Fluentdのセットアップ
Fluentdのセットアップ
Fluentdはバイナリパッケージ、RubyGems、ソースパッケージからと様々なインストール方法があります。今回は「td-agent」という名称でTreasure Data, Inc.から提供されているRPMパッケージを利用します。
リスト3:td-agentのインストール
$ curl -L http://toolbelt.treasuredata.com/sh/install-redhat.sh | sh
PostgreSQLのセットアップ
リスト4:PostgreSQLのインストールパッケージとデータベースへの接続確認
PostgreSQLはサーバ、クライアントモジュールがRPMパッケージですでにインストールされており、psqlコマンドでデータベースに接続できる状態を前提とします。
# rpm -qa | grep postgres
postgresql93-contrib-9.3.5-1PGDG.rhel6.x86_64
postgresql93-libs-9.3.5-1PGDG.rhel6.x86_64
postgresql93-devel-9.3.5-1PGDG.rhel6.x86_64
postgresql93-server-9.3.5-1PGDG.rhel6.x86_64
postgresql93-9.3.5-1PGDG.rhel6.x86_64
# psql -U postgres
psql (9.3.5)
Type "help" for help.
postgres=#
PostgreSQLの設定ファイル(postgresql.conf)は以下のように編集します。今回はCSV形式のログを使用するため、log_destinationに「csvlog」を加えます。なお、ここではログに出せる情報を全て出力する設定にしていますが、ログの量が増大するとパフォーマンスに影響するため、実運用時は本当に必要なログのみ出力するようにしてください。
リスト5:postgresql.confの設定
log_destination = 'stderr,csvlog' # CSV形式のログを出力
logging_collector = on
log_directory = '/tmp' # ログを /tmp 配下に出力
log_filename = 'postgresql.log'
log_file_mode = '0644'
log_line_prefix = '[%t][%p][%c-%l][%x][%e]%q (%u, %d, %r, %a)'
log_rotation_age = 0 # Fluentdからファイル名固定でアクセスするためローテーションを無効化
log_rotation_size = 0 # Fluentdからファイル名固定でアクセスするためローテーションを無効化
log_min_duration_statement = '1s' # 1秒以上かかったSQLをログに出力
log_autovacuum_min_duration = 0 # 全ての自動VACUUMMのログを出力
log_checkpoints = 'on' # チェックポイント処理をログに出力
log_lock_waits = 'on' # ロック待ちのセッション情報をログに出力
log_temp_files = 0 # 作成された全ての一時ファイルの情報をログに出力
上記の設定を適用したPostgreSQLサーバは、以下のような形式のCSVログ(postgresql.csv)を生成します。
リスト6:CSVログの中身
2014-06-26 07:19:23.292 GMT,,,14376,,53abc97b.3828,1,,2014-06-26 07:19:23 GMT,,0,LOG,00000,"database system is ready to accept connections",,,,,,,,,""
2014-06-26 07:19:23.293 GMT,,,14383,,53abc97b.382f,1,,2014-06-26 07:19:23 GMT,,0,LOG,00000,"autovacuum launcher started",,,,,,,,,""
2014-06-26 07:22:20.667 GMT,"postgres","fluentd",14782,"[local]",53abc9ff.39be,1,"SELECT",2014-06-26 07:21:35 GMT,3/0,0,LOG,00000,"duration: 30031.664 ms statement: select pg_sleep(30);",,,,,,,,,"psql"
Fluentdのプラグインとデータの流れ
ここからは、Fluentdプロセスの中で行われる処理に着目します。今回はCSV形式のサーバログを入力とし、PostgreSQLデータベースへログデータを格納するまでに4つのプラグインを経由しており、それぞれ様々な処理を行っています。それぞれのプラグインの役割と設定方法について、以下に解説していきます。
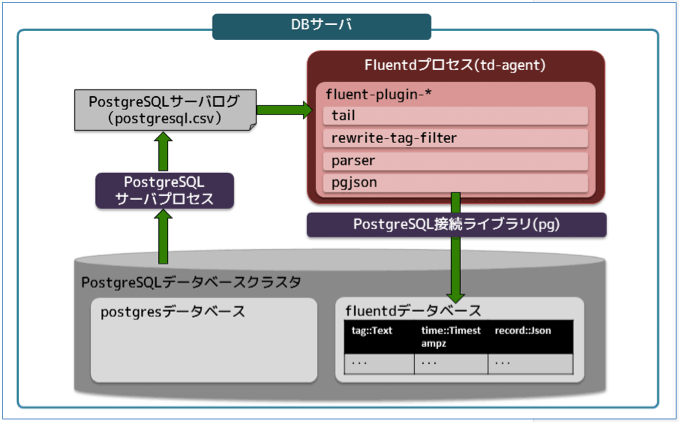
図2:Fluentdプラグインとデータの流れ(クリックで拡大)
tail インプットプラグイン
ログファイルに書き込まれた情報を常時取り込んでいくインプットプラグインで、Fluentdに標準で組み込まれています。このプラグインを使ってPostgreSQLのCSVログをパースし、後続の処理に渡すJSONデータを生成します。Fluentdの設定ファイルに記載するこのプラグイン用の設定は、以下のようになります。なお、この記事ではFluentdをRPMパッケージでインストールしており、デフォルトで読み込まれる設定ファイルは「/etc/td-agent/td-agent.conf」になります。プラグインの設定は、このファイルに追記していくことにします。
リスト7:tailプラグインの設定(td-agent.confに追記)
<source>
type tail
path /tmp/postgresql.csv
pos_file /var/log/td-agent/postgresql.log.pos
tag postgresql
format multiline
format_firstline /^\d{4}-\d{2}-\d{2}/
format1 /^(?<time>[^",]*),"?(?<user_name>(?:[^",]|"")*)"?,"?(?<database_name>(?:[^",]|"")*)"?,(?<process_id>[^",]*),"?(?<connection_from>(?:[^",]|"")*)"?,(?<session_id>[^",]*),(?<session_line_num>[^",]*),"?(?<command_tag>(?:[^",]|"")*)"?,(?<session_start_time>[^",]*),(?<virtual_transaction_id>[^",]*),(?<transaction_id>[^",]*),(?<error_severity>[^",]*),(?<sql_state_code>[^",]*),"?(?<message>(?:[^"]|"")*)"?,(?<detail>[^",]*),"?(?<hint>(?:[^",]|"")*)"?,(?<internal_query>[^",]*),(?<internal_query_pos>[^",]*),(?<context>[^",]*),"?(?<query>(?:[^"]|"")*)"?,(?<query_pos>[^",]*),(?<location>[^",]*),"?(?<application_name>(?:[^",]|"")*)"?$/
