データ連携の仕組みとススメ方
データ連携に必要な手順と要素と機能前回は、クラウドコンピューティング(以下、クラウド)時代のデータ連携の理解を深めるために、これまでのデータ連携やアプリケーション統合技術について再確認をしました。連載2回目となる今回は、「データ連携を実現するために必要な要素と機能」、そして「現在利用されている汎用
2011年8月10日 20:00
データ連携に必要な手順と要素と機能
前回は、クラウドコンピューティング(以下、クラウド)時代のデータ連携の理解を深めるために、これまでのデータ連携やアプリケーション統合技術について再確認をしました。
連載2回目となる今回は、「データ連携を実現するために必要な要素と機能」、そして「現在利用されている汎用的な技術には、どのようものがあるのか」ということについて紹介していきたいと思います。
データ連携は、異なる言語を通訳する仕組みを例として考えると理解しやすくなります。実際の通訳の流れがどのようになっているかを見てみると、次のようになります。
- 話し手の話を聞く
- 話の内容を理解する
- 聞き手が理解できる言語に翻訳する
- 聞き手に伝える
これをデータ連携に置き換えてみると、次のようになります。
- データを受信する
- データをパース(解析)する
- データを変換する
- データを送信する
では、それぞれの工程について、さらに詳細に見ていきましょう。
データを受信・送信する
データの送受信を行う際の通信手段として利用するのが「転送プロトコル」です。翻訳の際にも、口頭で言葉を伝えることもありますが、それ以外にも電話やメール、ビデオ会議など、言葉を伝えるのにもさまざまな手段があり、話をする相手の都合や場所によって、通信手段も変わってきます。
データ連携も同様に、さまざまなプロトコルを用います。企業内でSAPやPeopleSoftといったアプリケーション固有のプロトコルを利用する場合もありますが、汎用的なプロトコルを利用して遠隔地やクラウドサービスとやり取りをするケースが多くなります。皆さんすでにご存じのものばかりだと思いますが、汎用的な通信プロトコルとしては次のようなものがあります。
- HTTP
- FTP
- MOM
- SOAP
- JDBC、ODBC
など
データをパースする
データを連携させるためには、どんな言語で話をするのかを知っておかなければなりません。そのため、どのようなフォーマット(データ形式)でデータをやり取りするのかを、事前に理解して(決めて)おく必要がありますが、XML文書でやり取りをする場合は、タグと属性に対応した構文を解析(パース)することで、内容の妥当性を検証すると同時に、解析結果を簡単に取り扱うことができるようになります。
データを変換する
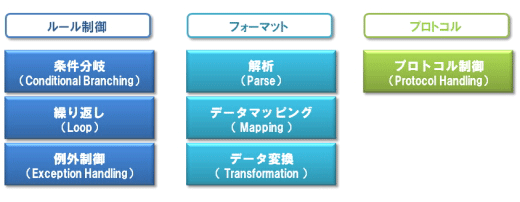
データ変換を行う際、肝となるのが「ルール制御」機能です。
「ルール制御」とは、受け取ったデータの種類や状態によって処理を「条件分岐(Conditional Branching)」して、必要な変換処理などを「繰り返し(Loop)」、エラー処理や管理を行うための「例外制御(Exception Handling)」を行う機能です。
データ連携にこのような「ルール制御」が必要となるのは、必ずしも変換が必要なデータだけがアプリケーションから転送されてくるわけではないからです。別な言い方をすれば、データ変換に必要なデータを生成・加工する機能やプログラムをアプリケーション側に追加するというのは非効率であり、データ連携の関係が「1対1」の場合はまだしも、「1対多」、「多対多」の関係になれば、追加機能の開発や管理はとても複雑になってしまいます。
そこでデータ連携には、そのような複雑さを吸収し、排除する役割が求められます。
次に、データの変換を行うことになりますが、これはまさに翻訳にあたる機能です。しかし、データ連携でも翻訳でも、機械的に単語を「AからBへ」と翻訳するだけでは相手が理解できる言葉にはなりません。それぞれの言語特有の文法や言い回しを理解しながら、単語ではなく言葉として翻訳していかなければならないからです。
そのためには、まず正しいデータフォーマットでデータが転送されてきたかを「解析」して、あらかじめ指定されている「データマッピング」のテーブル情報に従って「データ変換」を行います。「データ変換」の際には、例えば「和暦」を「西暦」に翻訳したり、転送されてきたデータには含まれていない情報を付加したりする処理も行われます。
データ連携の仕組みを構築するためには、このような要素と機能を実装する必要があります。
|
| 図1-1:データ連携の要素 |

|
| 図1-2:データ連携に必要な機能 |
この記事をシェアしてください
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
