ストレージアカウントの作成
ストレージアカウントの作成
HDInsightはデフォルトのファイルシステムとして、HadoopのHDFSではなく、AzureのBLOBストレージを利用します。そのため、HDInsightのクラスターを作成する前に、ストレージアカウントを作っておきましょう。
また、残念ながらHDInsightはまだ日本リージョンで利用できませんので、東南アジアリージョンを利用してください(事務局から公開される「解析対象ファイルセット」も東南アジアリージョンのストレージアカウントに配置されます)。
作成手順は次の通りです。
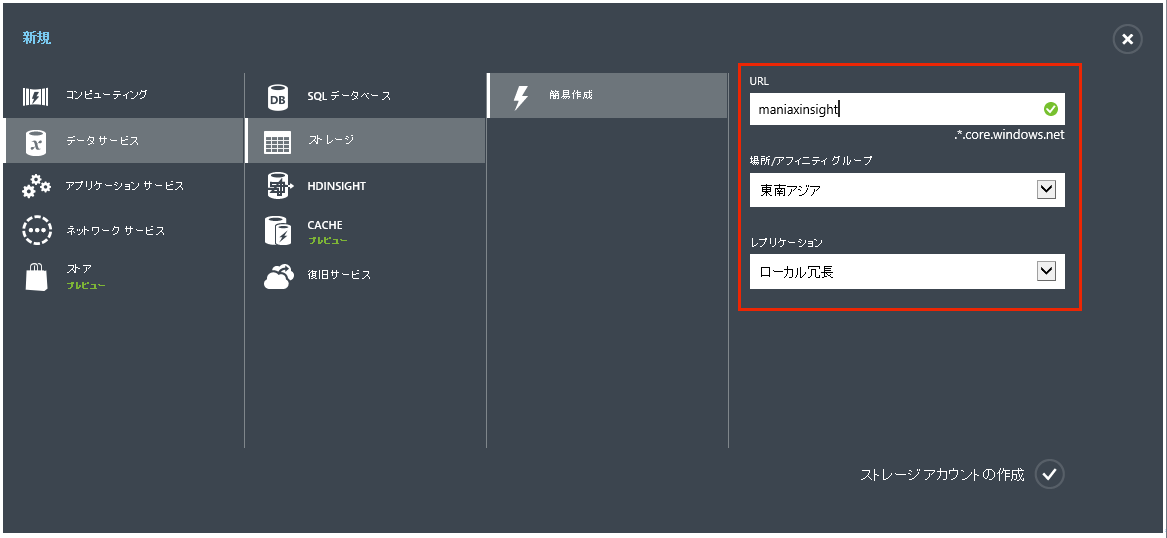
- 1. Azure管理ポータルで「新規」→「ストレージ」→「簡易作成」とクリックし、必要事項を記入します。
- 「URL」: 任意の名前を指定します。
- 「場所/アフィニティグループ」: 「東南アジア」を指定します。
- 「レプリケーション」: デフォルトのままでも構いませんが、「ローカル冗長」にすると少しお安くなります。
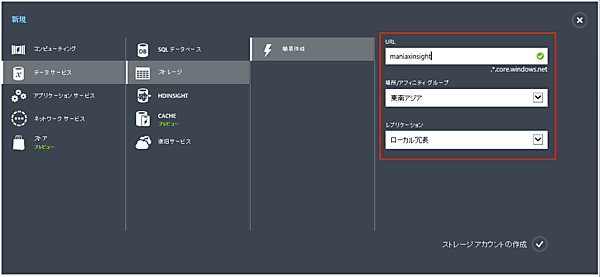
- 2. 「ストレージアカウントの作成」をクリックします
クラスターの作成
ストレージアカウントの作成が完了したら、HDInsightクラスターを作成しましょう。
作成手順は次の通りです。
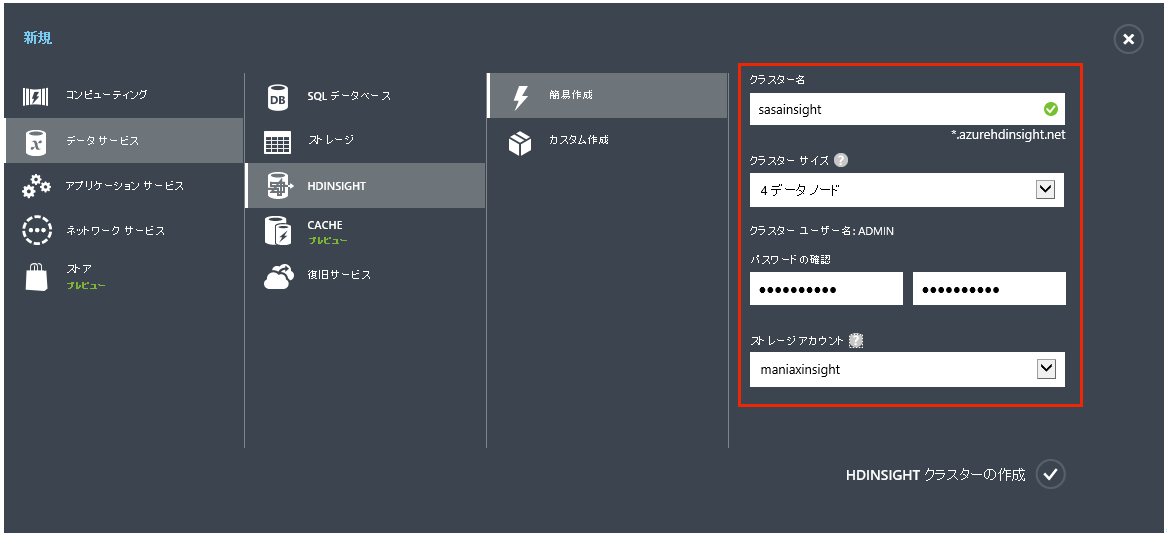
- 1. Azure管理ポータルで「新規」→「データサービス」→「HDINSIGHT」→「簡易作成」とクリックし、必要事項を記入します。
- 「クラスター名」:これから作成するクラスターの名称を決めます。
- 「クラスターサイズ」:データノードの数を指定します。サイズはA3(L)サイズ固定です。
