インテルがAIにフォーカスしたイベント「インテルAI Day」でPreferred Networksとの協業を発表
インテルが人工知能への取り組みをイベントにて解説。しかし最も目立っていたのはPreferred Networksとの協業、そして深層学習フレームワークであるChainerであった。
2017年4月25日 0:00
AI時代のインテルの戦略が一同に
マイクロプロセッサのリーダーであるインテルは2017年4月6日、都内にて人工知能にフォーカスしたイベント、「インテルAI Day」を開催した。近年の人工知能はこれまでのルールベースから、機械学習、深層学習などの様々なアルゴリズムと膨大なデータによって、実用化にむけて大きく進化したことはもう周知の事実だろう。しかしそのシステムに使われているのは、高速な行列計算を多数のコアで並列処理するGPUだ。GPUのリーダーであるNVIDIAが「(NVIDIAは)ビジュアルコンピューティングからAIコンピューティングに移行する」と宣言するほど、GPUは人工知能、それも深層学習に向いたプラットフォームなのである。
しかしCPUの圧倒的リーダーであるインテルが、人工知能のマーケットをGPUが席巻していくことを見過ごすはずもない。このイベントは、CPUのインテルが人工知能においてもリーダーであり続けようとしていることをアピールするための、絶好の機会という位置づけだろう。
冒頭で登壇したのはインテル株式会社の代表取締役社長、江田麻季子氏だ。江田氏は「インテルは増え続けるデータを処理する会社になった」と語り、クラウドとビッグデータの担い手としてインテルが市場をリードすると語った。現時点では、多くのユースケースでGPUによる深層学習がメインとなっていることは周知の事実だが、それでもデータセンターにおけるサーバーのCPUはほぼXeonで寡占されており、その一点をもってすればインテルが「市場をリードしている」という言い方は間違っていない。ここではインテルの戦略として「PCのプロセッサからスマートデバイスのプロセッサ」に移行することが解説された。頭打ちとなっているPCに依存ぜずに、よりマスを取れるデバイスに舵を切ったという意思表明だろう。そしてもう一つの柱がデータセンターであり、単なるサーバーのCPUだけではなくFPGAやXeon Phiなどのプロセッサを充実させるという方向性だ。

インテルの成長戦略はPCからスマートデバイスへ
次に登壇したのは、インテル本社のデータセンター事業本部のBarry Davis氏だ。「インテル+AI 未来の体験の推進」と題されたセッションで、インテルが提供するAIの各種機能が紹介された。ここでは「コンピュータビジョン」のMovidius、「奥行き認識」のREALSENSE、「推論システム」のSaffron、マシンラーニング/ディープラーニングなどが挙げられた。

インテル本社のBarry Davis氏
ここでDavis氏は壇上に日本のディープラーニングのベンチャーであるPreferred Networks(以下、PFN)のCEO、西川徹氏を登壇させた。西川氏はPFNの紹介と、4月6日にPFNとインテルで締結された協業についての簡単な説明を行った。そして、PFNが推進するオープンソースの深層学習フレームワークであるChainerを、インテルのプロセッサに最適化することを発表した。

