はじめに
前回は、機械学習の学習データにスポットを当てて解説しました。今回は、もう1つの主役である「アルゴリズム」について解説します。
目的とデータに合ったアルゴリズム
一般に、機械学習では「アルゴリズムよりデータの方が大切」と言われています。確かに、それは我々AIチームでも常に実感しているのですが、良いデータを使ってある程度の認識率を獲得しても、どうしても「もっと良い方法があるのでは」と考えてしまいます。そして、実際に他のアルゴリズムを使ってみて、結果が変わらないこともあれば、結果が良くなることもあります。こうした経験から、やはりアルゴリズムも大切であり、「目的に合ったデータとアルゴリズム」ということを意識する必要があると思っています(図1)。

図1:目的に適したデータとアルゴリズム
機械学習のアルゴリズム
これまで、ニューラルネットワーク(ディープラーニング)のアルゴリズム(CNNやRNNなど)を説明してきましたが、実は機械学習のアルゴリズムは表1のようにたくさんあります。なんでもかんでもディープラーニングが優れているとは限らず、目的と用意できるデータによってはこれらの機械学習アルゴリズムの方が高い精度が得られるのですが、こんなにたくさんあると、どういうときにどのアルゴリズムを使えば良いか迷ってしまいます。
表1:代表的な機械学習アルゴリズム
| 2クラス分類 Two-class classification | ラベル付きデータを学習して2値に分類 ・ロジスティック回帰 Logistic Regression ・ランダムフォレスト Randam(Decision) Forest ・デシジョンジャングル Decison Jungle ・ブースト 決定木 Boosed decision tree ・ニューラルネットワーク Neural network ・平均化パーセプトロン Averaged perceptron ・サポートベクターマシーン Support vector machine(SVM) SVC(線形SVM)、Linear SVC(RBM SVM) ・ローカル詳細SVM Locally deep SVM ・ベイズポイントマシン Bayes point machine 単純ベイズ Naive Bayes |
| マルチ分類 Multi-class classification | ラベル付きデータを学習して3値以上に分類 ・ロジスティック回帰 Logistic Regression ・ランダムフォレスト Randam(Decision) Forest ・デシジョンジャングル Decison Jungle ・ニューラルネットワーク Neural network ・一対全多クラス One-v-all multiclass ・k近傍法 k-nearest neighbors |
| 回帰 Regression | 数値データを学習して数値を予測 ・線形回帰 Linear(Ordinary) Regression ・ベイズ線形回帰 Bayesian Linear Regression ・ランダムフォレスト Randam(Decision) Forest ・ブースト 決定木 Boosed decision tree ・高速フォレスト分布 Fast forest quantile ・ニューラルネットワーク Neural network ・ポアソン回帰 Poisson Regression ・サポートベクトル序数回帰 Ordinal Regression ・リッジ回帰 Ridge Regression ・ラッソ回帰 Lasso Regression ・サポートベクター回帰 SVR ・One Class SVM |
