GPUの進化
GPUの進化
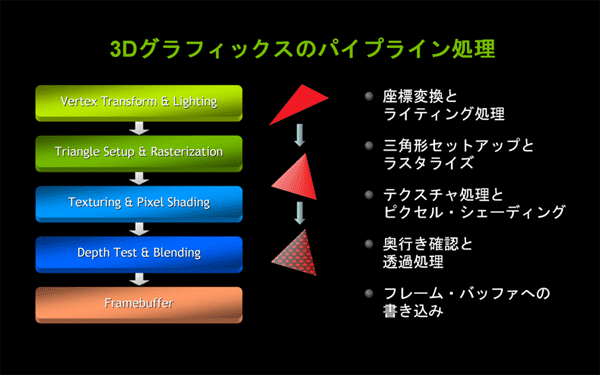
GPUの登場によって、グラフィックス処理にかかっていたCPUの負荷が激減しました。これに対して、2000年以降のGPUの進化は、半導体集積技術の進歩に合わせた3Dグラフィックス・パイプライン処理のさらなる高速化による、それまで実現できていなかった、リアルタイムで高精細・高品質なグラフィックスを実現していく歴史でもあります。
Vertex Shader(バーテックス・シェーダ)やPixel Shader(ピクセル・シェーダ)が行う計算式をプログラム可能にするプログラマブル・シェーダ技術が登場し、DirectXやシェーダ・モデルを用いたプログラミングの標準化が進みました。こうした動きに合わせ、2002年にはNVIDIAからグラフィックス向けC言語「Cg」が発表されました。高級シェーダ言語「HLSL」(High Level Shader Language)や「GLSL」(OpenGL Shader Language)とともに、ゲーム開発者やデジタル・コンテンツ・クリエータが簡単かつ迅速に高品質なリアルタイム・グラフィックスを実現する環境が整い始めました。
2004年に発表されたGeForce 6シリーズは、DirectX 9とシェーダ・モデル3.0に対応したスーパースカラー設計のGPUです。複数シェーダによる並列パイプライン処理が可能になり、さらなるパフォーマンスの向上に寄与しました。
DirectX 9対応のGPU は、Windows Vistaから搭載された新しいGUI「Windows Aero」のシステム要件の1つにもなっています。
|
|
| 図3: GPUが3次元グラフイックスを処理するための専用パイプライン処理 |
統合シェーダとGPGPU
2008年11月19日にNVIDIAが行った2つの発表は、GPUの役割がグラフィックスの枠を突き破って新たな世界に飛躍する、という、パラダイム・シフトの到来を告げるものでした。
- GeForce 8シリーズGPUの発表(G80世代GPU)
- 統合シェーダ・アーキテクチャ(Unified Shader Architecture)
- ジオメトリ・シェーダ(Geometry Shader)
- DirectX 10、シェーダ・モデル4.0
- 統合開発環境CUDA(Compute Unified Device Architecture)の発表
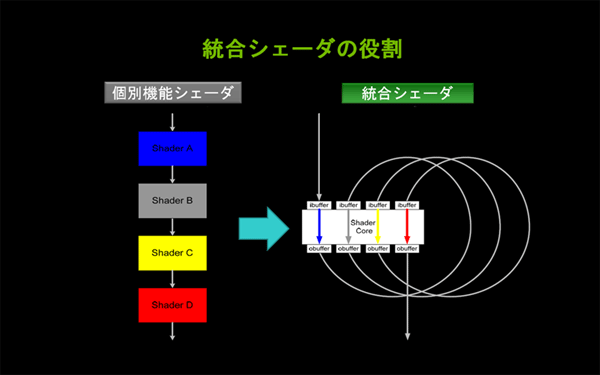
まず最初に、統合シェーダの必要性と、そのメリットについて考えましょう。
シェーダは以前から、スーパースカラー設計に基付き、同じ機能を持つ複数のシェーダを並列で動作させることが可能でした。ところが、アプリケーションの種類によっては、すべてのシェーダが効率よく使われるというわけではありませんでした。
例えば、対象オブジェクトの動きが大きいジオメトリ変換に処理負荷が偏重している状況では、バーテックス・シェーダはフル稼働しているもののピクセル・シェーダはほとんど休止している、という状態になります。逆に、大きな動きがなくピクセル描画偏重の状況では、ピクセル・シェーダはフル稼働しているもののバーテックス・シェーダは休止している、という状態が存在します。