- 「クラスター ユーザー名」: これは簡易作成する場合”ADMIN”に固定されています。
- 「パスワードの確認」: ADMINユーザーのパスワードです。最低10文字必要です。
- 「ストレージアカウント」: 先ほど作成したストレージアカウントを指定します。ストレージアカウントと同じリージョンに、HDInsightのクラスターも作成されます。
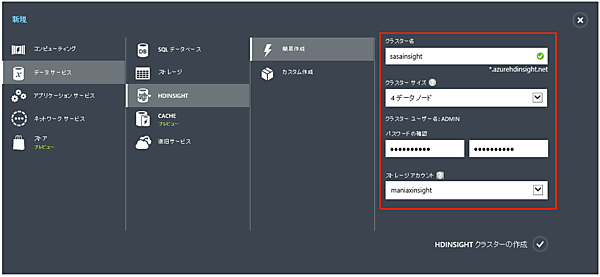
- 2. 「HDINSIGHTクラスターの作成」をクリックすると、クラスターの作成が始まります。
リモートデスクトップの有効化
HDInsightへのジョブ投入は、Azure PowerShellを使ってリモートに行うことができますが、リモートデスクトップを有効化しておくとHadoopのネームノードに直接ログオンしてhadoopやhiveコマンドを使うこともできます。何かと便利ですから、とりあえず有効にしておきましょう。
手順は次の通りです。
- 1. Azure管理ポータルでHDInsightクラスターを選択し、「構成」タブで「リモートを有効にする」をクリックします。
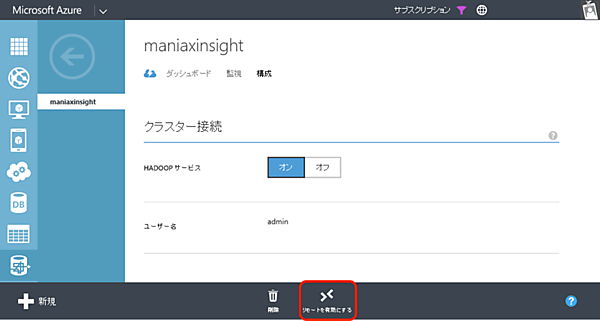
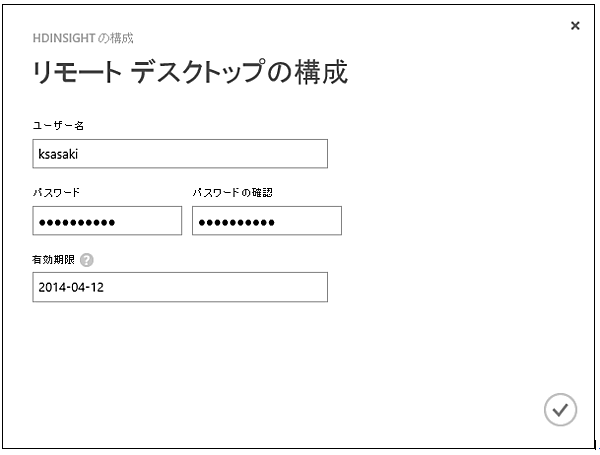
- 2. 「リモートデスクトップの構成」画面でユーザー名・パスワード・有効期限を設定します。なお、ここで指定する「ユーザー」は、クラスター作成時に指定する管理者とは別の「リモートデスクトップ接続専用のユーザー」です。
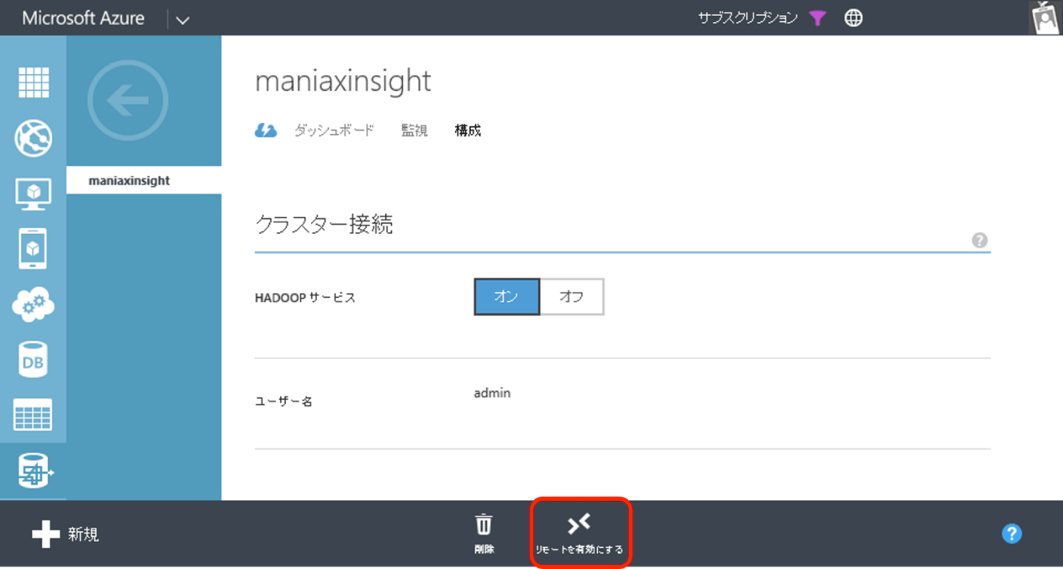

以上です。設定は数分で有効になります。