| クラスタ分析 Clustering | 似たデータを集めてデータ構造を発見 ・k-means (k平均法) ・混合ガウス分布 GMM(Gaussian mixture models) ・スペクトラルクラスタリング spectral clustering |
| 次元削減 dimensionality reduction | データの次元を削減してより主要因子を発見 ・主成分分析 PCA ・非負値行列因子分析 NMF ・LDA ・Deep Learning |
| 異常検出 Anomaly Detection | ・サポートベクターマシーン SVM ・PCAによる異常検出 PCA-based anomaly detection ・k平均法 k-means |
実は、機械学習を勉強する人にとっては有名な早わかりマップscikit-learn cheat-sheetがあります(図2)。scikit-learn(サイキット・ラーン)はPythonのオープンソース機械学習ライブラリで、チュートリアルも充実しているためこれを使って機械学習を勉強した人も多いと思います。このマップを見れば、目的と用意できる学習データ量に応じて、どのようなアルゴリズムが良さそうかの道標がひと目でわかります。

図2:scikit-learnのアルゴリズム早わかりマップ
ただし、このマップは2013年に公開されたもので、さすがに登場しているアルゴリズムがちょっと古い感があります。多くのアルゴリズムがその後進化しているので、代わりに重宝するのがマイクロソフトの機械学習サービスMicrosoft Azure Machine Learningのホームページに公開されているAlgorism Cheat Sheetです(図3)。
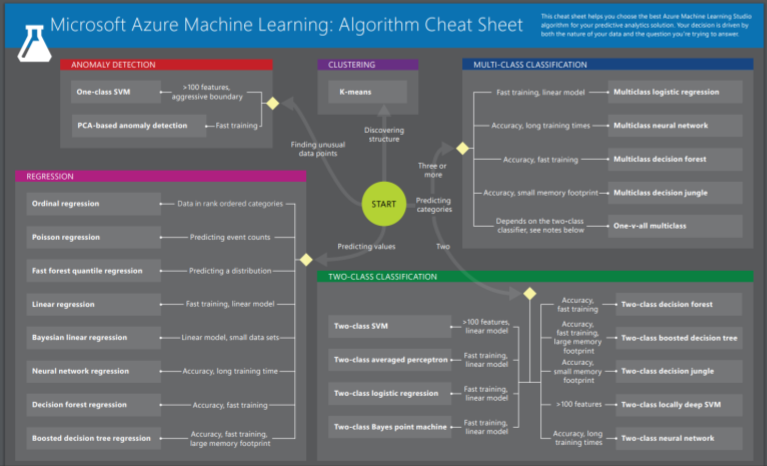
図3:Azure Machine Learningのアルゴリズム早わかりマップ
第3回でMicrosoftの機械学習サービスAzure Machine LearningとディープラーニングのMicrosoft Cognitive Learningの役割分担を説明しました。図3は、このAzure Machine Learningのアルゴリズムを目的別にまとめたもので、scikit-learn cheat-sheetに敬意を払って同じcheat-sheetという言葉(直訳するとカンニングペーパーの意味)を使っています。
図3の中で、Discovering structureはデータ構造を発見するCLUSTERING(クラスタリング)、Finding unusual data pointは異常を検知するANOMALY DETECTION(異常検知)、Predicting categoriesは対象を分類するCLASSIFICATION(分類)、Predicting valuesは値を予測するREGRESSION(回帰)のアルゴリズムが適していると示しています。
これらの分類や回帰、クラスタリングについて、図4をベースに解説しましょう。
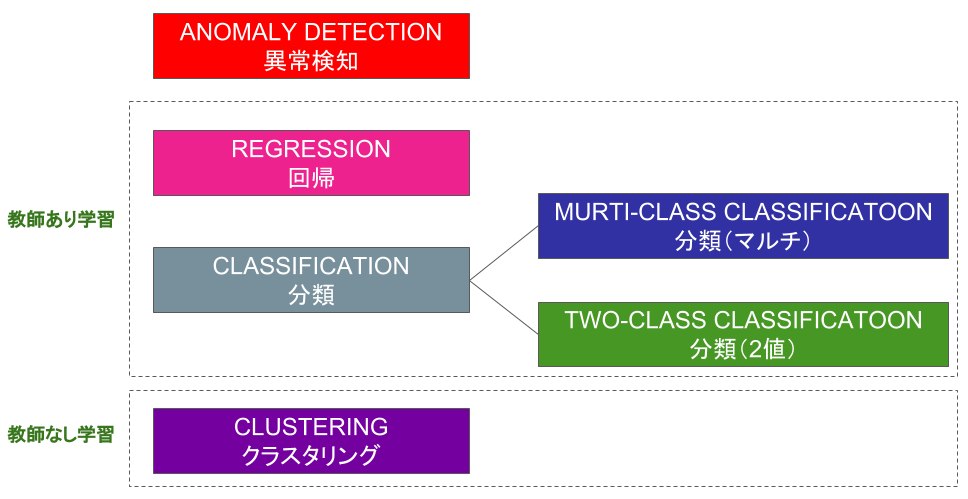
図4:主要なアルゴリズムのカテゴリー
分類(Classification)
分類は、名前の通り「さまざまなオブジェクトを自動分類する」ための手法です。実は、これまでの説明で取り上げた「花の名前を教えてくれるAI」も、このCLLASIFICATION(分類)の手法を使っています。分類は、”教師あり学習”なので、データに”バラ”、”ボタン”というように名前(ラベル)を付けて学習させ、AI(分類器)はそれらの特徴点を見つけて学習して見分ける力を身に着けます。
分類には、複数のカテゴリーに分類するMurti-class classificationと2つに分別するtwo-class classificationがあります。花の名前のようにたくさんの花に分類するのがマルチ分類、異常か正常かを判定する異常検知のようなものが2クラス分類です。
