2023年12月11日、12日の両日にハイブリッド形式で開催されたCloudNative Days Tokyo 2023から、LINEヤフーの社内Kubernetes as a Service(KaaS)プラットフォーム「ZCP」を安定運用するための監視や対応に関して、同社でZCPのSREを務める小林大輔氏と土谷続季氏が発表したセッションを紹介する。

セッションを担当した小林大輔氏

セッションを担当した土谷続季氏
タイトルは「100万コンテナのKubernetesプラットフォームを5年間スケーラブルに運用するために乗り越えていること」。前半では小林氏が、SLIとSLO※を導入して監視方法を変更し、運用の安定化とトイル(繰り返される手作業)の削減をしたことについて説明。後半では土谷氏が、アラートの削減やセルフサービス化のUXについて説明した。
※
SLI:Service Level Indicators、サービスレベル指標
SLO:Service Level Objectives、サービスレベル目標
信頼性・安定性、トイル削減、UXの3つのマイルストーンで改善
ZCPは、Yahoo! JAPANサービス用のKubernetes as a Service(KaaS)だ。Yahoo! JAPANのサービス開発者がアプリケーションの開発に集中できるよう、セキュアで運用が簡単になることを目指している。
ZCPは2018年にGA(本番運用開始)し、2023年12月時点で1600クラスターが稼働、その上で200サービス以上が構築されている。また、111万以上のコンテナと59000以上のVMが稼働している。
ちなみにセッションタイトルは「100万コンテナ」だが、これは発表を申し込んだ時点での数字であり、そこから増えたとのことだった。
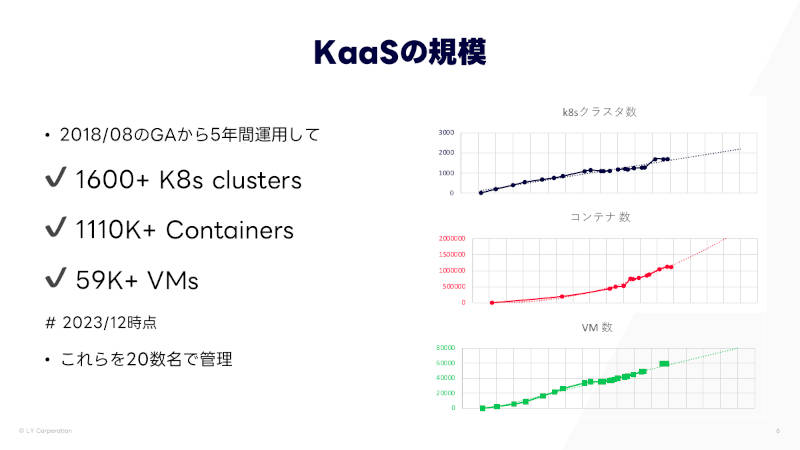
ZCPの規模
ZCPは「LINEヤフーが世界の変化に爆速で適応できる」をプロダクトビジョンに、信頼性・安定性、トイル削減、UXの3つをこの優先順位でマイルストーンとしている。
2018年にGAした初期ではまず信頼性・安定性を最優先に取り組み、中期では定常的なトイルを削減してスケーラビリティに集中。現在はこの2つが達成しつつあるところで、次の段階としてサービス開発者が開発に集中できるUXに取り組んでいるという。
今回の2人の話は、この3段階にのっとって説明された。

ZCPのプロダクトビジョンとマイルストーン
SLI/SLOの計測・監視で「信頼性に愛着を持てるように」
最初に小林氏が話したのは、信頼性・安定性からトイル削減に関わる、SLI/SLOの計測・監視だ。
