図2:速習コースのフロー

ここでは、まずはscikit-learnを用いて教師あり学習の分類モデル、その構築、検証方法について一通り学習していきます。3章から7章で、Pythonのクラスや微積分、線形代数の基礎知識が要求される以下の箇所は、初読の際は飛ばしてもよいかもしれません。
◆Pythonのクラスなどにあまりなじみがない場合
4.5.2項「逐次特徴選択アルゴリズム」
5.3.2項「Pythonでカーネル主成分分析を実装する」、5.3.3項「新しいデータ点を射影する」
7.2節「単純な多数決分類器の実装」、7.3節「アンサンブル分類器の評価とチューニング」
◆数学にあまりなじみがない場合
3章の数式による説明
5章の数式による説明
まず3章でscikit-learnを用いて分類の主要なアルゴリズムの概要を理解し、続いて4章でデータの前処理、5章で次元削減、6章でハイパーパラメータのチューニング、モデルの検証等の機械学習のパイプラインについて学習していきます。7章のアンサンブル学習では3.6節で学習する決定木の知識が必要になります。
その後、12章、13章のニューラルネットワーク(多層パーセプトロン)に移行します。これらの章は、最近流行している深層学習(ディープラーニング)を他書で本格的に学ぶための導入的な役割を果たしています。12章を読むにはクラスなどのPythonの基礎知識、数学(微積分、線形代数)を避けては通れません。そのため、先に挙げた参考文献で補強しながら12章の基礎となっている2章を読み、12章に挑むのがよいと思います。
●プラン2. 特訓コース
このプランでは、図3に示す順番で読み進めていきます。
図3:特訓コースのフロー
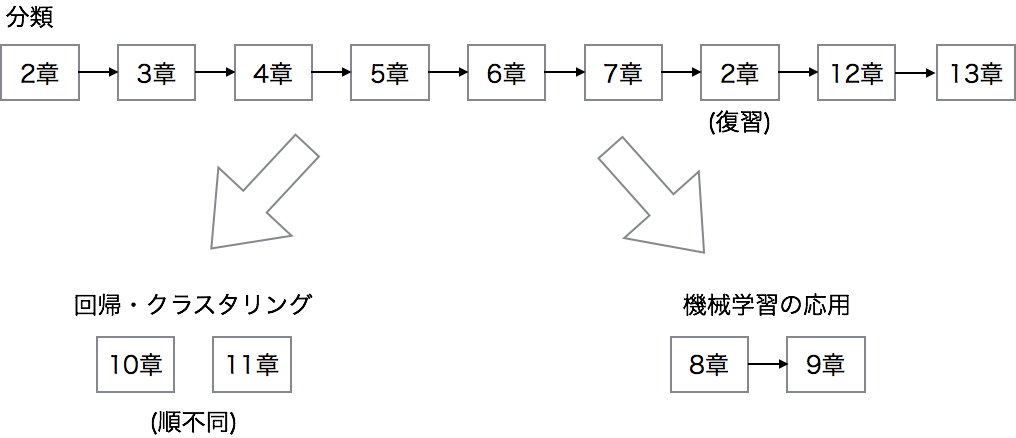
このプランでは、まずは分類について一通り学習していきます。プラン1の速習コースでは2章を飛ばしましたが、ここでは2章から学んでいきます。
分類をひととおり学んだ後は、回帰、クラスタリング、機械学習の応用を興味に合わせて読み進めるとよいでしょう。
本書を読むための環境構築
本書は、実際にコードを実行して結果を確かめながら読み進めていくタイプの書籍です。使用する主要なライブラリを一括で揃えた環境を構築するためには、1.9.1項「Pythonパッケージのインストール」で説明されているようにAnacondaを使用するとよいでしょう。
Windowsを使用している場合は、以下のページからインストーラをダウンロードしインストールします。Python 2系と3系の両方を提供していますが、本書はPython 3系の使用を想定しているので、特に理由がなければ3系を選択するとよいでしょう。
◎Anacondaインストーラのダウンロード先
https://www.continuum.io/downloads
Mac OSやLinuxを使用している場合はpyenvを経由してAnacondaをインストールするとよいでしょう。以下のQiitaの記事に情報がまとまっています。
◎データサイエンティストを目指す人のpython環境構築 2016
http://qiita.com/y__sama/items/5b62d31cb7e6ed50f02c
また、著者はGitHubでソースコードや数式の補足等の資料を提供していますので、必要に応じて使用しましょう。
◎著者による本書のGitHubサイト
https://github.com/rasbt/python-machine-learning-book
これらのソースコードはipynb形式で提供されており、Jupyter Notebookを使用することにより実行できます。Jupyter Notebookを使用すると、ブラウザ上でソースコードを記述、実行し結果を確認する試行錯誤の過程を記録することができます。また、ドキュメント、数式、画像なども含めることができます。なお、Anacondaは、Jupyter Notebookも提供しているのでインストールの作業は不要です。
Jupyter Notebookについては、本書の付録Aに、上記のソースコードを読み込む方法も含めて基本的な使用方法を説明しました。なお、監訳にあたってはJupyter Notebook上でソースコードを打ち込みながら確認を行いました。
本書を読了した後の参考文献
最後に、本書を読了した後の参考文献をいくつか挙げます。
■『実践 機械学習システム』(オライリー・ジャパン、2014年):scikit-learnを用いた豊富な実践例が紹介されており、本書で機械学習の基礎を身につけた後に読むのに適しています。
■『Data Science from Scratch』(Oreilly & Associates Inc, 2015年):本書でもscikit-learnのクラス、関数を使うのではなく、自力でクラスや関数を実装しているケースがいくつかあります。この書籍では、scikit-learnなどを使用せずに、自力で機械学習のアルゴリズムを実装しています。使用されているソースコードがGitHubで公開されているので、参照するのもよいでしょう(https://github.com/joelgrus/data-science-from-scratch)。
■『言語処理のための機械学習入門 (自然言語処理シリーズ)』(コロナ社、2010年):「言語処理のための」と書名にはありますが、数学の基礎知識から始まり、数式を交えて機械学習の基礎を学ぶのに適しています。
■『パターン認識と機械学習 上』(丸善出版、2012年):機械学習の理論面を勉強する場合に是非読みたい一冊です。
以下の3冊は、本書の12章、13章の次に深層学習の理解を深めるために読みたい書籍です。ツール、ライブラリの使用方法も交えて学習したい場合は最後の「イラストで学ぶディープラーニング」を読むとよいでしょう。
■『深層学習 (機械学習プロフェッショナルシリーズ)』(講談社、2015年)
■『深層学習 Deep Learning (監修:人工知能学会)』(近代科学社、2015年)
■『イラストで学ぶ ディープラーニング (KS情報科学専門書)』(講談社、2016年)
 Sebastian Raschka 著/株式会社クイープ 訳/福島 真太朗 監訳 | Python機械学習プログラミング 達人データサイエンティストによる理論と実践機械学習の考え方とPython実装法がわかる! 分類/回帰や深層学習の導入を解説--◎絶妙なバランスで「理論と実践」を展開 ◎Pythonライブラリを使いこなす ◎数式・図・Pythonコードを理解 --機械学習とは、データから学習した結果をもとに、新たなデータに対して判定や予測を行うこと。本書では、機械学習の各理論を端的に解説、Pythonプログラミングによる実装を説明。AIプログラミングの第一歩を踏み出すための一冊です(本書は『Python Machine Learning』の翻訳書です)。
|