|
|
| 図4: パイプラインを構成する目的別シェーダを1つに統合した理由(クリックで拡大) |

統合シェーダの当初の目的は、このような無駄を省くことでした。1つのシェーダが臨機応変にすべてのシェーダの機能を受け持つことで、なるべく多くのシェーダを並列に効率よく使用し、パフォーマンスを向上させる、ということでした。
|
|
| 図5: 統合シェーダはさまざまな役割をこなす |
このような経緯を経てシェーダがプログラマブルになり、単一機能にとどまらない汎用性を持つに至ったことは、GPUがグラフィックスの枠を飛び越えて汎用計算という新たな役割を担うことになる出発点となりました。
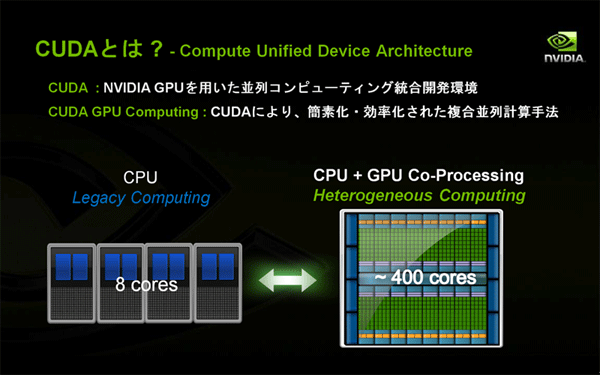
G80世代(GeForce 8シリーズ)のGPUは、最大128個のシェーダを持っていました。また、最新のGPUでは、最大400個以上のシェーダを持っています。これらのすべてのシェーダに並列的に浮動小数点演算を実行させることによってCPUのマルチ・コアを上回る計算能力を引き出そうというのが、GPGPU(General Purpose GPU: 汎用目的GPU)という考え方です。
統合開発環境CUDAの登場
しかし、登場したばかりのGPGPUの開発環境は、未熟なものでした。例えば、GPGPUの簡単な計算の例として、
Y[i] = a * X[i] + Y[i] という計算を、i=0 から n-1 まで行うサブルーチンを考えてみましょう。図6に示した参考例のように、ループを使うCPUの標準Cプログラムに比べると、グラフィックス言語を用いたGPUによる並列計算の複雑さは一目瞭然です。また、目的とする計算そのものとは直接関係のないグラフィックス言語を学習する必要があり、本当の意味でのGPUによる汎用計算の普及を支える技術にはなりませんでした。
|
|
| 図6: 旧方式のGPGPUで使われた言語は、処理の記述が複雑だった |

こうした初期のGPGPUの未熟さを解決すべく登場したのが、G80世代GPUと同時に発表された「CUDA」 (Compute Unified Device Architecture)です。CUDAとは、NVIDIAのGPUを用いた並列コンピューティングのための統合開発環境です。CUDAを利用して簡素化・効率化したCPUとGPUの複合並列計算手法を、CUDA GPUコンピューティングと呼んでいます。
|
|
| 図7: CUDAでは、C言語ライブラリなどによりGPGPUの開発環境を整備した |
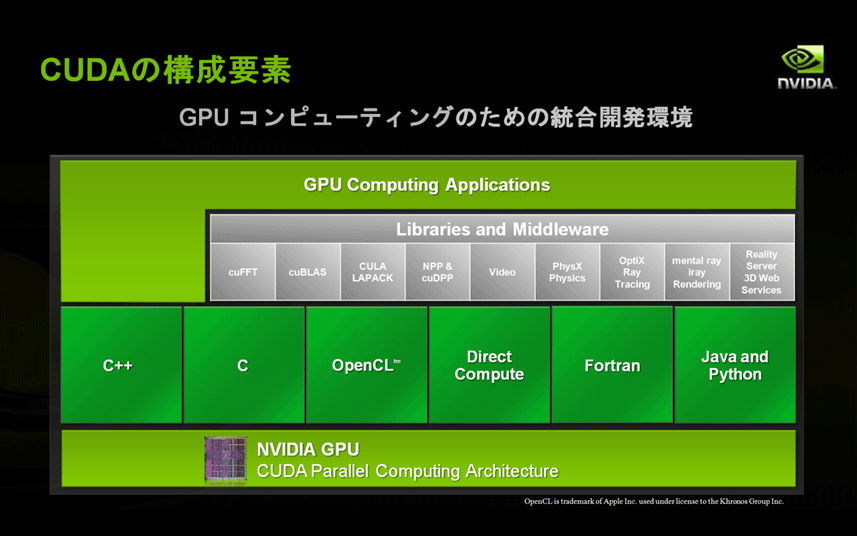
CUDAを構成する主な要素は以下の通りです。
- NVIDIA GPU (G80世代以降のGPU)
- CUDA対応Driver、CUDA Toolkit、CUDA SDK
- "CUDA C"をはじめとするプログラミング言語やDirectComputeなどのAPI
- ライブラリやミドルウエア
- GPUコンピューティング・アプリケーション
|
|
| 図8: CUDAの構成要素(クリックで拡大) |
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