「接続」をクリックすると、リモートデスクトップ接続ファイルが降ってきます。これを使ってログオンすると、HDInsightがWindows Server 2012 R2で動いていることがわかります。
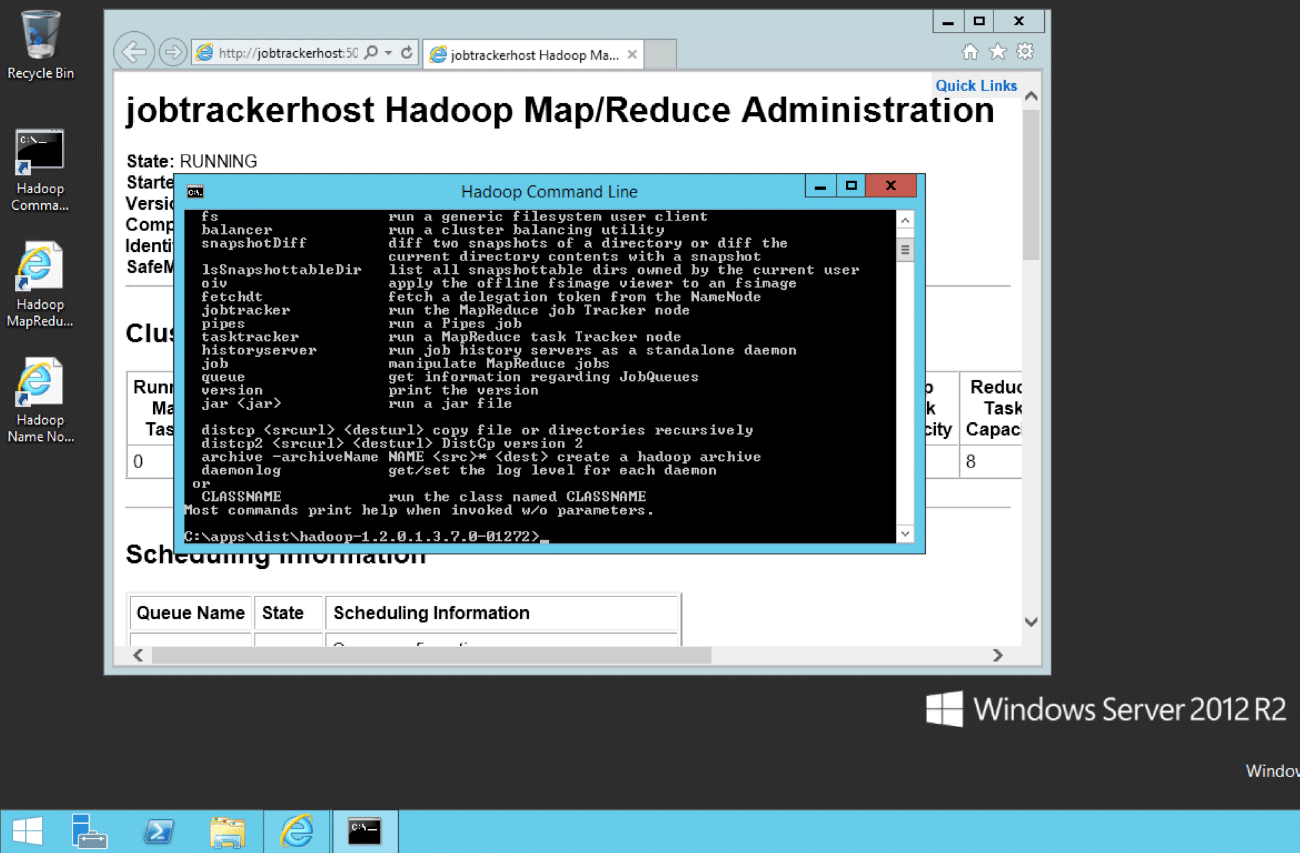
なお、このようにネームノードにログオンして自由にhadoopコマンドを使うことができるのですが、一つ気を付けていただきたいことがあります。HDInsightのノードは、すべてAzureの「Workerロールのインスタンスである」という点です。
Azureをご利用の方ならご存知の通り、Workerロールのインスタンスストレージは、BLOBに永続化されない一時的なディスクです。Azure側のメンテナンス作業などのタイミングで、内容がクリアされてしまうことがありえます。
そのため、例えばネームノード上でジョブ実行用のバッチファイルを作成したりするのはおすすめできません。
サンプルジョブの実行
最後に、HDInsight上でのジョブ実行方法をご紹介します。HDInsightでは、/example/jars/hadoop-examples.jar にいくつかサンプルプログラムが含まれています。
中でも最も基本的で、「MapReduceのHelloWorld」ともいえるWordCountプログラムを実行してみましょう。テキストファイルに含まれる単語の出現回数を計測するものです。
題材としては、これもHDInsightにあらかじめ用意されている、/example/data/gutenberg/davinci.txtを利用し、計測結果は/out/wordcountへ出力するものとしましょう。
手順は次の通りです。
- 1. Azure PowerShellを起動します。
- 2. Get-AzureHDInsightClusterを実行して、先ほど作成した自分のHDInsightクラスターの名前を確認しておきましょう。
