CI/CDから障害の復旧までハイレベルの運用自動化を実現するKeptnとは
CNCFのサンドボックスプロジェクトKeptnを紹介する。
2021年4月14日 6:59
CI/CDをオーケストレーションするツールKeptnは、2020年6月26日にSIG App Deliveryでの検討の上、TOCのスポンサーを得てCNCFのサンドボックスプロジェクトとして認定されたオープンソースソフトウェアだ。今回は、2020年12月にオーストリアのDynatraceが公開した「Introduction to Keptn」という動画から概要を紹介する。
セッションを担当したのは、Rawkodeというサイトを運営するEquinixのエンジニアDavid McKay氏と、DynatraceのエンジニアJurgen Etzlstorfer氏だ。動画そのものもRawkodeのチャネルで公開されているもので、CNCFのWebinarでもなければDynatraceの公式チャネルでもないが、Keptnの概要と公式サイトに記載されているチュートリアルを2回に渡って詳細に解説するもので、合計3時間弱という長い時間でKeptnの機能を一通り紹介する内容となっている。
動画:Introduction to Keptn, Part 1
動画:Introduction to Keptn, Part 2

Keptnの概要を解説
ちなみにKeptnはそのまま読めば「ケプトン」という発音になると思われるが、動画の中では「キャプテン」という発音で紹介されていた。Kubernetesがギリシャ語の航海長を意味していることから、Kubernetesのエコシステムには海や航海にまつわる名前のものが多く、Keptnもさまざまな船員を束ねるキャプテン(船長)という意味もあることをコメントで紹介している。またKで始まるのもKubernetes関連のソフトウェアに多い特徴だ。
セッションを担当する2名。McKay氏(左)が質問役、Etzlstorfer氏が回答役として進行する
デモはAWSなどのメガサービスプロバイダーではなくEquinixのサービスを使って行われており、それぞれお互い所属する企業のプラットフォーム、サービスを交えて紹介することも可能だったと思われるが、極力、ベンダーニュートラルな解説になっているのは好感が持てる。

「Cloud-native application life-cycle orchestration」がキャッチコピー
クラウドネイティブなアプリケーションライフサイクルを管理運用するツールというのがKeptnのキャッチコピーだ。
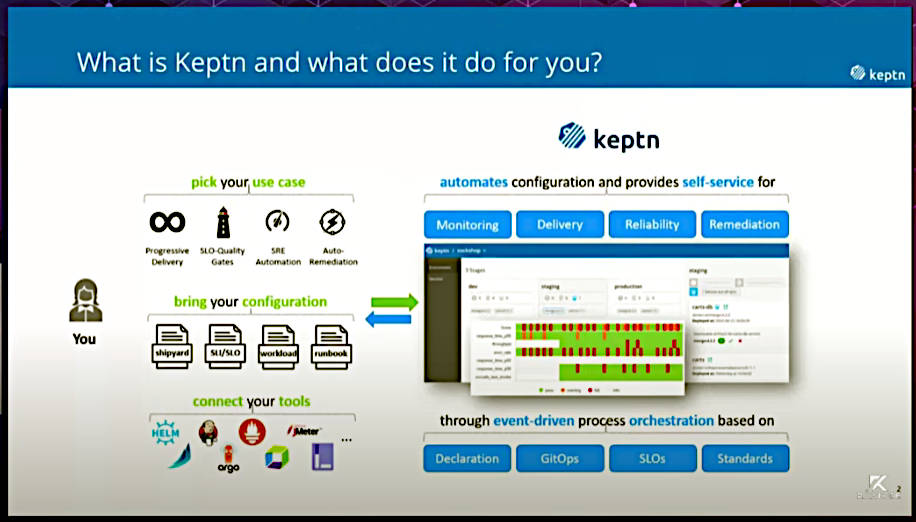
Keptnとは何か?