大量のクラスターを監視するのに、従来はクラスターの中にPrometheusのexporterを入れてメトリクスを取得していた。そのため、監視対象が部分的になるほか、kube-apiserverも不調になるとメトリクスがとれなくなる問題があったという。
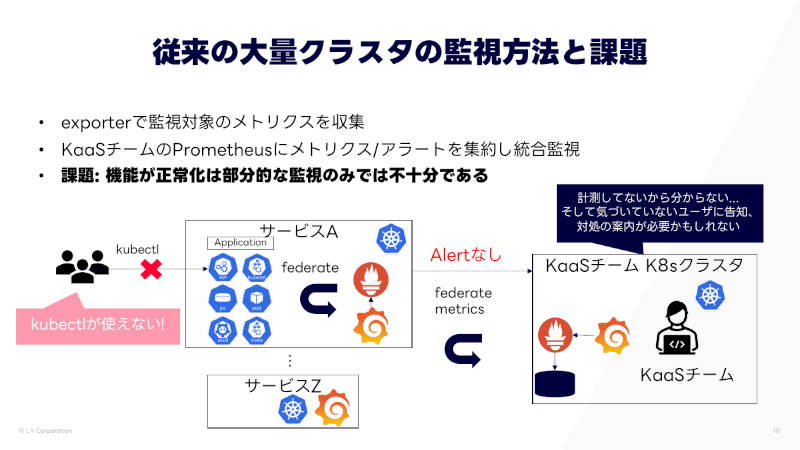
従来の監視方法と課題
この問題に対し、利用者が使う機能をSLOとして、SLIを計測することにした。そのために、利用者側のクラスターにプローブをデプロイして定期実行し、メトリクスとして取得するようにした。これを集約して、既存の監視系で監視している。
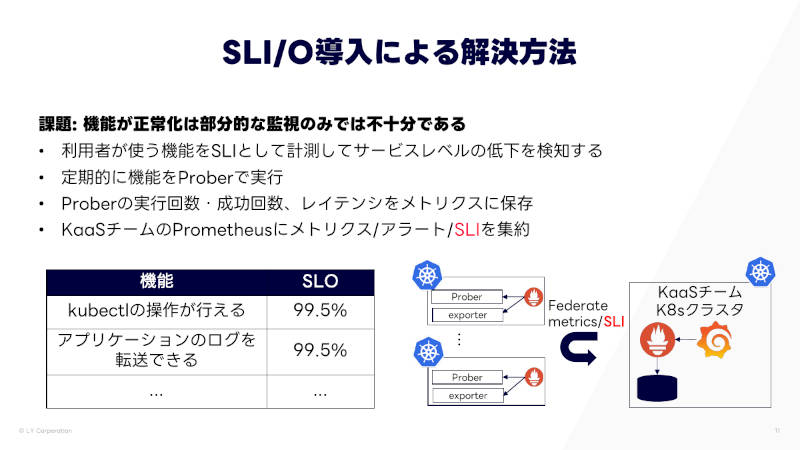
SLI/SLO導入による解決
これにより、SLI/SLOの統合監視と可視化ができるようになり、複数のクラスターでのサービスレベルの低下から、リージョン単位での大規模障害までわかるようになった。そして、エラーバジェットやサービスレートの急激な低下なども監視している。
その結果「われわれも信頼性に愛着を持てるようになった」と小林氏は言う。オンコール担当が毎朝SLIを把握し、SLO違反を未然に防ぐ予防保全によって、トラブルの元を防いでいるという。また、マネージャーにとっても、インシデント対応に集中しているときに割り込みせずに対応状況が見えるようになったという。
またこの施策は、トイル削減にもつながった。リリース自動化とカナリアリリースを実施するにあたり、リリースが成功したかどうかの判定にSLIを使っている。

信頼性に愛着を持てるように
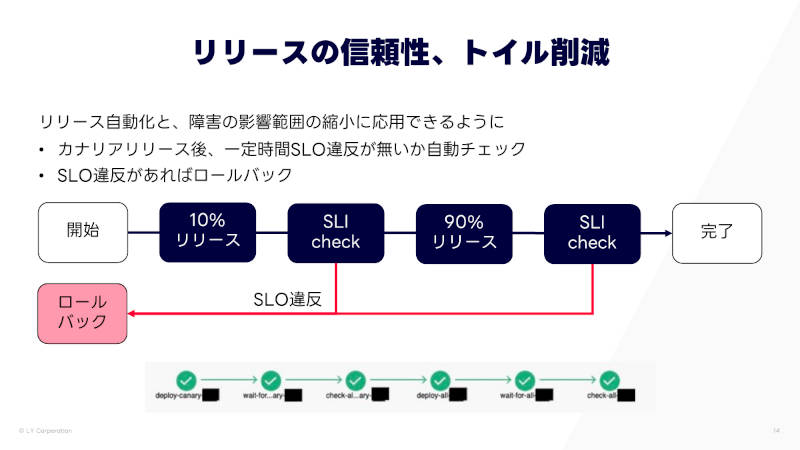
トイル削減にもつながった
ノイジーネイバーを特定する仕組みを作り、自動対応も
次に小林氏が話したのも、安定性からトイル削減に関わる、収容効率を上げたときの問題だ。
ZCPはシェアード環境で、物理コア数以上のVMを動かすCPUオーバーコミットを設定している。これにより利用効率を高くできるが、重いワークロード(ノイジーネイバー)があるとCPU Steal(CPUの取り合いに負ける)が起こるという問題がある。これによりサービスのレイテンシー悪化や、UXの悪化につながる。
しかし、ノイジーネイバーの特定には時間がかかり、中には3ヶ月かかった例もあるという。これは、特定のハイパーバイザーで同居しているVMを利用者は把握できないこと、KaaS管理者であっても数万の全VMにアクセスして同居しているVMのリストを得る必要があり、非常に困難であることなどによる。
