OpenShiftでデータサイエンティストとアプリ開発者が協調する流れをデモを交えて紹介
OpenShift Commonsのセッションから、データサイエンティストとアプリ開発者の連携して開発を進めるデモを紹介する。
2021年10月27日 5:50
Red Hatが主宰するオープンソースコミュニティのオンラインコンテンツから、OpenShift上でデータサイエンティストとアプリケーションデベロッパーが協調する一連の流れを解説した動画を紹介する。これはOpenShift Commonsのコミュニティ向けのコンテンツ「OpenShift Community Briefing」と題されたシリーズの一つで、2021年7月3日にストリーミングで配信されたものだ。
動画:OCB: Integrating Data Science and Application Development - Sophie Watson and Chris Chase (Red Hat)
動画のタイトル「Integrating Data Science and Application Development」というもので、OpenShift上で機械学習のアプリケーションの開発から実装、コードの変更までを一連の流れとしている。その中で機械学習部分を担当するデータサイエンティストと、アプリケーションの開発を担当するデベロッパーが、どのようにワークフローを実行するのかをデモを交えて解説している。単にOpenShiftの上で機械学習のアプリを動かすのではなく、データサイエンティストの領域とアプリケーションデベロッパーの領域を明確に意識しながら、データサイエンティストが作るモデルをアプリケーションデベロッパーが書いたアプリの中でトラブルなく実装していく流れを説明している。

OpenShift Commonsでのセッション
担当したのはデベロッパーのChris Chase氏とデータサイエンティストのSophie Watson氏だ。