このスライドでは「Keptnとは何か?」を解説しているが、「Automates configuration and provides self-service for Monitoring, Delivery, Reliability, Remediation」という右側に書かれている単語が大体の概要を表している。つまり「構成を自動化し、モニタリング、アプリケーションデリバリー、信頼性、修復を提供」するのがKeptnとなる。
これらの機能をさまざまなユースケースに対して選択的にアプリケーションデリバリー、SLO(Service Level Objective、評価基準)に対応したゲーティングサービス、SREの自動化、自動修復などとして実現できるのが、Keptnの特徴である。
ここでは選択的というキーワードがポイントだろう。これらの単語の並びを見ているだけだと、Keptnは新しいCI/CDのツールか運用管理のヘルプデスク、さらにはモニタリングツールであるように認識されてしまいがちだ。
しかしKeptnは、GitHubやJenkins、Argo CD、Concourse、Helm、JMeter、Grafana、Prometheus、Slackなどのツールの上位に位置して、それらをオーケストレーションするコントロールプレーンであると認識するのが正しいだろう。

Keptnを開発した3つの理由
次のスライドではKeptnを開発した理由として、2020年に実施された調査の結果、「CI/CDのパイプラインのメンテナンスに時間が掛かっていること」「マニュアルによる作業が多いこと」「障害回復のマニュアル工数が多い」ことなどを挙げている。なおこの調査結果の分析では、運用の自動化の尺度として、デベロッパーと運用担当者の数の比率を調べている。ここでは運用担当者1名に対してデベロッパー15名以上の組織を、高度に運用が自動化されている@<b>{エリートユーザー」と呼んでいる。
ちなみにCloud Foundryを開発しているPivotalによれば、Cloud Foundryのユーザーでは「200名のデベロッパーに対して1名の運用担当者」というのがPivotalにおけるエリートユーザーの基準であるという。
参考:ACM Survey, Part 1: How your peers use cloud automation to innovate faster