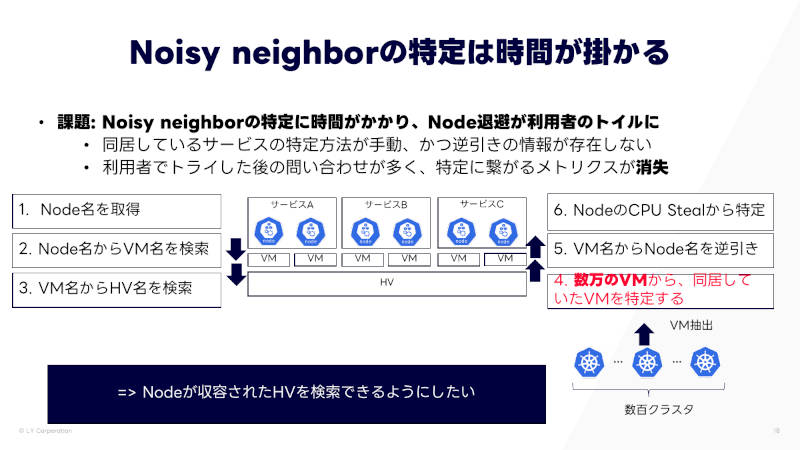
ノイジーネイバーの特定に時間がかかる問題
そこで、ハイパーバイザーとVM、その上に乘っているノードの紐づけを取得できるexporterを開発して、簡単に収容状況がとれるようにした。これによって、ダッシュボードから全クラスターのCPU Stealが確認できるようになった。
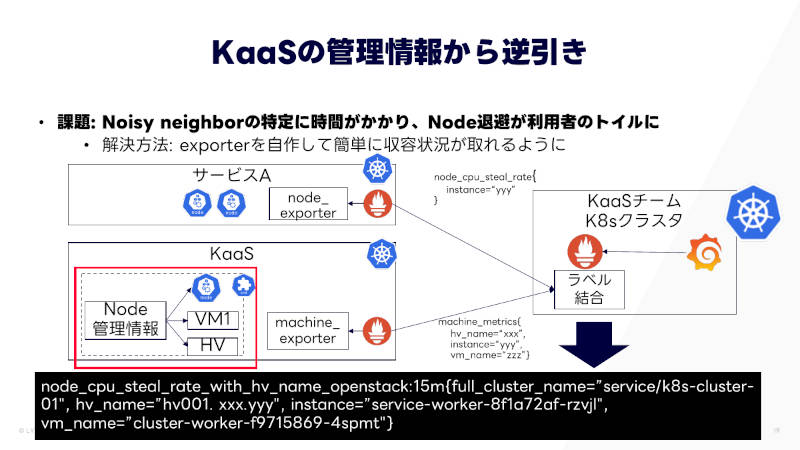
exporterを開発して簡単に収容状況がとれるように
メトリクスにできたことから、トイル削減にもつながった。CPU Stealを監視し、閾値を超えたら自動的にノードを退避するオペレーションを実行するようにした。
その結果、CPU Stealのスパイクが減ってサービスが安定稼働するようになり、エンドユーザーのUX向上にもつながった。前述の3ヶ月かかった特定時間も、1.5時間にまで短縮された。

自動的にノードを退避するように自動化してトイル削減
アラートを4つに分類し、それぞれの対応で負荷を下げる
ここから土谷氏に交代し、信頼性からトイル削減に関わる、アラートの削減について話した。
小林氏が説明したようにSLI拡充を進めた結果、監視項目が増えて、アラートも増加した。それにより、オンコール担当がアラート対応に追われ、さらに複数業務のコンテクストスイッチが増加して、疲弊してしまうようになった。
アラート対応が増加
そこで、PagerDutyからアラートの一覧を取得して集計し、何に疲弊しているかを調査し、アラートを4つに分類した。
1つめは、発生してもすぐ直せる「Noisy Alerts」で、監視系のほうの問題で一時的に発生していることが多い。
2つめは、原因の究明が簡単で、対応手順も明確になっていて、復旧も自分たちで行える「Easy-Easy Alerts」だ。
3つめは、原因究明は簡単だが、対応手順があまり明確になっていなかったり、あるいは復旧が自分たちで行えなかったりする「Easy-Hard Alerts」だ。たとえば、KaaSが依存している別のシステムで問題が起きているときなどが該当する。
そして4つめが、原因究明が難しく、その結果としてアラートの解決にも時間がかかってしまう「Hard-Hard Alerts」だ。

アラートを4つに分類
このうち、まず簡単だが数の多いNoisy AlertsとEasy-Easy Alertsの2種類から、アラートをなくす方向で対策した。Noisy Alertsについては監視方法やアラートルールを見直した。Easy-Easy Alertsはトイルとして、メトリクスをベースに自動で復旧するものを開発した。
