検証3 (okuyamaメモリ・ディスク併用)の検証結果
検証3 (okuyamaメモリ・ディスク併用)の検証結果
当初の予定では、性能の平均値を計測してピーク性能を検証する予定でした。しかし実際に計測してみたところ、性能が時間経過とともに低下し、安定しない結果となりました。このようなケースでは、計測時間の長さによって性能の平均値が変わってしまうため、検証目的であるクラスタ台数見積もりの基礎データとしては適しません。そこでメモリ・ディスク併用パターンでは、性能の時間推移を計測しました。
検証3は図6の構成で実施しました。なお、検証3と検証4ではクラスタ台数が4台の場合のみ検証しました。上述の測定内容の変更と検証期間の都合のためです。
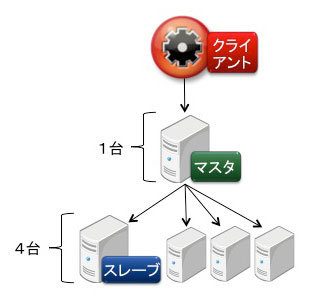
図6:検証3の構成
検証結果を図7に示します。グラフは一定の同時アクセス数で連続して書き込んだ際の、性能の時間推移を表しています。グラフの横軸は書き込み処理開始からの経過時間を表しており、単位は「秒」です。グラフの値は、10秒間隔での性能の平均値をプロットしています。色分けは同時アクセス数の違いを表しています。
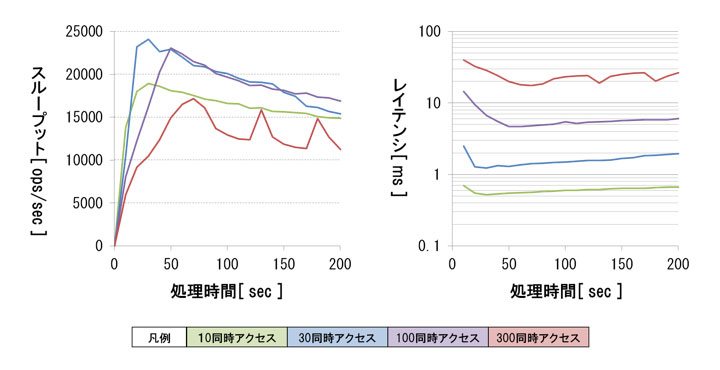
図7:検証3のスループットとレイテンシ(クリックで拡大)
スループットについては、最大値と同時アクセス数の間の関係性を確認できました。スループットは同時アクセス数が30件・処理時間30秒のときに最大となり、大きさは24096.0 ops/secとなりました。同時アクセス数が増加すると、性能低下していく結果となりました。
レイテンシについては、同時アクセス数の増加に対して指数的に性能が低下しました。レイテンシの低下幅が大きかったため、図7ではグラフの縦軸を対数軸にしています。
性能ボトルネックについてハードウェアの稼働状況を確認したところ、同時アクセス数が300件まで増加するとマスタノードのネットワーク負荷が高くなっていました。そのため、データの振り分け処理がボトルネックの要因であると予想しています。
検証3の追加検証・長時間書き込みの検証結果
上述の通り、検証3では時間経過にともなって性能が低下していく結果となりましたが、一定時間経過後に性能低下が落ち着き、安定稼働する可能性が考えられます。安定した性能が確認できれば、それを基礎データとしてクラスタ台数見積もりに利用できます。そこで、長時間にわたって書き込みを実行し、性能の時間変化を検証しました。
検証結果を図8に示します。検証は同時アクセス数を100とした場合で実施しました。検証環境の構成には変更ありません。

図8:検証3の長時間書き込みのスループットとレイテンシ(クリックで拡大)
開始直後にスループットが急激に性能が低下しましたが、中盤以降は比較的安定し6000~10000 ops/sec の性能を確認できました。また終盤には性能が大きく低下しましたが、これはJVMに割り当てたメモリを使い切ったことが原因です。この際okuyamaの機能により、Keyの保存先がメモリからディスクに自動的に切り替わっています。これ以降のスループットは65~85 ops/sec で、これは検証1のディスク保存パターンでの検証結果とほぼ一致しています。