注目すべきは、アプリケーションの起動方法を変更しても、データサイエンティストが担当する部分を変える必要はなく、アプリケーションだけを変えてすぐに動き出すという流れを実際にデモとして見せたことだろう。
これはデベロッパーと運用担当者の間で頻繁に発生する「デベロッパーのノートPCでは動いたが、サーバーに配備すると動かない」という問題を、データサイエンティストとアプリケーションデベロッパーに置き換えたものと言って良いだろう。データサイエンティストが作ったモデルとデータを使ってアプリケーションに組み込もうとしても、必ずどこかでエラーが起こるというのは、このコミュニティコールのホストであるDiane Mueller氏も嘆いているぐらいなので、よくある問題なのだろう。
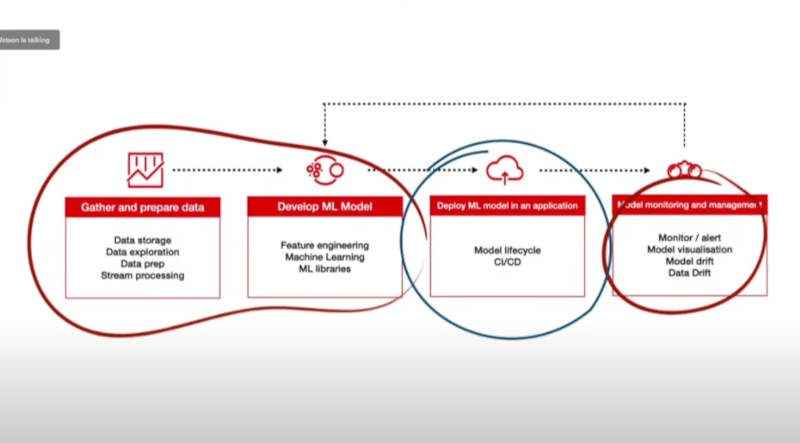
機械学習のワークフローを紹介
最初にWatson氏が、機械学習モデルの開発と実装の流れを紹介した。ここではデータを集めて準備すること、機械学習のモデルを作ること、アプリケーションにそのモデルを実装すること、そしてモデルのモニタリングと可視化を行うこと、以上の4つのステップで紹介している。このうち3番目の実装するフェーズを、アプリケーションデベロッパーが担当するという分担が行われていると解説した。
ただし、実際の実装時にはファイアウォールの内部に置き、開発時の環境からストレージやCPUなどの最適化が行われることになると説明した。
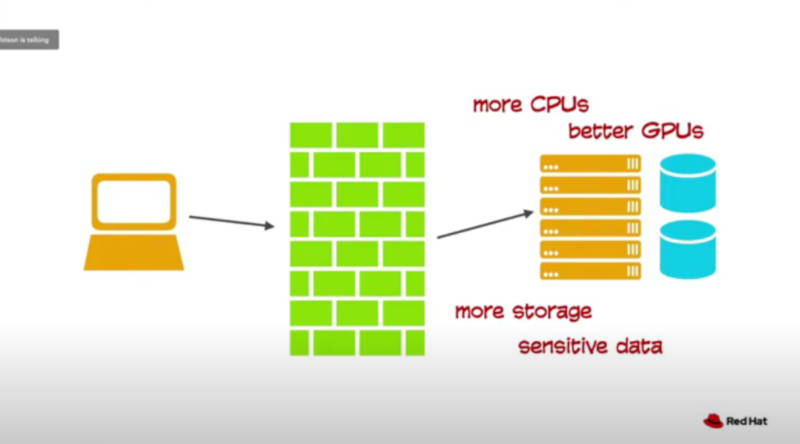
開発環境から運用環境への移行が必要
そしてデータサイエンティストの仕事として、Jupyter Notebookを使ってモデルを作るようすをデモしてみせた。ここでは、データサイエンティストがモデルの作成に専念していることが強調された。
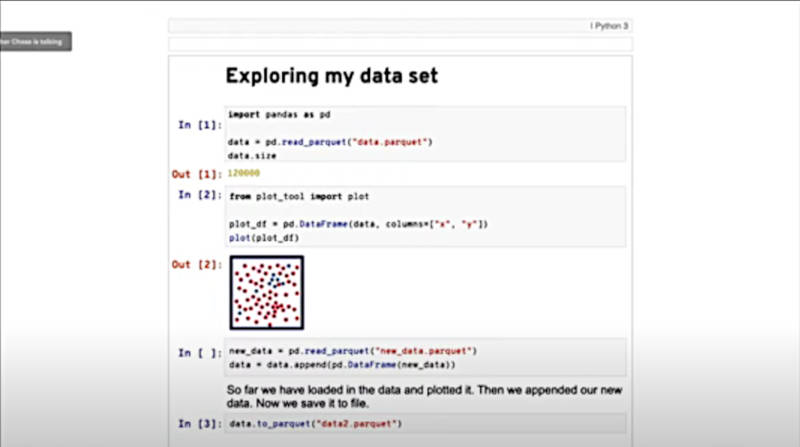
データサイエンティストはJupyter Notebookでモデルを開発
