3. 高可用性クラスタ
3. 高可用性クラスタ
高可用性クラスタは、数あるクラスタ技術の中でも、比較的よく使われるものです。いろいろな実装方法があり、それによって機能も異なります。
3.1. 共有ディスクを用いたコールド・スタンバイ型
図1に、共有ディスクを用いたコールド・スタンバイ型の構成を示します。
|
|
| 図1: 共有ディスクを用いたコールド・スタンバイ型HAクラスタ |

共有ディスクを用いたコールド・スタンバイ型は、最も多く使われている高可用性クラスタです。データベースは、「共有ディスク」に格納します。共有ディスクとは、複数のサーバーから読み書きできるようになっているストレージです。
この方式では、現用系(ACTと呼ばれることがあります)と呼ばれるサーバー1台が、共有ディスクを使ってデータベースを運転します。サーバーが障害などでクラッシュすると、もう1台(予備系、SBYと呼ばれることがあります)が共有ディスクを引き継いで、データベースの運転を継続します。
この方式の利点は、データベース自身に高可用性の機能がない場合でも、外部のミドルウエアで高可用性の機能を持たせることができることです。
一方、デメリットは、データベース・サーバーのクラッシュを検出することや、共有ディスクの修復に、時間がかかってしまうことです。また、予備系サーバーが共有ディスクを引き継ぐ際に、現用系のサーバーが共有ディスクを使っていないことを確認する手段が必要になります。また、現用系を運用している間は、予備系がアイドル状態になってしまいます*1。
- [*1] 複数のサーバーが互いの予備系になるような、「相互待機」という構成もあります。この場合、障害発生時には、複数の機能を1つのサーバーで提供することになります。
共有ディスクが単一障害点にならないようにするには、共有ディスク自身のハードウエアを適切に構成する必要があります。
この方式の注意点は、ほとんどの場合で、現用系がクラッシュした時点で実行中のトランザクションが失われてしまうことです。
3.2. 共有ディスクを用いた同時マウント型
共有ディスクを用いた同時マウント型の代表は、米Oracleのデータベース・クラスタ「Oracle Real Application Clusters」(Oracle RAC)です。
上述した、共有ディスクを用いたコールド・スタンバイ型と同様、共有ディスクにデータベースを蓄積し、複数のサーバーで同時にマウントしてデータベースの運転を行います。SQLは、どちらのサーバーでも処理できます。一方のサーバーがクラッシュしても、無停止で、もう片方のサーバーで運転を継続できます。図2に、その概要を示します。
|
|
| 図2: 共有ディスクを用いた同時マウント型HAクラスタ |
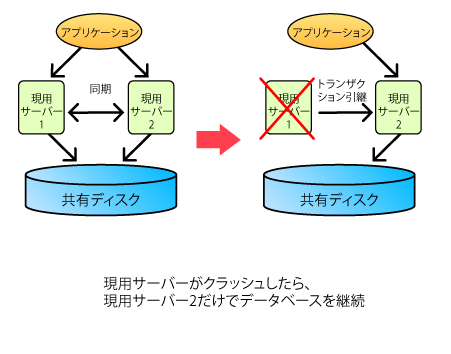
この方式では、クラッシュしたサーバーで実行していた最中のトランザクションを、もう一方のサーバーで引き継ぐことも可能です。
共有ディスクを用いたコールド・スタンバイ型と同様、共有ディスクが単一障害点(Single Point Of Failure: ここが故障するとシステム全体が故障してしまう要素)にならないようにするには、共有ディスク自身のハードウエアや構成を適切に行う必要があります。
3.3. シングル・マスター型
シングル・マスター型の構成では、共有ディスクは必須ではありません。2つ以上のサーバー(ここでは2つの例で説明します)のうち、1つをマスター、そのほかをスレーブとして動かします。図3に、その概要を示します。
|
|
| 図3: シングル・マスター型HAクラスタ |