インテルとPFNの協業でChainerを最適化
西川氏は、PFNのブログ上で発表されているChainerMN(Chainerをマルチノードで分散処理させるフレームワーク)の性能比較を紹介し、機械学習において「学習時間をいかに短縮するか?」が重要なブレークスルーであると紹介した。ここでの重要なメッセージは、ChainerMNが明らかにTensorFlowよりも高速であるという最後のスライドだろう。
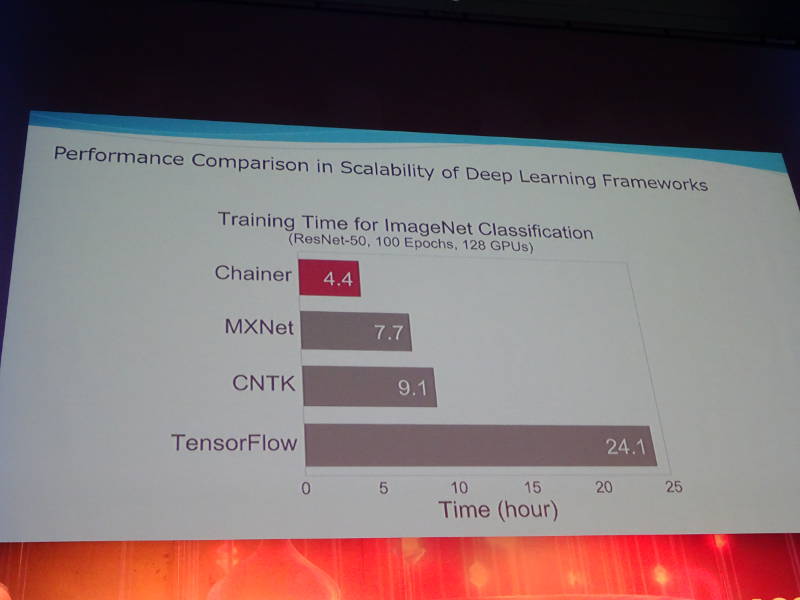
128GPUでの性能比較。TensorFlowが明らかに遅いことを訴えている
PFNのブログ記事にもあるように、一つの例をもってTensorFlowが遅いと決めつけることは危険だが、会場を埋めた参加者にとって強烈なメッセージであったことは間違いない。特にこれから機械学習を始めようと思っている企業のIT部門にとっては、Chainerを記憶に留めるインパクトになったことだろう。
より詳細な情報については、以下のリンクを参照して欲しい。
ハードウェア/ソフトウェアの両面からAIを推進
次に登壇したのは、インテルのデータセンター事業本部AI製品担当のシニアディレクター、Nidhi Chappell氏だ。Chappell氏は、製品担当としてインテルの提供するAI関連製品を紹介した。ここではマシンラーニングと推論システムを大きな2つの区分としてわけ、それぞれに製品を提供するということだろう。特にマシンラーニングにおいては、2016年に買収したNervanaのソリューションを、推論システムには2015年に買収したSaffronのソリューションを提供するという計画だろう。実際にデモブースではSaffronの担当者が解説を行っており、インテルのAI製品ポートフォリオとして位置づけられていることがわかる。

幅広いAIポートフォリオを紹介するChappell氏
Chappell氏は、主にハードウェアの観点からAIに最適なプロセッサの概要を紹介した。ここでは現行のXeonに加えて、将来提供されるLake Crest、Knights Crest(いずれもコードネーム)というプロセッサについても紹介が行われ、機械学習の学習時間を現在の100分の1にする計画を語った。
興味深かったのは、競争相手であるGPUに言及するところがXeon Phiのスライドの一部だけに現れていたところかもしれない。それも「16GB搭載のGPUと比較して最大400GBのダイレクトメモリーアクセスが可能」という部分だけだった点だ。メニーコアプロセッサであるXeon Phiのコア数が最大61であるのに対し、NVIDIAのTesla P40のコア数が3840という部分をみれば、インテルは並列処理が必要不可欠なディープラーニングにおいて、GPUのように多数のコアに処理を分散させるのではなく、Xeonを中心として特別なプログラミングが不要なシステムを推進していくという意思表明だったのかもしれない。

Xeon Phiを紹介するChappell氏
インテルはAI製品技術本部という新しい部門を創設し、そのトップにVP兼CTOとしてAmir Khosrowshahi氏を任命した。インテルにおけるAI製品の技術的リーダーとなったKhosrowshahi氏は、インテルが買収したNervanaの元CTOである。

AI GroupのCTO、Khosrowshahi氏
Khosrowshahi氏は、主にソフトウェアの観点からインテルのAI関連製品を紹介した。ディープラーニングのベンチャーであったNervanaのCTOであったKhosrowshahi氏の役割は、インテルのAIについて技術的な観点から統括するということだろう。
インテルはすでにNervanaをAIのブランディングとして利用するほど、マシンラーニングについてはNervanaの技術を評価しているように思える。また単に製品を開発するだけではなく「Intel Nervana AI Academy」を創設し、AI技術者の育成を行うという。同時にGoogleに買収されたKaggleにも賞金を提供してコンペティションを行い、インテルの外からも積極的にAIの知見を獲得しようという姿勢を見せた。