ここでDynatraceがCloud Foundryをベストプラクティスとして挙げているのは、PaaSにおいて運用担当者が不要になることが理想的であるという発想の現れだろう。
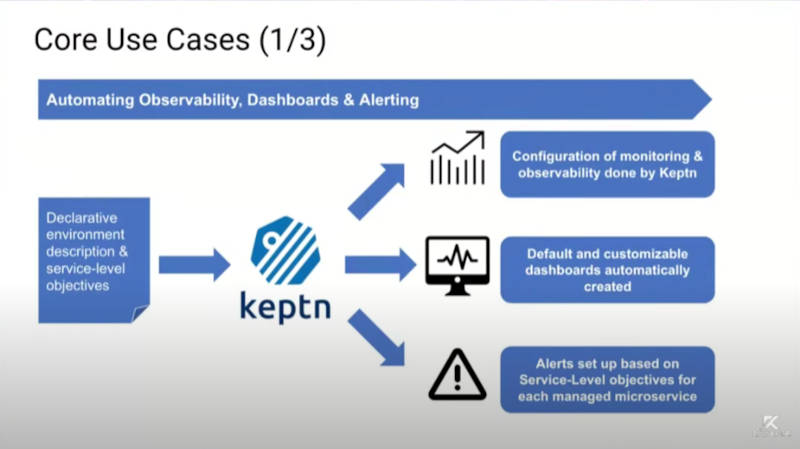
Keptnのユースケース、監視の自動化
続いては「構成を自動化し、モニタリング、アプリケーションデリバリー、信頼性、修復を提供」するKeptnの機能がどのように使われるか? についての解説で、3枚のスライドに分けられて説明が行われた。
最初は監視の自動化だ。監視とダッシュボードの実装はわかりやすいが、最後の「SLO(Service Level Objective)によるシステムに対するアラートの設定」という部分が目新しい。これは「アプリケーションに設定されたKPIに対して目標を設定して、それが達成されない場合はアクションを起こす」という発想だ。具体例を挙げると「ショッピングカートにアイテムを追加したら○○ms以内にレスポンスを返す」「検索結果を○○ms以内に表示する」などのビジネスサイドの要求に対して、システムが応えられない場合にアラートを出すというものだ。
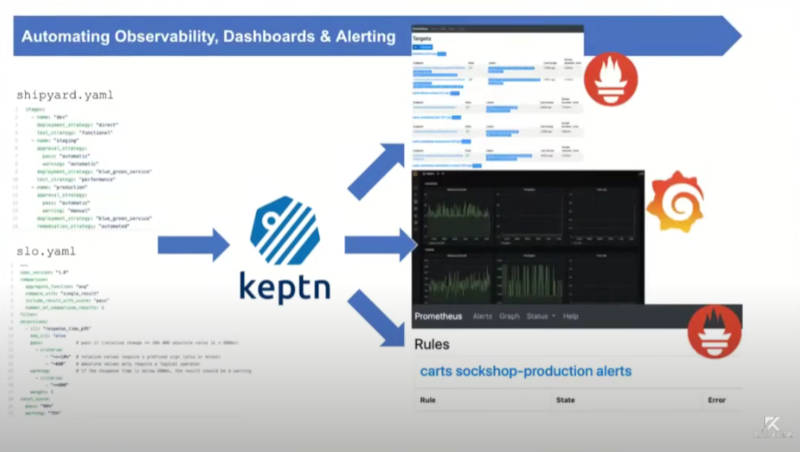
アラートの設定はShipyardとSLOというYAMLファイルで行う
このスライドではショッピングカートに対するルールを設定し、Prometheus、Grafanaなどを使って管理する例が示されている。
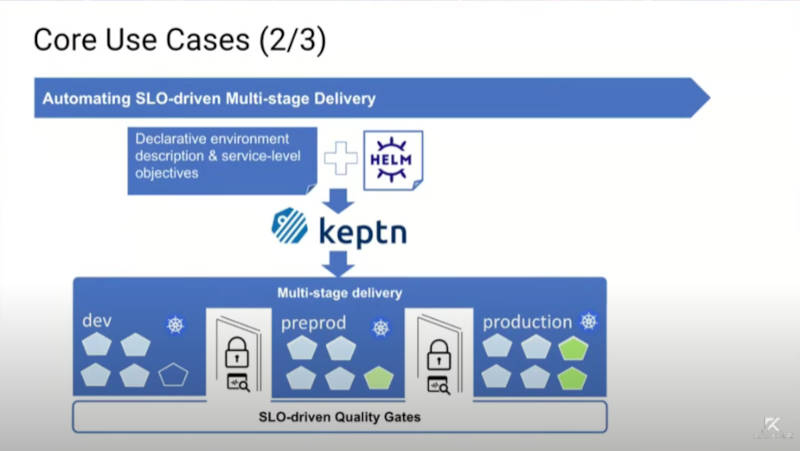
2つ目のユースケース、マルチステージのデプロイメント
次のユースケースは、Keptnが提供するマルチステージのデプロイメントに関するものだ。Keptnでは、開発環境、ステージング環境、本番環境という3つのステージがデフォルトで設定される。また各ステージにおいて新しいバージョンがどうやってデプロイされるのかも選択できる。現状ではダイレクトかブルーグリーンのどちらかを選択するしかないが、今後はカナリアデプロイメントなどもサポートされるという。Keptnのドキュメントでは「Progressive Delivery」と称されているが、各ステージにクオリティゲート(要求された仕様に適格しているかを判断するゲート)を設定して、それに合格したものだけが次のステージに進めるという仕組みを解説している。
