全文検索サーバを作るには 本記事では、Webアプリケーションから呼び出される検索サーバの実装に、RubyやC++ではなく、なぜJavaを採用したかをお伝えしたい。Webアプリケーション側の実装にもJavaを採用したが、その理由は存在しているフレームワーク・ライブラリによるもので今回は割愛させていただく。 今回解説する呼び出し元のWebアプリケーションは、外国の特許関連の文献の検索・表示・機械翻訳を行うことを主目的にしているものだ。特許文献という性質上、検索機能には次のような5つの要求が発生し、負荷分散の観点から全文検索は属性ごとに別のサーバで行うことにした。 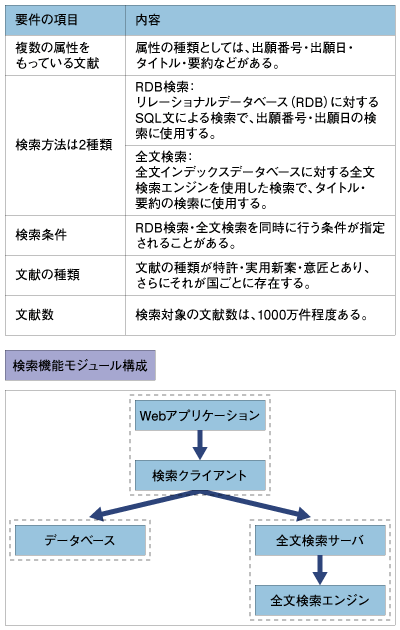 これらの要件を踏まえ、最終的には図のようなモジュール構成となった。また、検索クライアントはjarとしてWebアプリケーションに組み込んでおり、全文検索サーバは属性の種類ごとに存在する。 全文検索エンジンを一から開発することはコストと納期の面から厳しいので、フリーの全文検索エンジンHyper Estraierを使用することにした。これはC言語で書かれた共有ライブラリの形で提供されている。 Hyper Estraier http://hyperestraier.sourceforge.net/ これらのことから全文検索サーバを実装する言語に必要な要件は、「共有ライブラリを使用することが可能」「Javaで作成されたクライアントとの通信(LAN内)の仕組みを容易に実現可能」「サーバ自体が使用するメモリ使用量は抑えたい」「ある程度の性能」「堅牢な動作」となる。 特に「Javaで作成されたクライアントとの通信(LAN内)の仕組みを容易に実現可能」の要件が重要だ。特許関連文献は図版などが多用されているので、一文献あたりの情報量が非常に大きい。また、四半期ごとに文献データベースが更新されるので、それにすばやく追随していけるような柔軟性も要求される。したがって最初から負荷分散と構成の柔軟性を見すえたアーキテクチャを採用することが必須であった。 今回のようなアーキテクチャを実現するため、筆者はJavaを選択した。では、その理由について、先ほど述べた要件を満たしているのかを順にみていこう。 | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
人気記事ランキング
-
-
連載

