並列コンピューティングの必要性
ムーアの法則の限界について、最近いろいろな議論がなされ始めています。
NVIDIAの主席研究員ビル・ダリー(前スタンフォード大学コンピュータ・サイエンス学部長)も"forbes.com"で述べているように、ムーア(Gordon Moore)は、45年前に書いた論文の中で 「半導体集積回路上のトランジスタ数は18カ月ごとに2倍になる」と予測しています。
また、この予測が次の予測「トランジスタ数が2倍になることにより、CPUの処理能力も18カ月ごとに2倍になる」の基になっています。
確かに、1980年代から90年代にかけて、この予測は真実でした。製造業の技術革新から、サービス業やメディア産業の発展、さらには電子商取引、社会全体のネットワーク化とモバイル機器の発達といった新規ビジネスにいたるまで、経済全般にわたって、ムーアの法則は生産性の向上に寄与してきました。
実は、CPU処理能力の向上は、ムーアの論文の中でこれまであまり注目されてこなかった、もう1つの予測に支えられていました。それは「集積度が向上するにつれて、それぞれの演算ユニットが消費するエネルギーは減少する」というものであり、結果としてトータルの消費電力は一定となり、消費電力の増加なしに処理能力の向上が得られる、ということでした。
しかし、ここ数年の状況は、消費電力に関するこの予測が完全に崩れていることを示しています。クロック周波数の大幅な増加はありえず、したがってCPUの1つのコアの処理能力が18カ月で2倍になることも、もはやありません。
そこで、今後の経済の成長や産業の革新を支えるプラットフォームを提供する技術として注目を浴びているのが、並列コンピューティングなのです。
デュアル・コアに始まったCPUの複数コア化は、まさにこの事実を裏付けるものといえます。
TOP500サイトのCPUの推移
具体的な例として、2010年6月のTOP500リストにランクインしている500のスーパー・コンピュータ・サイトで使用されているCPUを調べてみると、以下の事実がわかります。
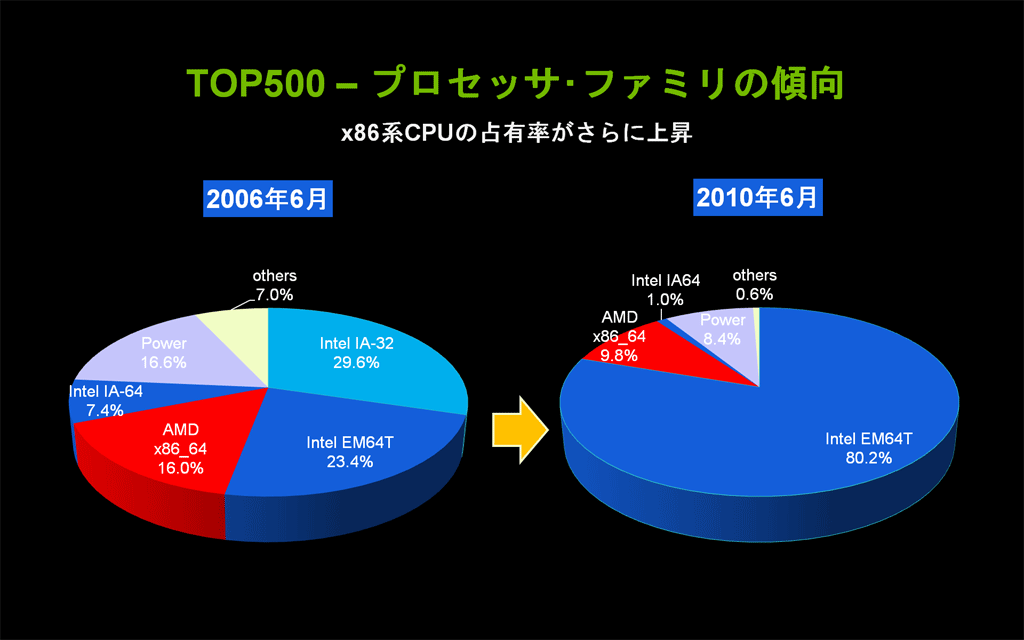