今回は写真から犬を検知するアプリケーションを作るということで、TensorFlow、Numpyなどのライブラリーを利用することになる。プロジェクトとしてはデータサイエンティストがJupyter Notebookを使ってモデルを作成、それを受けてアプリケーションデベロッパーがGit上のPython 3と環境設定を操作してアプリケーションをビルドし、OpenShift上に実装するという流れだ。
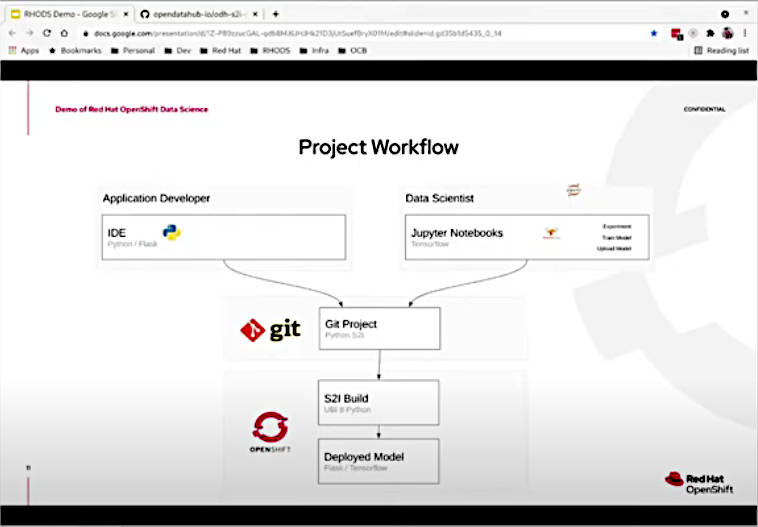
IDEとJupyter Notebookをそれぞれが使用して開発を進める
JupyterHubを使ってモデル実行のためのベースを選択し、サーバーを立ち上げるまでのデモを実施した。
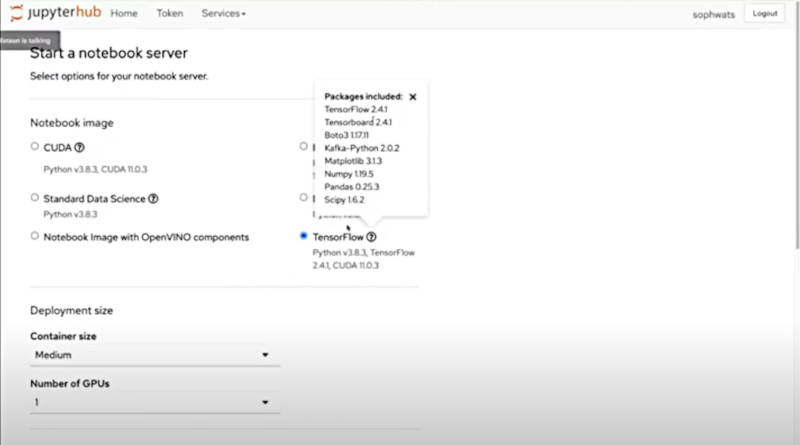
JupyterHubを使ってモデルを開発
操作としてはGitHubに存在するコードをクローンしてJupyterHubにインポートし、その後ノートブックの中でコードを確認しながらイメージ検知のモデルを実装していくという流れだ。
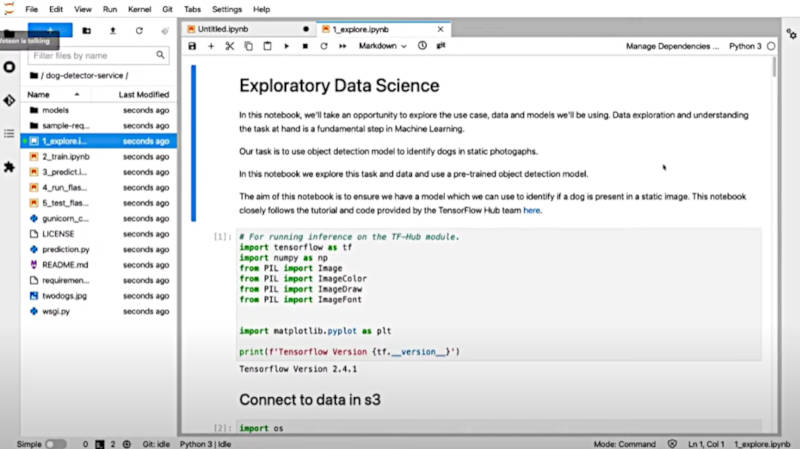
JupyterHubでPythonのコードを記述していく
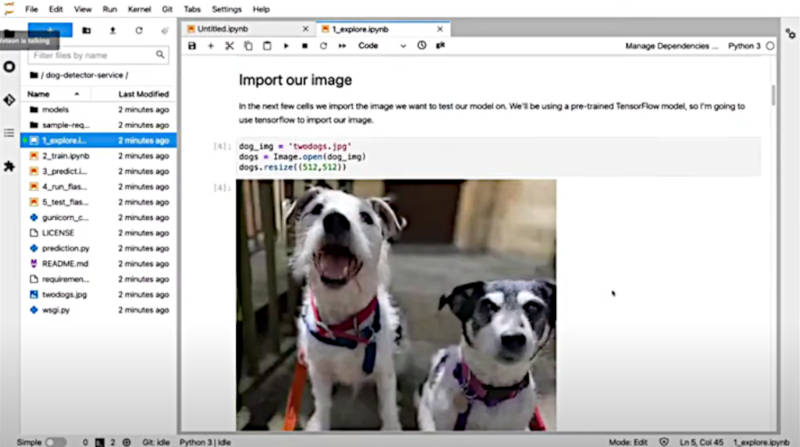
デモ用のイメージデータをロード
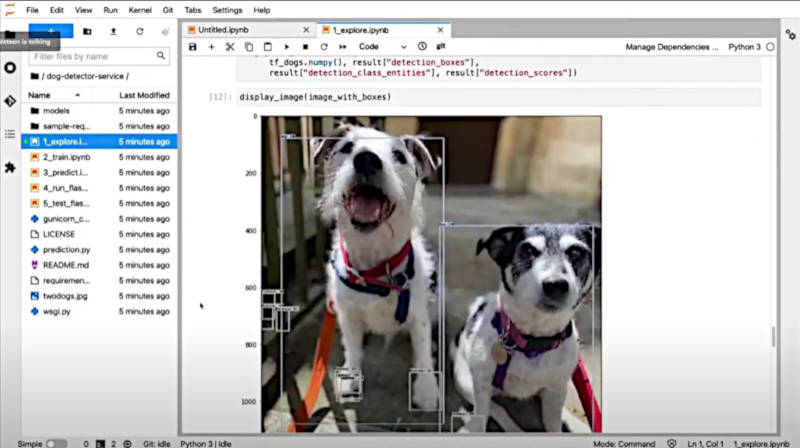
検知された犬を矩形で囲っている
この例では、モデルの中にFootwearを検知できるようなデータの内容になっているようで、犬の足も同時に検知されている。ここからはアプリケーションデベロッパーがモデルをOpenShiftの中にコンテナイメージとしてロードして実行するために、OpenShiftのコンソールから操作を行っている。
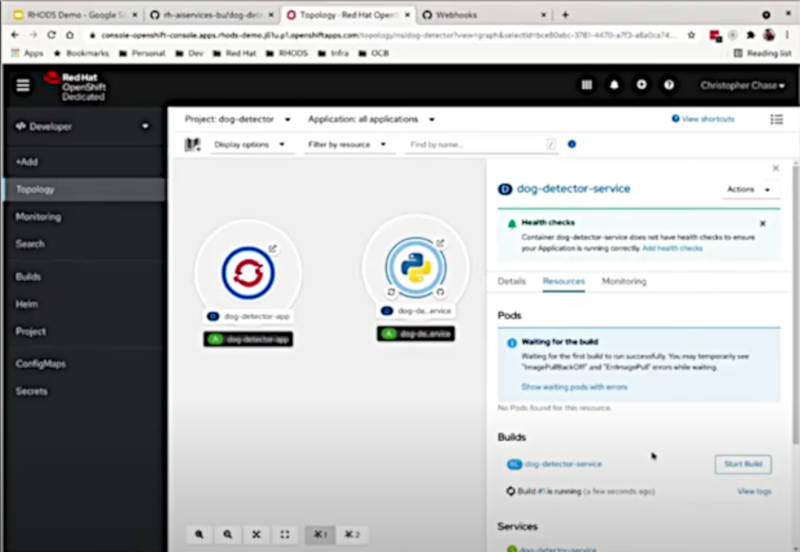
OpenShiftからモデルを実行
ここでページにイメージの表示エリアと検知ボタンを設定して、ボタンが押されるたびに犬が検知されるアプリケーションを実行して、確認を行った。

スマホに表示された犬のデータを認識している