シングル・マスター型HAクラスタの場合、SQL文は、マスターがすべて処理します。スレーブには、データベースの更新情報だけが転送されます。スレーブは、データベースの内容を、マスターと同じ状態に保ち続けます。マスターがクラッシュすると、マスターの代わりにスレーブが、データベースの機能を提供するようになります。
シングル・マスター型は、更新情報の送信の仕方により、さらにいろいろな種類に分けることができます。
マスターからスレーブに送信する更新情報として、以下の3つのいずれかが主に使われます。
- 更新するSQL文
- トリガーなどで抽出した、テーブルの行レベルの更新情報
- リカバリに用いる、低水準のデータベース更新ログ
(a)「更新するSQL文」と(b)「トリガーなどで抽出した、テーブルの行レベルの更新情報」の場合、更新情報を受け取るスレーブ側では、通常のデータベースの運転を続けることができます。つまり、スレーブでも通常のSQL文を処理することができるのが、大きな特徴です。
データベースの一貫性が問題にならないのであれば、スレーブでも更新SQLを処理することができることはメリットです。高可用性とは少し離れますが、このような機能が必要なアプリケーションには有効です。
(a)「更新するSQL文」の場合、実際には、マスター側でも複数のSQL文を同時に実行しています。したがって、SQL文を単純にスレーブに送るだけでは、データベースを同期できません。マスターとスレーブで同じ実行結果を得るためには、いろいろな工夫が必要です。これは簡単ではありません。
また、(a)「更新するSQL文」と(b)「トリガーなどで抽出した、テーブルの行レベルの更新情報」では、SQLや行レベルのデータをスレーブに送ることになるので、「システム・カラム」と呼ばれるデータ(これは、DBMSにより異なります)が、マスターとスレーブで、それぞれ違った値になることがあります。
(c)「リカバリに用いる、低水準のデータベース更新ログ」の場合、マスターからスレーブに送られる情報は、(c1)「データベースのリカバリに使う情報」だったり、(c2)「データベースを格納するファイル・システムそのものの更新情報」だったりします。
(c1)「データベースのリカバリに使う情報」を用いる場合、スレーブは、マスターから送られる情報を使って、データベースをリカバリし続けることになります。リカバリは、データベースの通常動作の前に行われるので、このままでは、スレーブはSQL文を処理できません。しかし、参照に限ってSQLの処理を可能にした実装もあります。
また、(c1)「データベースのリカバリに使う情報」を用いる場合は、マスターとスレーブで「システム・カラム」を同じ値にすることができます。
(c2)「データベースを格納するファイル・システムそのものの更新情報」を用いる場合、データベースを格納しているファイル・システム全体のコピーを、常に取り続けることになります。
シングル・マスター型のクラスタで重要になるファクタには、もう1つ、更新情報を送るタイミング、という要素があります。これは、大きく、(A)同期型と(B)非同期型に分けることができます。
(A)同期型とは、更新情報をスレーブに送ったことを確認した後で、マスターの更新を行うものです。(B)非同期型とは、マスターの更新を行った後で、更新情報をスレーブに送るものです。更新情報の到達確認は、行うものも、行わないものもあります。
(A)同期型では、更新情報は、確実にスレーブに届きます。マスターがクラッシュしても、更新情報が失われることはありません。一方、(B)非同期型では、マスターがクラッシュした場合、更新情報が失われる可能性があります。
いずれの場合も、マスターがクラッシュすると、スレーブがマスターになって、データベースの機能を提供します。しかし、マスターで実行中のトランザクションは、失われてしまうのがほとんどです。
シングル・マスター型でも、スレーブのサーバーに参照用のSQLを処理させることは可能です。しかし、マスター・サーバーの変更結果がスレーブ・サーバーに反映されるまでには、短時間ですが時間差があります。このため、厳密に最新の情報が必要な場合には、マスター・サーバーにSQLを処理させる必要があります。
3.4. マルチマスター型
マルチマスター型では、図4に示すように、複数のサーバーがそれぞれSQLを処理する一方で、更新の結果も相互に同期させるものです。障害時には、クラッシュしたサーバーを切り離すだけで、データベースを継続させることができます。相互に更新情報の同期をとる必要があるので、実現はシングル・マスターより困難です。
|
|
| 図4: マルチマスター型HAクラスタ |

- この記事のキーワード
バックナンバー
この記事の筆者
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