インテルのAI製品ポートフォリオ
午後に行われた「インテルのAIソフトウェア」と題されたセッションでもKhosrowshahi氏が登壇し、AIの基礎、ディープラーニングの課題などについて解説を行った。ここでKhosrowshahi氏は、ディープラーニングのボトルネックとしてプロセッサにおけるデータの入出力が性能向上を制限する要因となると解説。

従来のGPUではIOがボトルネックになるという
PCI ExpressのチャネルがボトルネックとなるGPUとの比較で、ファブリック的なインターコネクトを実装したXeon Phiの将来モデル、Crestファミリーと呼ばれるプロセッサが、より高速にディープラーニングを実行できると語った。
Crest Familyの概要
ここでもコアの数ではなく、少ないプロセッサでXeonとの互換性を保ちながら高速化するインテルの考え方が垣間見えたと言えるだろう。
多彩なセッション
他のセッションでは東工大の松岡聡教授によるTSUBAME3の概要が解説され、HPC用のスーパーコンピュータであるTSUBAME3をAI及びビッグデータ用に再構築するプロジェクトが紹介された。ディープラーニングやビッグデータに最適なコモディティハードウェアを使ったスーパーコンピュータを、ソフトウェア及びハードウェアの仕様を公開して実装するリサーチがすでに進んでいることが紹介された。
ここではCPUとGPUを高速なチャネルで接続し、高速かつ高密度なコンピュートユニットが構成されていることや、それを実装したラックの消費電力が6万ワットに達すること、そしてそれを冷やすための工夫などについて解説が行われた。
セッションの中で興味深かったのは、ディープラーニングを使ったコンピュータ将棋に関するもので、すでに人間の名人に連勝しているソフトウェアを開発しているHEROZ株式会社の代表取締役、高橋知裕氏とリードエンジニアの山本一成氏の講演だ。Ponanzaの名前ですでに知られているAIを使った将棋プログラムだが、ディープラーニングを使うことで将棋にある禁じ手をロジックとして組み込む必要がなくなったこと、人間では考えもつかないような指し手をAIが見つけるようになったことなどが紹介された。オンライン将棋として、すでに2億回も対戦を経験しているという。山本氏によれば、プロ将棋の世界ではAIが人間を超えるタイミング、つまりシンギュラリティはすでに訪れており、意外にもそのことをプロの棋士たちは受け入れていると語った。ここでも開発に利用されているとしてChainerが紹介され、PFNのChainerの優秀さが垣間見えた瞬間であった。

将棋の世界ではすでにシンギュラリティを超えたと語るHEROZの山本氏
午後のセッションに登壇したPreferred Networksの知的情報処理事業部の事業部長である海野裕也氏は「深層学習フレームワークChainerとその進化」と題されたセッションで、Chainerの最新動向を紹介した。ここでもTensorFlowとの違いを紹介し、進化の速い深層学習においては「古い手法では新しい理論に対応できず自由度が制限される」と解説し、2015年のほぼ同時期に公開されたChainerとTensorFlowの違いを強調した形となった。
またインテルのCPUに特化したChainerを公開することは、PFNからみればインテルのCPUがChainerを動かす選択肢の一つとして加わったという意味合いとなるだろう。

ChainerとTensorFlowの違いを紹介する海野氏
今回のイベントでは、インテルが自社のプロセッサだけではなく、買収した様々な企業による技術を活用してAIの最前線でも戦っていこうという姿勢を見せたイベントであった。しかし最も効果的に技術の優秀さを示したのはPFN、そして深層学習のフレームワークであるChainerであったように思える。インテルのプロセッサに最適化されたChainerが、どのような性能を発揮するのか、今後の進化を見守りたい。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