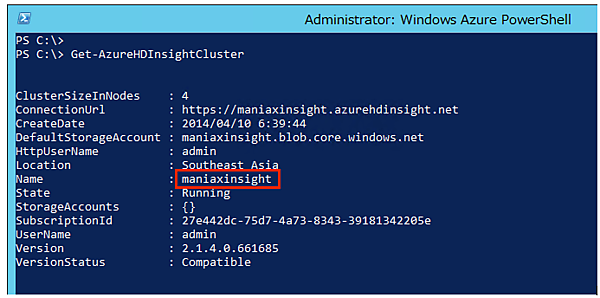
- 3. 次のコマンドを実行します。クラスター名は前の手順で確認した名前を指定します。
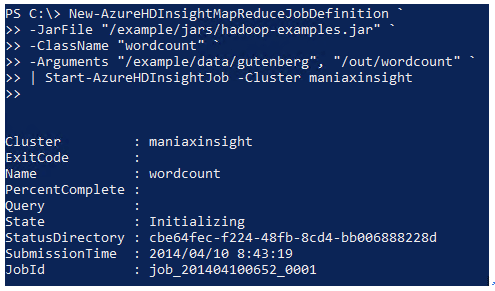
New-AzureHDInsightMapReduceJobDefinition ` -JarFile "/example/jars/hadoop-examples.jar" ` -ClassName "wordcount" ` -Arguments "/example/data/gutenberg", "/out/wordcount" ` | Start-AzureHDInsightJob -Cluster クラスタ名
※PowerShellでは`(バッククォート)が継続行記号です。 - 4. ジョブが投入されると、このような情報が返ってきます。この時点ではまだジョブが走り出しただけであって、完了したわけではありません。
- 5. ジョブの状況を確認してみます。クラスター名とジョブIDを指定して、次のようにコマンドを実行します。
Get-AzureHDInsightJob -Cluster クラスター名 -JobId ジョブID
どうやらジョブは完了しているようです。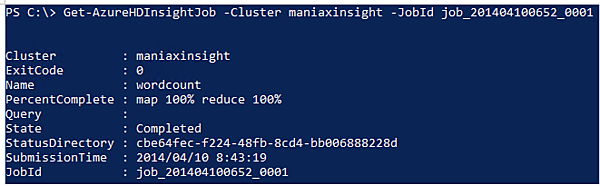

では、出力結果を見てみましょう。先ほどインストールしたストレージクライアントツールで、/out/wordcountを見てみます。
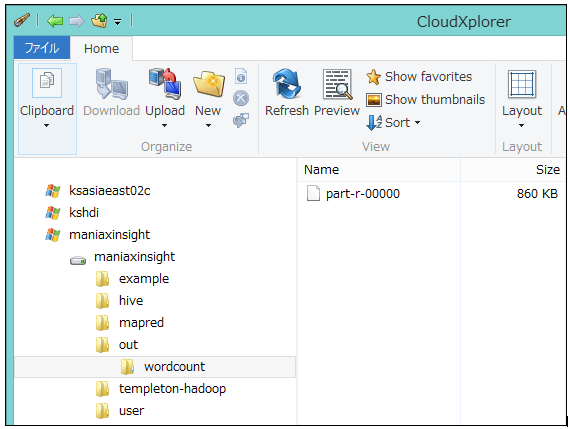
part-r-00000 というファイルが確認できると思います。これが、MapReduceのReduceフェーズの結果として生成されたファイルです。開いてみると、単語とその出現回数が淡々と記録されていることがわかります。