レイテンシは序盤から中盤にかけては10ms前後でしたが、終盤にディスク書き込みに切り替わったことで1000ms以上と大きく性能低下しました。
全体として性能が徐々に低下する原因ですが、ログを確認したところJavaのGC(ガベージコレクション)が頻発しているため、これが原因ではないかと予想しています。
検証4 (Riakメモリ・ディスク併用)の検証結果
検証4の構成ですが、当初は図9左のように単一ノードへアクセスする構成を予定していました。しかし実際に検証してみたところ、アクセスを受けるノードのCPU負荷が非常に高くなり、他ノードのリソースを有効に使えていないことが分かりました。
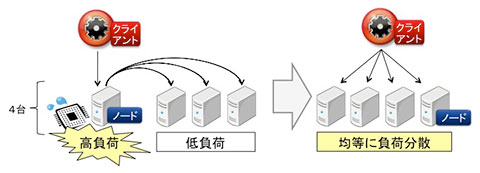
図9:検証4の構成
そこで構成を見直し、図9右のようにアクセスを分散して全ノードを有効に使えるよう変更しました。以下では構成変更後の検証結果をご説明していきます。
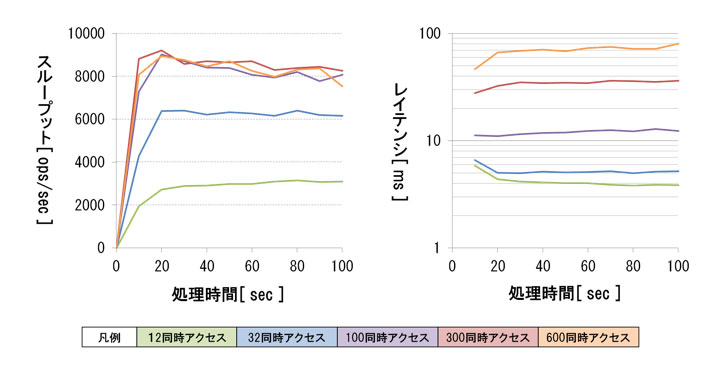
図10:検証4のスループットとレイテンシ(クリックで拡大)
検証結果は、図10のようになりました。なお、ここでの同時アクセス数は、クラスタ全体で合計した同時アクセス数です。検証4では図9に示したようにクラスタの4ノードに対して均等にアクセスを分散しているため、例えば「12同時アクセス」とは1ノードあたり3同時アクセスの場合を意味しています。その他のグラフの見方は検証3と同じです。
同時アクセス数が100件以上では、スループットがほぼ同程度となりました。同時アクセス数が300件、処理時間20秒の時にスループットは最大値の9211.0 ops/secを示しました。
レイテンシは、同時アクセス数の増加に対して指数的に性能が低下しました。レイテンシの低下幅が大きかったため、図10ではグラフの縦軸を対数軸にしています。
性能ボトルネックについてハードウェアの稼働状況を確認したところ、同時アクセス数が100件以上になると構成変更前と同様にCPUの負荷が高くなっていました。そのためデータ振り分け処理がボトルネック要因であると予想しています。
検証4の追加検証・長時間書き込みの検証結果
検証4についても、長時間にわたって書き込みを実行し、性能の時間変化を検証しました。
検証結果を図11に示します。検証は同時アクセス数を100とした場合で実施しました。検証環境の構成には変更ありません。
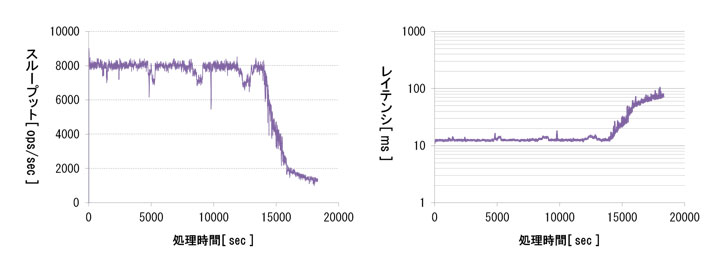
図11:検証4の長時間書き込みのスループットとレイテンシ(クリックで拡大)
序盤から中盤にかけて安定して稼働しており、約8000 ops/sec のスループット性能を確認できました。終盤はOSの物理メモリを使い切ったことによりスワップ書き込みが発生したことで、1500 ops/sec以下まで性能低下しました。なお、OSのスワップ領域がない環境で検証したところ、物理メモリを使い切ったタイミングでエラーとなり、Riakのプロセスがダウンする結果となりました。
レイテンシも序盤から中盤にかけては10msほどで安定しましたが、終盤にスワップ書き込みに切り替わったことで、100ms弱まで大きく低下しました。
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