しかし元々の発想はボタンを操作するのではなく、監視カメラ的に使いたいというのがChase氏の意図だったとして、ここからデータサイエンティストが作ったモデルを変えずに、Kafkaのストリーミングを使ってイメージデータを取り込んで認識を行うように変更するようすをデモした。
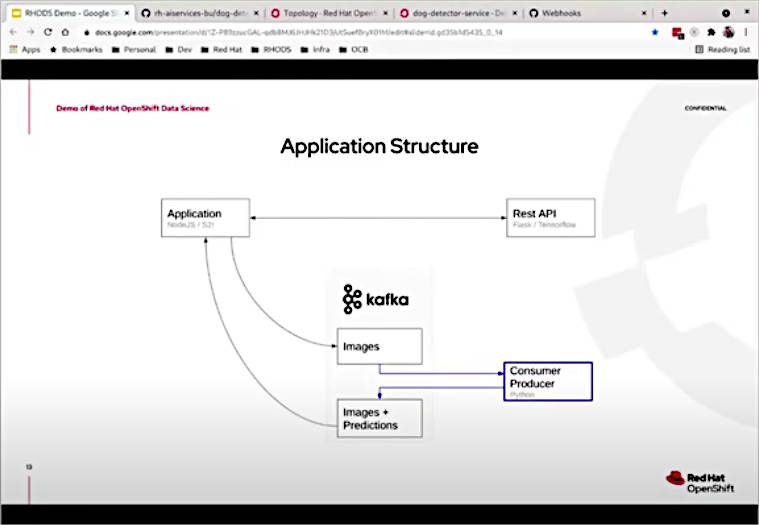
REST APIにKafkaのストリーミングを追加
ここでProducerであるイメージデータの読み込みと、Consumerとしてのイメージ認識を行うコードを追加した。また必要なライブラリーとしてFlaskを外して、Kafka-pythonを追加している。

Kafkaのストリーミングが動いていることをJupyter Notebookで確認
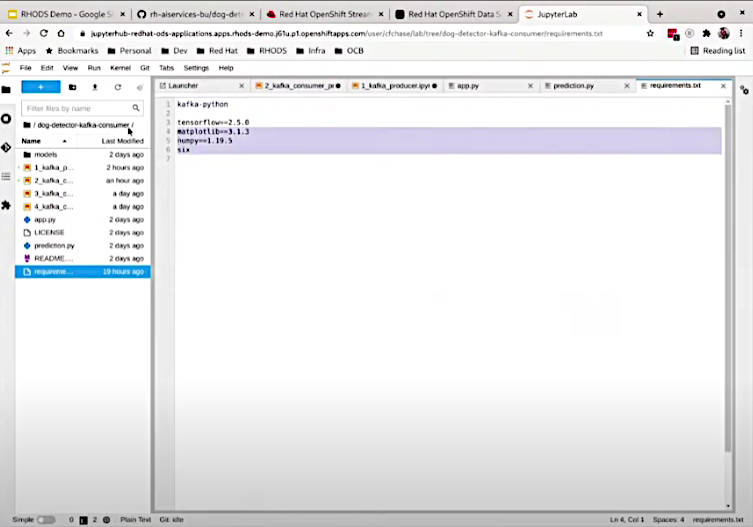
Flaskが外されてKafka-Pythonが追加されている
またデータサイエンティストがモデルの変更などを行った際に、Git経由で変更が通知されるようにWebhookを追加するなど、細かい連携のための作業も行っている。
これで、カメラから取り込まれたイメージを継続的に認識する監視カメラアプリケーションが開発できた。動作試験として、Chase氏が自宅の愛犬を連れてきて実際に認識されるかどうかを試してみせた。
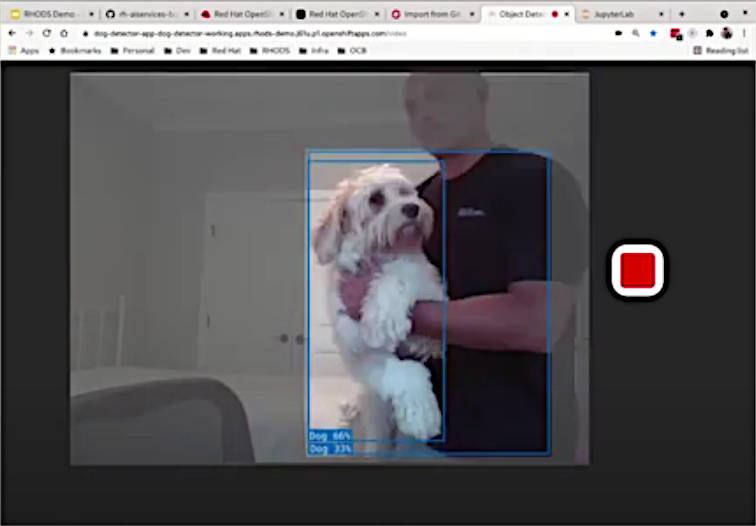
自宅の愛犬を認識させているChase氏
これでデータサイエンティストによるモデルの開発、アプリケーションデベロッパーによる実装、モデルの変更をGit経由で行うワークフロー、モデルを変えずにアプリケーションを変更して行くようすが解説されたことになる。
この後、データサイエンティストが作ったモデルを実際に配備する際に上手く行かないという問題に対しては、アプリケーションの機能をデータサイエンティストとアプリケーションデベロッパーの担当する範囲に切り分けながら、AWS上に展開されたOpenShift Data Scienceが上手く適応できることを説明して、セッションを終えた。