続いてEasy-Hard Alertsについては、その部分のRunbookを拡充したり、監視する必要がないものを削除したりといった対策により、なるべきEasy-Easy Alertsに寄せた。
最後のHard-Hard Alertsについては、原因究明が難しいことが課題のため、Runbookを見直して原因究明手順の拡充を進め、フローチャート化を試みた。俗人化せずに原因究明できるようにすることで、Easy-Hard AlertsやEasy-Easy Alertsにできるようにしているという。

4種類のアラートごとの対策
これらの取り組みの結果、Slackのアラート通知部屋にも平和が戻ってきた。今までオンコール担当は2人で対応していたのが、平常時だったら1人でも回せるぐらいの分量になった。これによって、より本質的なトイル削減などの改善に取り組めるようになったという。
ZCP利用者用のUXとしてzcpctlを提供
最後は、安定性・信頼性のあと、トイル削減からUXの段階で、セルフサービス化の話だ。
社内のサービス開発者の立場からすると、やりたいことによって、申請フォームやGitHubのIssue、専用のCLI、kubectlなど、インターフェイスが分かれて統一されていなかった。ZCPの管理者としても、管理するものが多くなり、管理コストが増えていた。
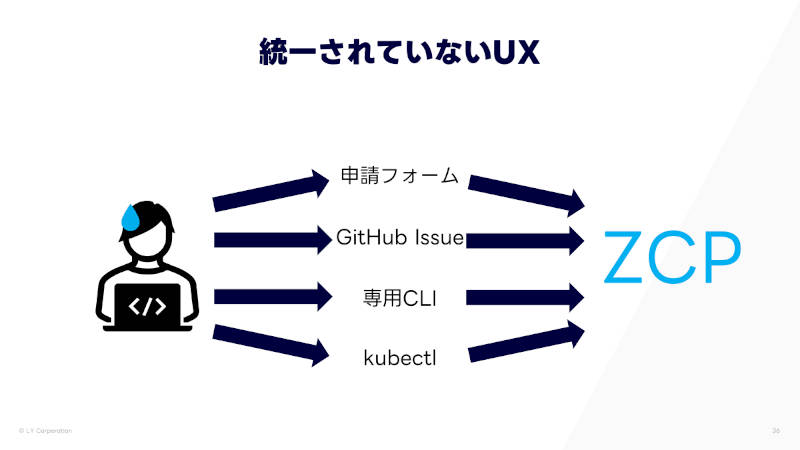
統一されていないUXの課題
ここまでの説明のように信頼性・安定化や、トイル削減の取り組みが進んだことにより、次の段階としてこの課題に取り組めるようになった。そして、統一的なCLIであるzcpctlを提供した。
ZCPの利用者にとってのメリットとしてはまず、ZCPにどういう機能があるのかがドキュメントを探さなくても、CLIのヘルプを見れば把握できることが挙げられる。また、管理者と共通のツールではなく利用者用のツールにすることで、利用者のユースケースに沿ったインターフェイスになった。さらに、申請フォームで自動化できなかった部分まで自動化したことが、手順書の廃止にもつながった。
一方zcpctlはZCPの管理者側にも大きなメリットがあったという。zcpctlで提供している機能であれば、利用者に提供している機能だとわかる。また、ドメインロジックを一箇所のコードに落としこんで集約できた。

zcpctlの提供
最後に一連の取り組みをまとめ、ZCPをより安定したプラットフォームにしていくために継続的に取り組んで、さらに先進的なKaaSの提供を目指していく、と土谷氏はまとめた。
