連載最終回の今回は、データ・ストアを対象としたデータ検索について解説します。
App Engineのデータ・ストアは、分散キー・バリュー・ストア(KVS)を使っています。ここまでは主に、キー・バリュー・ストアのメリットを解説してきました。データ・ストアを対象としたデータ検索は、キー・バリュー・ストアの弱点と言われることもあります。実際のところはどうなのでしょうか。
今回は、キー・バリュー・ストアを対象とした検索の仕組みについて簡単に説明し、そのあとで、Low-Level APIを使ってデータ・ストアを検索する方法を、サンプル・プログラムを例に解説します。
1. GAEのデータ・ストアとBigtable
1.1. エンティティ・テーブルとプロトコル・バッファ
ユーザー・データ(エンティティ)は、どのようにキー・バリュー・ストアに書き込まれるのでしょうか。App Engineのデータ・ストアの場合、Bigtableでは、プロトコル・バッファでシリアライズされてから登録(永続化)されます。このため、登録エンティティは、それぞれのエンティティにおいて、プロパティ項目を別個の項目(カラム)として認識できる形にはなっていません。
|
||||
| 図1: Entities tableでのキー・バリュー値 | ||||
Bigtableにおいて、ユーザーが書き込んだデータが登録されているテーブルは、Entities tableと呼ばれます。図1は、このテーブルにおけるエンティティを表したものです。ここでポイントになるのは、主キー項目です。
主キーは、プロトコル・バッファとは異なる特別の方式でエンコーディングされ、検索用にエンティティ・テーブルの行名として使われます。さらに、主キーは、ほかのプロパティ項目と同様に、プロトコル・バッファ・フォーマットにシリアライズされ、バイナリ・フォーマットのエンティティ・データに含まれます。結局、主キーは、2つのフォーマットでエンコーディングされることになります。
主キーを使えば、エンティティ・テーブル(Entities table)だけしかない場合でも検索できます。一方、主キー以外のプロパティ項目を使って検索することは、上記の理由からできません。これは問題です。検索条件としてプロパティ項目を指定できないとしたら、クラウド・ベースのアプリケーションの要求には、特殊な例を除いて対応できないでしょう。
このような要求に応えるため、GAEのデータ・ストアでは、ユーザー・エンティティを格納するテーブルのほかにもBigtableのテーブルが使われています。これらのテーブルを使うことによって、データ・ストアに対する条件検索を可能にしています(図2)。
|
|
| 図2: GAEのデータ・ストア |
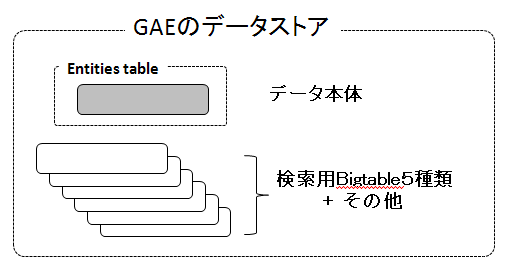
図2のように、GAEでは、ユーザー・データを保持するKVSの構造に変更を加えることなく、外部に追加したテーブルを用いることで、条件検索の要求に応えています。もともとはGoogle検索用途に作られたファイル構造をそのまま流用しつつ、検索用のBigtableを追加しているわけです。将来的には、Bigtableをさらに変更・追加することも比較的容易に実現できるでしょう。
1.2. GAEのデータ・ストアを構成するテーブル
GAEでは、以下に示す、全部で7種類のBigtableが使われています。
- Entities Table
- EntitiesByKind Table
- EntitiesByProperty ASC Table
- EntitiesByProperty DESC Table
- EntitiesByCompositeProperty Table
- Custom indexes Table
- Id sequences Table
それぞれのテーブルの機能は、大まかに以下の通りです。
- アプリケーション・プログラムからの書き込みデータは、Entities Tableに格納されます。
- エンティティ(Entity)は、EntitiesByKind Tableによって、あるkindに属するすべてのエンティティを参照できるようになります。
- EntitiesByProperty ASC TableとEntitiesByProperty DESC Tableでは、プロパティ項目が昇順・降順でセットされています。この2つのテーブルを使うことで、任意のプロパティを用いた、昇順または降順のエンティティ・データの取得が可能になります。
上記の方法では、単一のプロパティ項目を指定した場合に限って検索が可能です。一方、複数のプロパティ項目を用いて検索条件を指定するような複合検索はできません。このような複合検索が要求される場合は、EntitiesByCompositeProperty TableとCustom indexes Tableが生成・使用されます。
このテーブルは、Javaではdatastore-indexes.xml、Pythonの場合はindex.yamlに記述されているインデックス定義から生成されます。複合検索で指定したインデックス定義が存在しない場合は、検索時に例外が投げられ、エラーとなります。したがって、EclipseでJavaでの検索プログラムを作成する場合は、ローカル環境で必ずプログラムを実行し、datastore-indexes-auto.xmlを自動生成してからクラウド環境にアップロードする必要があります。
最後のId sequences Tableは、エンティティとカスタム・インデックスにアサインされる数値のデータ・ストアIDを生成・格納するものです。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