</source>
PostgreSQLのログは、1件の情報内に改行が含まれる可能性があるため、「format」は複数行に対応可能な「multiline」に設定し、ログを区切る文字列を「format_firstline」に指定します。また、「format1」の部分にCSVデータのカラムをパースしてJSONデータに変換するルールを正規表現で定義し、PostgreSQLのログデータであることを区別するため「postgresql」という名前のタグを付けることにします。
上記の設定により、PostgreSQLのCSVログは以下のようなJSONデータに変換されます。
リスト8:変換されたJSONデータ
{
"tag": "postgresql",
"time": "2014-06-30 01:12:02+00",
{"user_name":"","database_name":"","process_id":"27136","connection_from":"","session_id":"53b0b980.6a00",
"session_line_num":"10","command_tag":"","session_start_time":"2014-06-30 01:12:32 GMT",
"virtual_transaction_id":"","transaction_id":"0","error_severity":"LOG","sql_state_code":"00000",
"message":"checkpoint starting: xlog","detail":"","hint":"","internal_query":"","internal_query_pos":"","context":"",
"query":"","query_pos":"","location":"","application_name":""}
}
fluent-plugin-rewrite-tag-filter
データの内容によって、タグを書き換えるバッファプラグインです。このプラグインを使い、ログの内容に応じてタグを分別してみます。このプラグインは以下のようにインストールできます。
リスト9:fluent-plugin-rewrite-tag-filterプラグインのインストール
$ sudo /usr/lib64/fluent/ruby/bin/fluent-gem install fluent-plugin-rewrite-tag-filter
このプラグインの設定は以下のようになります。「rewriterule1~9」の部分に定義された正規表現にログメッセージがマッチしたら、対応するタグに置き換えられます。例えば、スロークエリのログなら「raw.postgresql.slow_query」、一時ファイル出力のログなら「postgresql.tempfiles」という名前のタグが付けられます。
リスト10:fluent-plugin-rewrite-tag-filterプラグインの設定(td-agent.confに追記)
<match postgresql>
type rewrite_tag_filter
rewriterule1 message ^duration: raw.postgresql.slow_query
rewriterule2 message ^checkpoints\sare\soccurring\stoo\sfrequently postgresql.checkpoints.frequently
rewriterule3 message ^checkpoint\sstarting: postgresql.checkpoint.start
rewriterule4 message ^checkpoint\scomplete: postgresql.checkpoint.complete
rewriterule5 message ^automatic postgresql.vacuum
rewriterule6 message ^temporary file: postgresql.tempfiles
rewriterule7 message ^process.*detected\sdeadlock postgresql.deadlock
rewriterule8 message ^process.*(still waiting|acquired) postgresql.lockwait
rewriterule9 message .* postgresql.others
</match>
fluent-plugin-parser
Fluentd上に流れるデータの任意のフィールドを、さらに分解するバッファプラグインです。このプラグインを使ってスロークエリログの処理時間、SQL文のデータを分解し、後から分析しやすくなるよう別の要素としてJSONに付与します。このプラグインも以下のようにインストールできます。
リスト11:fluent-plugin-parserプラグインのインストール
$ sudo /usr/lib64/fluent/ruby/bin/fluent-gem install fluent-plugin-parser
このプラグインの設定は以下のようになります。「format」の部分にキー「message」のデータを変換するルールを正規表現で定義しています。
リスト12:fluent-plugin-parserプラグインの設定(td-agent.confに追記)
<match raw.postgresql.slow_query>
type parser
remove_prefix raw
reserve_data yes
key_name message
format /^duration: (?<duration>[0-9\.]+) ms statement: (?<statement>.+)$/
</match>
この設定により、リスト13のスロークエリログは「duration」「statement」というキーが追加されて、リスト14のような形に変換されます。
リスト13:変換前のスロークエリログ
{
"tag": "raw.postgresql.slow_query",
"time": "2014-06-30 01:12:02+00",
“user_name”:“postgres”,“database_name”:“fluentd”, …,
“message”:“duration: 4004.423 ms statement: select pg_sleep(4);”, … ,"application_name":"psql"}
}
リスト14:変換後のスロークエリログ
{
"tag": "postgresql.slow_query",
"time": "2014-06-30 01:12:02+00",
“user_name”:“postgres”,“database_name”:“fluentd”, …,
“message”:“duration: 4004.423 ms statement: select pg_sleep(4);”, … ,"application_name":"psql",
"duration":"4004.423",
"statement":"select pg_sleep(4);"}
}
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
