CUDAとGPUコンピューティングの広がり
CUDAの普及2006年にG80世代のGPUとともに発表されたCUDAは、当初は大学や独立の研究機関などを中心に、新しい計算手法あるいは計算の加速方法として注目を受け始めました。研究者や専門家の皆さんが自らの研究課題をCUDA Cを使ってプログラミングすることにより、これまで数日間かけて行っていた計
2010年7月30日 20:00
CUDAの普及
2006年にG80世代のGPUとともに発表されたCUDAは、当初は大学や独立の研究機関などを中心に、新しい計算手法あるいは計算の加速方法として注目を受け始めました。
研究者や専門家の皆さんが自らの研究課題をCUDA Cを使ってプログラミングすることにより、これまで数日間かけて行っていた計算内容を数時間に短縮することが可能になりました。
また、GPUの高い計算能力が新たな研究課題への取り組みを可能にし、GPUコンピューティングの学術研究目的への利用が広がりました。
その研究成果は各専門分野の学会やNVIDIAのCUDAゾーンなどでも公開されてきました。
このような状況の中で、2008年にCUDAの利用方法について、1つの転機が訪れました。
2008年6月に米Elemental Technologiesが発表した「BadaBOOM Media Converter」のトランスコーディングがCUDAで最適化されたり、2008年8月に株式会社ペガシスが「TMPGEnc 4.0 XPress」でフィルタリングをCUDAで最適化したことなど、一般消費者向けビデオ・エンコード・ソフトウエアがその発端でした。
米Elemental TechnologiesのCEO、サム・ブラックマン(Sam Blackman)氏は次のように述べています。
「世界中の多くのユーザーは、YouTubeなどのビデオ共有サイトへの投稿や、iPodなどの人気のメディア・プレーヤへのダウンロードを行うため、ホーム・ビデオを変換するのにどれほど時間がかかるかを知っています。Elementalは、2008年8月に提供開始予定の一般消費者向けビデオ・アプリケーション、BadaBOOM Media Converterを開発しました。GeForce GPUの超並列汎用コンピューティング・アーキテクチャを活用することで、CPUのみを実装したシステムの18倍のスピードで、高品質ビデオを変換することができます。この比類のない性能向上は、当社のRapiHD Video PlatformがNVIDIA GPUの活用を念頭に開発されたことによります」
それは、これまでのような専門家が自らプログラミングすることによるCUDAの利用だけではなく、一般消費者が表面的にはアプリケーションを使用するだけで、間接的にCUDAを利用することができ、GPUコンピューティングの恩恵を得ることができるという最初の実例でした。
ビジュアル・コンピューティングのメガイベント"NVISION08"
このような動きに合わせて、2008年8月下旬に米国サンノゼで開催された"NVISION 08"は、NVIDIAが従来から推進してきたビジュアル・コンピューティングの発展とともに、GPUコンピューティングの現状と今後の可能性を世の中に示すものでした。
このイベントは、ノンストップLANパーティ・ゲームのギネス世界記録達成など、さまざまな意味で話題になりましたが、特に閉会セレモニーの中で行われた、米国のTV番組"MythBusters"でおなじみのJamie HynemanとAdam Savageによる、GPUの並列プロセッシングのデモは、世界中で注目を浴び、その後日本の主要民間テレビ放送局のゴールデンタイムでも何度か取り上げられました。
内容は、ペイント・ボールと呼ばれる何色かの塗料の入ったボールを1102個の銃から同時に発射することにより、瞬時にモナリザの絵を完成させるというものです。
|
| 図1: テレビで放映されて注目を集めたGPUによる並列プロセッシングのデモ(クリックで拡大) |

当時のNVIDIA主席研究員(現NVIDIAフェロー)デービッド・カーク(David B. Kirk)が、このイベントの初日に行ったキーノート・スピーチの最後に登場する、"CUDA Everywhere !" という言葉は、CUDAとGPUコンピューティングが学術研究用途から産業界、一般消費者の日常的な使用へと用途が拡大していく状況を象徴するものでした。