"(Lo)cra" 1
"1490 1
"1498," 1
"35" 1
"40," 1
"A 2
"AS-IS". 1
"A_ 1
"Absoluti 1
(以下略)なお、Hadoopが出力する個のファイルは改行コードがUNIX式のLFになっています。Windowsのメモ帳で開くと全部つながって一行になってしまうので、IEで開くか、あるいはUNIX式の改行コードに対応した何らかのエディタをお使いください。
筆者は@kaoriyaさんが配布されているGVIMを愛用しています。
次回は
今回は、開発環境の準備とHDInsightのクラスター作成、簡単なサンプルジョブの実行方法までをご紹介しました。次回はチューニング・マニアックスHadoop編の問題に即したMapReduceプログラムの作成方法を解説する予定です。
【関連リンク】
- この記事のキーワード
関連記事
WordPress コース 2nd Stage を攻略しよう(Linux 仮想マシン編)
2014年5月16日 20:00
上位入賞者たちはどうやってチューニングしたのか!?Tuning Maniax総評
2014年8月13日 2:45
Windows Azure上にLinuxインスタンスを立ち上げる(クエスト5)
2012年11月23日 9:20
Windows Azure仮想マシンでLinuxサーバーを構築しよう
2012年9月19日 20:00
Windows AzureでのMySQL = ClearDBを攻略しよう!
2012年9月26日 20:00
PowerShellを使用したAzureの管理
2011年7月27日 20:00
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