LINEヤフーでは、これまでも自社のプライベートクラウドについて、エンジニアがカンファレンスイベントで積極的に発表して、実際に大規模な環境を運用して得られた経験を語ってきた。
今回は、プラットフォーム自体というよりその運用面について、地道に問題をつぶしていく取り組みが紹介された。規模の違いはあれ、SLOにもとづいた監視を考えたり、自動化したり、アラート疲れを防いだりというのは、参考になる運用現場も多いのではないだろうか。
- この記事のキーワード
関連記事
【CNDS2025】 数百万台のサーバーを守る仕組みを解き明かすマイクロソフトのSREとAIOpsの最新アプローチ
9月4日 6:00
Observability Conference 2022、オブザーバビリティから組織、ルールを見直した事例を紹介
2022年6月29日 6:00
【CNDW2024】障害特定が超爆速に! セブン&アイ・ネットメディアが実現したObservabilityの威力
1月23日 6:00
【CNDW2024】GitOpsと完全プライベートEKS環境で実現する開発基盤
3月18日 5:59
Cloud Operator Days Tokyo 2021開催、New Relicとドコモのセッションを振り返る
2021年11月17日 6:00
CI/CD Conferenceレポート トレジャーデータのCI/CDのポイントはリリースリスクの最小化
2021年10月7日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
初めてでも安心! OCIチュートリアルを活用して、MySQLのマネージド・データベース・サービスを体験してみよう
2021年4月21日 12:39
使って分かった国産クラウド「K5」のメリットとは
2018年1月31日 6:30
Dockerを理解するための8つの軸
2015年7月29日 22:00
Dockerの誤解と神話。識者が語るDockerの使いどころとは? Docker座談会(前編)
2016年2月22日 0:00
【イベントリポート:Red Hat Summit: Connect | Japan 2022】クラウドネイティブ開発の進展を追い風に存在感を増すRed Hatの「オープンハイブリッドクラウド」とは
2022年11月10日 8:45
Kubernetes、PaaS、Serverlessのどれを選ぶのか? 機能比較と使い分けのポイント
2018年5月23日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