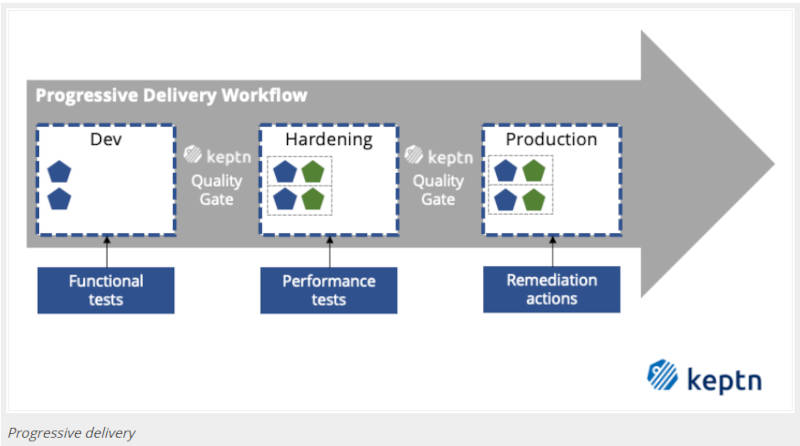
各ステージにおいて要求されるゲートが異なる
この図はKeptnのドキュメントサイトからの引用だが、開発環境においては機能テストを、ステージング環境ではパフォーマンステストを達成して本番環境に進むという内容を示している。
参考:Declarative Multi-Stage Delivery
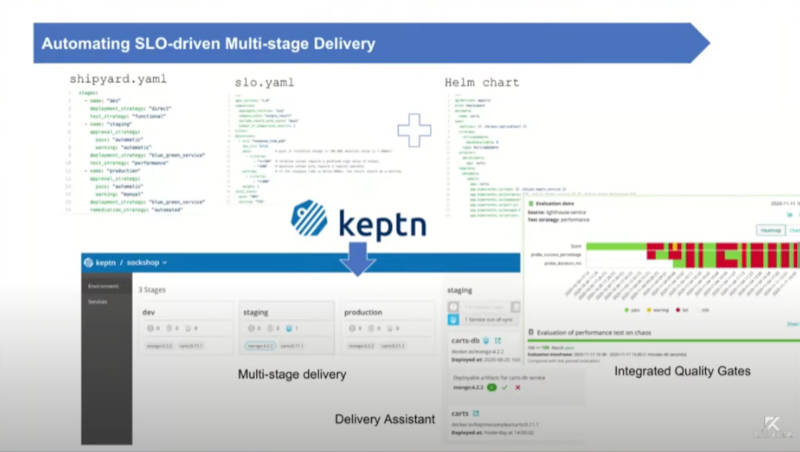
アプリケーションの実装はHelm、テストはJMeterを使う
サービスの評価のためにSLO(Service Level Objective)とSLI(Service Level Indicator)を使うというのがKeptnの発想だ。SLIで何を評価するのかを設定し、SLOでSLIに対する目標値とそれを超えた時の対応を決めることで、単に観測するだけではなく、アクションを設定することで自動化を進めようという意図を感じる。

SLOとSLIをYAMLファイルで設定
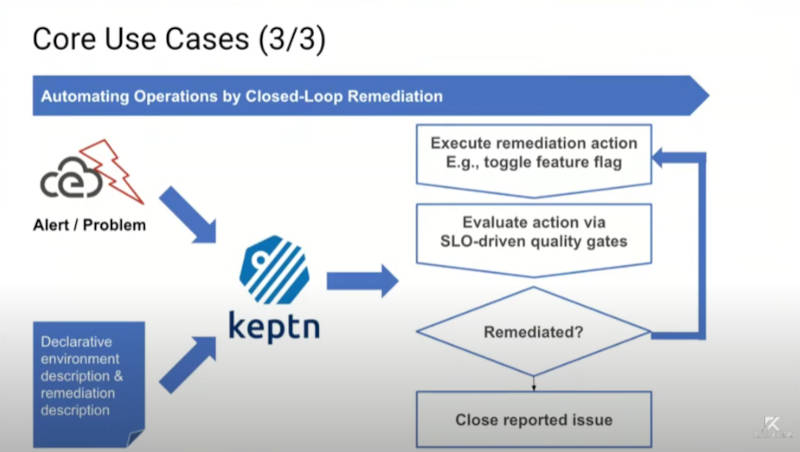
CloudEventsを使ったイベント処理でアラートを修復
3つ目のユースケースは運用の自動化のために修復を行う機能だ。動画のコメントにもあったが、この場合の修復はあくまでも運用でカバーできる修復を意味しており、「ルールを適用したからと言ってソースコードのバグがなくなるわけではない」。つまり性能が劣化したらアプリケーションのPodを複数起動して性能を上げる、不具合を起こした機能をフィーチャーフラグを使ってオフにするという対応を意味している。
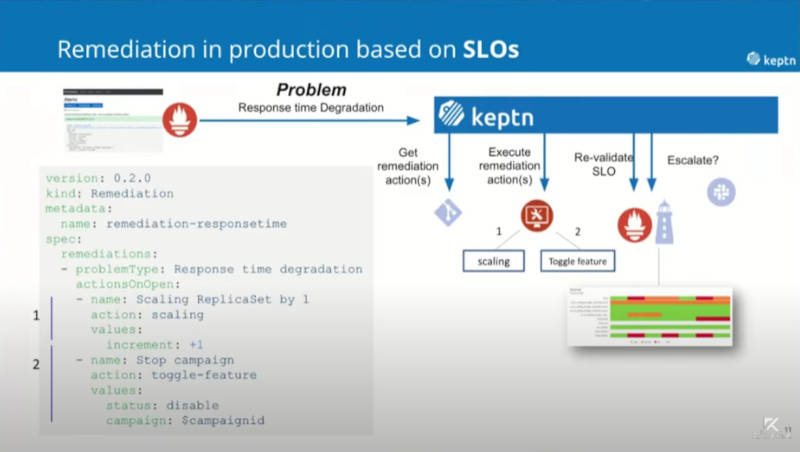
性能劣化が発生したら対応を実施して再度、SLIを評価
この例ではPrometheusのクエリーの結果、性能劣化が発見されたらPodを追加、機能をオフにするという修復のためのアクションが示されている。
ここまでで理解できたのは、Keptnがコントロールプレーンとしてさまざまなツールを連携しマルチステージのデプロイメントを実現し、観測と評価によって自動運転を目指していることだ。
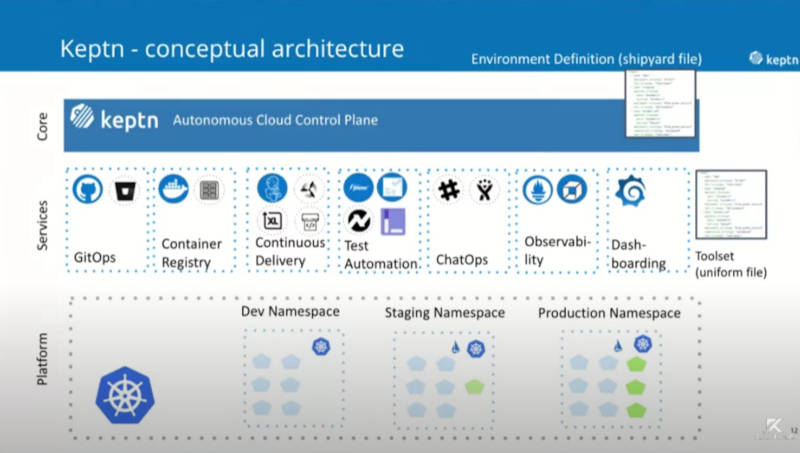