回帰(Regression)
回帰は、ひと言で言うと「これまでの実績データをもとに関連性を導き出し、これからの予測に役立てる」ための手法です。例えば、小売店が来店者数を時間単位で自動カウントし、そこに曜日や天候、イベントなどの情報も加味して回帰分析すれば、明日どのくらいの来店客が来るかを時間単位で予測して、商品の仕入れや店員シフト計画に役立てることができます。
なお、こうした来店数予測に限らず、株価の予測や需要予測など、とにかく”回帰は数値を予測するもの”と覚えておいてください。
クラスタリング(Clustering)
クラスタリングもまた、「さまざまなオブジェクトを自動分類」するための手法です。あれ、分類(Classification)と同じですね。主な違いは学習方法にあります。分類は「教師あり学習」なのに対し、クラスタリングは「教師なし学習」です。
例えば、異常検知(Anomary Detection)を使う場合、正常と異常のラベルを付けて学習させたうえで異常を見つけるのは「教師あり学習」の分類(Classification)です。一方、これを「教師なし学習」のクラスタリング(Clustering)で行う場合は、これまでとかなり違う値のものを取り分ける「離れ値検知」などが用いられます。
海外の人はネーミングがうまいです。機械学習を勉強する際に出くわす言葉に、次元の呪い(The curse of dimensionality)というものがあります。これは空間の次元が増えるのに対して、計算処理が指数関数的に大きくなることを”呪い”という言葉で表したものです。ディープラーニングにおいても、むやみに次元(ディープ度)を増やすとGPUを使っても学習に相当な時間がかかります。
この対策が、scikit-learn cheat-sheetに登場するdimensionality reductionです。次元削減と呼ばれています。これは、多くの次元を持ったものを、その意味を保持しながら(落としても影響のない次元を削減して)少ない次元にする手法です。例えば図2に登場するPCA(Principal Compornent Analysis:主成分分析)は、対象データの集合の特徴を最もよく表現する成分のみに次元を絞る手法です。
異常検知(Anomaly Detection)
図3では、REGRESSION(回帰)、2つのCLASSIFICATION(分類)、CLUSTERING(クラスタリング)といったアルゴリズムのカテゴリーと一緒にANOMALY DETECTION(異常検知)が並んでいますが、これがどうも気持ち悪いです。お気づきのように、回帰や分類、クラスタリングはアルゴリズムのカテゴリーなのに対し、異常検知は応用のカテゴリーだからです。
異常検知を整理すると、表2のようなマトリクスになります。いずれの分野でも「教師あり」と「教師なし」の2つのカテゴリーがあります。
表2:Anomary Detectionの範疇
| 設備異常 | 製品異常 | |
|---|---|---|
| 異常検知(現在) | 橋やトンネルのひび割れ、電線や配管の異常などの検知 | 工場の製品、農作物、人間の診断画像などで異常検知 |
| 予知保全(未来) | 音や振動などにより、将来の異常を早期発見 | 不具合発生の予兆を検知 |
今回は、機械学習の主役であるデータとアルゴリズムのうち、アルゴリズムについて解説しました。次回は、どのような分野にAIが適しているかについて、事例をもとに解説します。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