- 2000年以降の傾向として、HPC専用のベクトル型プロセッサから汎用プロセッサを使用した超並列スカラー型への移行トレンドがさらに進んでいる。1位の米国オークリッジ国立研究所や2位の中国シェンツェン国立スーパー・コンピュータ・センターを含め、90%以上のサイトがx86系のCPUを使用している。
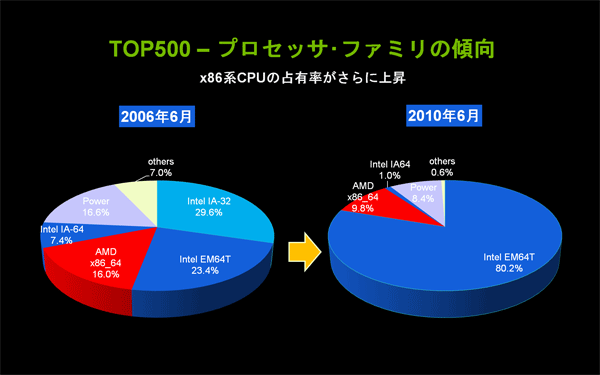
図1: TOP500サイトで使われているCPUの傾向(クリックで拡大) - x86系CPUの1コアあたりの浮動小数点演算処理性能は、2006年以降にTOP500スーパー・コンピュータ・サイトに採用されたCPUを見る限り、一定値が保たれており、向上していない。
- 2006年以降、TOP500サイトに採用されているCPUの演算処理性能の向上は、すべてコア数の増加によるものである。
- 2008年にTesla T10 GPUを680個搭載した東京工業大学のTSUBAME1.2に続き、Fermi 世代Tesla T20 GPU「C2050」を4640個使用した中国シェンツェン国立スーパー・コンピュータ・センターが2位にランクインし、同じく「C2050」を2200個搭載した中国科学アカデミーが19位にランクインした。

図2: TOP500サイトにおけるCPU演算処理性能の推移(クリックで拡大)
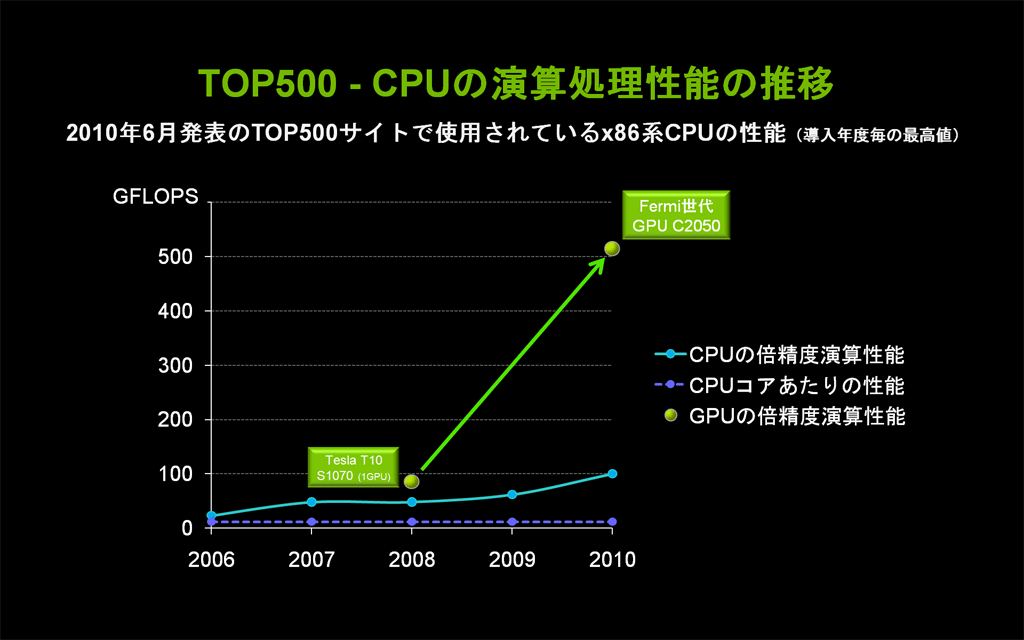
このように、スーパー・コンピュータの世界では、数年前から、汎用機器(コモディティ)を利用した並列コンピューティングへの移行の波が押し寄せています。そして、第2波となるべき次の飛躍を担う技術として期待されているのが、CPUとGPUによる複合並列コンピューティングなのです。
また、この波は、さまざまな基礎研究だけでなく、メディア産業、医療、製造業をはじめとする各種産業、および個々人の娯楽や生活の中にまで波及するものとして期待されています。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