DirectComputeによるCUDAの暗黙的な利用
さらに、2008年11月に発表されたDirectCompute は、DirectX 10世代以降のGPUに対応したWindows のGPUコンピューティング用 APIとして、CUDAの一般利用への広がりをさらに加速しました。
例えば、GPUコンピューティングやIT全般にあまり詳しくない人がいて、Windows 7とNVIDIA のGPUが搭載されたパソコンを趣味で使用しているとしましょう。
そんな彼は、普段からDirectXの存在すら意識したことがなく、「DirectCompute」という言葉を伝えても、「直接計算するなら電卓だよ」、といわれるだけかもしれません。
しかし、もし彼が自分で録画したHDTV(高精細テレビ)のビデオ・クリップを普段持ち歩いている携帯用ビデオ再生機器に取り込むためにパソコンに接続し、ビデオ・クリップをその携帯機器に「ドラッグ&ドロップ」して、コピーが即座に完了したとしたら、その時点で彼はCUDAとGPUコンピューティングの利用者の仲間入りしたことになります。
なぜなら、この場合に「ドラッグ&ドロップ」によって発生する内部処理は、単なるファイルのコピーではなく、GPUコンピューティングを使用したトランスコード(ビデオ・フォーマットや解像度の変換)がコピーと同時に自動的に行われているからです。
「ドラッグ&ドロップ」の操作により、まずDirectComputeのAPIが呼び出され、CUDAプラットフォームを経由して、コンピュート・モードへの切り替えの命令がGPUに伝達されます。
例えていえば、それまでグラフィックスのハッピを着て、低周波数クロックで地球環境保全に貢献しながら、デスクトップ画面のアップデートの仕事を軽く受け流していたかもしれないシェーダたちは、切り替えの命令を受けたとたんに、クロック周波数を通常状態に戻しながら気合を入れ直し、即座にコンピュート用のジャケットに着替え、降り注ぐスレッドの数々をチームワークよく分担しながら一心不乱に処理し続けます。
外界では「ドラッグ&ドロップ」が終わり次の作業に入ろうとしているころには、HDフォーマットのビデオ・クリップが、ターゲットである携帯用ビデオ再生機器がサポートするフォーマット(例えば、低解像度のH.264)に既に変換され終わり、仕事を終えたCUDAコアたちは、元の地球に優しい状態に戻っています。
|
| 図2: CUDAのシステム・アーキテクチャ(クリックで拡大) |
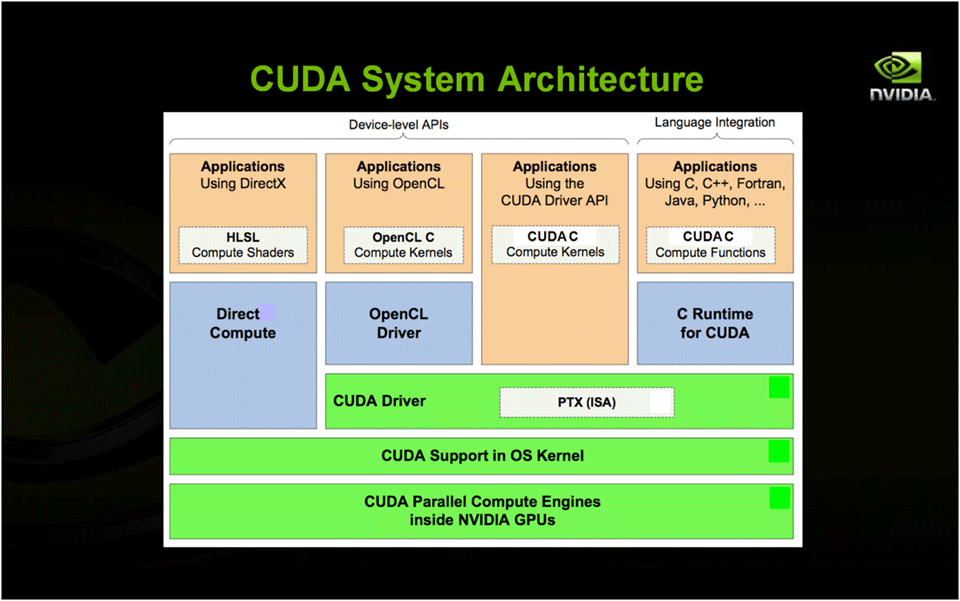
CUDAといえば、CUDA Cによるプログラミングだけが注目されがちですが、それはあくまでもCUDA GPUコンピューティングの1つの入り口でしかありません。
DirectComputeに限らず、GPUコンピューティングを支えるインフラストラクチャとして、CUDAの役割や利用方法は日々進化しています。
CUDA の現状
CUDA Cによるプログラミング以外の、CUDAの使用例としてDirectComputeを取り上げましたが、ここでCUDAの現状とその全体像を整理してみましょう。
- CUDA対応GPUの普及
- G80以降出荷されたすべてのGPUがCUDAに対応
- これまでのCUDA対応GPUの出荷数は、全世界で2億個以上
- 標準APIへの対応
- DirectCompute
- プログラミング言語の対応
- CUDA C/C++、CUDA Fortranなど
- 業界標準プログラミングの推進
- OpenCLの早期対応と標準化への貢献
- コンピュート用ライブラリの充実
- CUFFT、CUBLAS、
- 各種アクセラレーション・エンジン(SceniX 、CompleX、OptiX、PhysXなど)
- 各種ISVアプリケーションのCUDA化の推進
- 生物化学系、映像処理系、金融系、設計支援ツール
- デバッグ環境の充実
- Windows Visual Studio 環境で動作するParallel Nsight
- Visual Profiler
- Linux上で動作するcuda-gdb
- スケーラビリティと互換性
- ラップトップPCから、HPC用のTesla製品まで同一のアーキテクチャ
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