参考:Red Hat OpenShift Data Science
今回、デモに使われたアプリケーションのコードは以下から参照できる。
参考:https://github.com/rh-aiservices-bu/dog-detector-setup
このURLを見ると、Red Hatには人工知能を専門に行う部門が存在していることが推測できる。Red Hatにおける人工知能の応用という意味では、インフラストラクチャーの運用面で使われるRed Hat Insightがルールベースであることを考えると、これからはもっと機械学習を使った機能が増えてくることが予想される。そしてOpenShift上で機械学習のアプリケーション開発が容易であることを、デモを交えて紹介したことで、これまであまりアプリケーション領域には踏み込んでなかったRed Hatが、本気でOpenShiftを展開しようとしていることを感じさせたセッションとなった。
- この記事のキーワード
この記事をシェアしてください
関連記事
Kubernetes上で機械学習のパイプラインを実装するKubeflowを紹介
2021年6月8日 7:12
OpenShift Commons GatheringからMicroShiftとCockroachDBを紹介
2022年9月6日 6:00
KubeCon Europe 2024開催。前日に開催されたAIに特化したミニカンファレンスを紹介
2024年5月9日 6:00
KubeCon North America 2024から、分散アプリのフレームワークNEXを解説するセッションを紹介
2025年4月11日 5:59
Kubernetesクラスターの遠隔操作による開発を支援するTelepresence
2021年5月26日 7:18
IBMとRed Hatが推進するレガシーアプリケーションをKubernetesに移行するためのツールKonveyorを紹介
2022年3月25日 14:05
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