さまざまなツールと連携することで自動運転を目指す
最後にKeptnのエコシステムとして紹介されたのが、次のスライドだ。
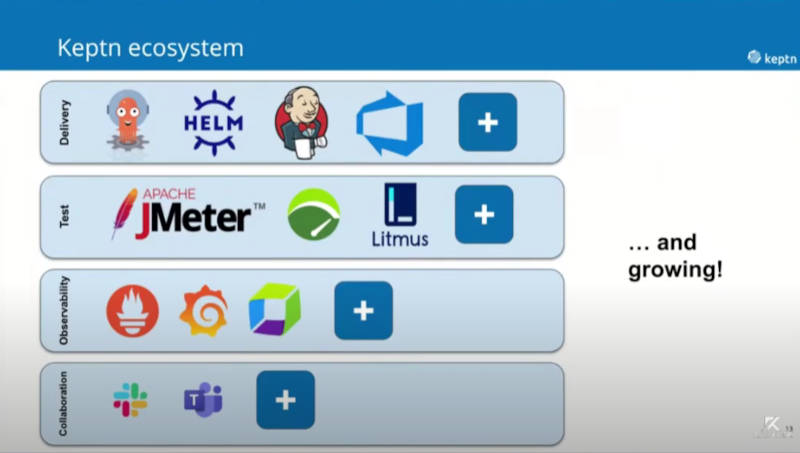
Keptnのエコシステム
デフォルトで連携のベースとなっているのはKubernetes、アプリケーションのライフサイクルはHelm、テストはJMeter、CI/CDはJenkinsとArgoCD、モニタリングにはPrometheusとDynatraceの商用ツール、通知にはSlackなどの外部ツールが利用されている。Keptnのイベント処理にはCloudEvents、ブルーグリーンデプロイメントにはIstio、メッセージ処理にはNATS、データストアはMongoDBというのが現状のKeptnの中身だ。Knativeもサーバーレスとして利用されていると謳われていたが、リソースの要求が高過ぎるということで、現在は外されていると言う。
動画の後半はそれぞれKeptnのチュートリアルを実際に実行してみるという内容となっている。このチュートリアルでは、多くのYAMLファイルを使ってKubernetesの環境にKeptnのモジュールを追加、変更、設定していくようすが紹介されている。GitOpsとして、すべての変更をコマンドラインではなくGitリポジトリーに存在するYAMLファイルを更新するだけでも可能であるという。
またカオスエンジニアリングにLitmus Chaosとの連携も可能であることが解説されていることからもわかるように、クラウドネイティブを強く意識しているのが見てとれる。ただKeptn自体のPodを本番環境などと別に分離して実装できない、Keptn自体のヘルスチェックを行うメトリクスが不十分、マルチクラスターには未対応など、未完成の部分も多いと感じられた。これからの進歩に期待するべきだろう。
CNCFのサンドボックスにあるソフトウェアは、LinkerdやEnvoyのようにシンプルにパーツとしての機能に徹するものが多いが、Keptnのように他のソフトウェアを連携させるハイレベルのコントロールプレーンというコンセプトが受け入れられるのか? 今後注目していきたい。
後半のチュートリアルは以下を参照して欲しい。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
