MySQL Clusterの特徴とアーキテクチャ
本連載では、実際に「MySQL Cluster」を利用するためのチュートリアルとなるように、その特徴と基本的なアーキテクチャからインストール、基本的な操作などをコマンド付きで解説していきます。第1回の今回は、MySQL Clusterの特徴とアーキテクチャについて紹介します。MySQL Clust
2015年7月21日 17:00
本連載では、実際に「MySQL Cluster」を利用するためのチュートリアルとなるように、その特徴と基本的なアーキテクチャからインストール、基本的な操作などをコマンド付きで解説していきます。第1回の今回は、MySQL Clusterの特徴とアーキテクチャについて紹介します。
MySQL Clusterとは?
「MySQL Cluster」は「MySQL Server」とは開発ツリーの異なる製品で、共有ディスクを使わずにアクティブ−アクティブのクラスタ構成が組めるリレーショナルデータベースです。カラムやインデックス、ノードの追加・削除といった各種メンテナンス処理をオンラインで実行できる、単一障害点がなく可用性が非常に高い、などの特徴があります。そのため、米国海軍の航空母艦における航空機管制システムなど、ミッションクリティカルな分野でも多く利用されています。
また、基本的にはデータとインデックスを全てメモリ上に持つインメモリデータベースであり、トランザクションを高速に処理できるため、リアルタイム性が求められるアプリケーションにも向いています。インメモリデータベースとして使用する場合でも、データが更新された時には更新内容をディスクに保存しているため、データの永続性は担保されています(データベースを再起動した時に更新したデータが消失するといったことはない)。
MySQL Clusterの基礎となる技術は、通信機器ベンダであるエリクソンの携帯通信網加入者データベース向けに開発された「Ericsson Network Database(NDB)」です。携帯通信網加入者データベースは、大半の処理が加入者IDに紐づく処理であるため、1つ1つの処理は比較的シンプルです(RDBMS視点では主キーに紐づく処理、NoSQL視点ではKVS(Key-Value Store:キーバリューストア)的な処理)。
しかし、携帯電話の加入者増加に合わせて多重実行される処理数も増えるため、システムには拡張性が求められます。また、通話履歴などの書き込み処理が大量に発生するため、読み込み処理に対してだけでなく、書き込み処理に対する拡張性も求められます。さらに通信障害が起きれば収益機会を逃してしまう上に社会インフラとしても大きな問題となるため、高可用性も求められます。このような“大量のトランザクション処理”や“高可用性”が求められる環境向けに最適化されたNDBとMySQLを統合したものが、現在のMySQL Clusterです。
また、元々NDBはSQLを使わずにC++のAPIでデータを処理していましたが、MySQLと統合されたことによりSQLも使えるようになりました。そのため、現在はNoSQL(KVS)とSQLの両方が使用できます。そして、NoSQLによる処理でもACID準拠のトランザクションに対応しています。さらに、現在はC++のAPI以外にもJava、memcached、Node.jsなど各種のNoSQL APIが使用できるため、NoSQLの形態でWebアプリケーションのバックエンドとしても利用しやすくなっています。
MySQL Clusterの用途や事例
前述したように、MySQL Clusterは携帯通信網加入者データベース向けに開発された技術が基礎になっているということもあり、Alcatel-LucentやNokia、NECなどの大手通信機器ベンダでも活用事例があるほか、携帯キャリアのコンテンツ配信プラットフォーム等でも多数利用されています。また、オンラインゲームでもBig Fish Games、Blizzard Entertainment、Zyngaといった海外ベンダの他、国内ベンダでも採用が広がっています。
さらに、単一障害点がなく非常に可用性が高いことなどから、前述の航空機管制システムのほかPayPalや国内の証券会社など、ミッションクリティカルなシステムでの採用事例も増えてきています。
MySQL Clusterのアーキテクチャ
MySQL Clusterは「データノード」「SQLノード」「管理ノード」という3種類のノードから構成されています。図1は、データノード4台、SQLノード2台、管理ノード2台で構成した場合のイメージ図です。各ノードの主な役割は表1の通りですが、順番に解説していきます。
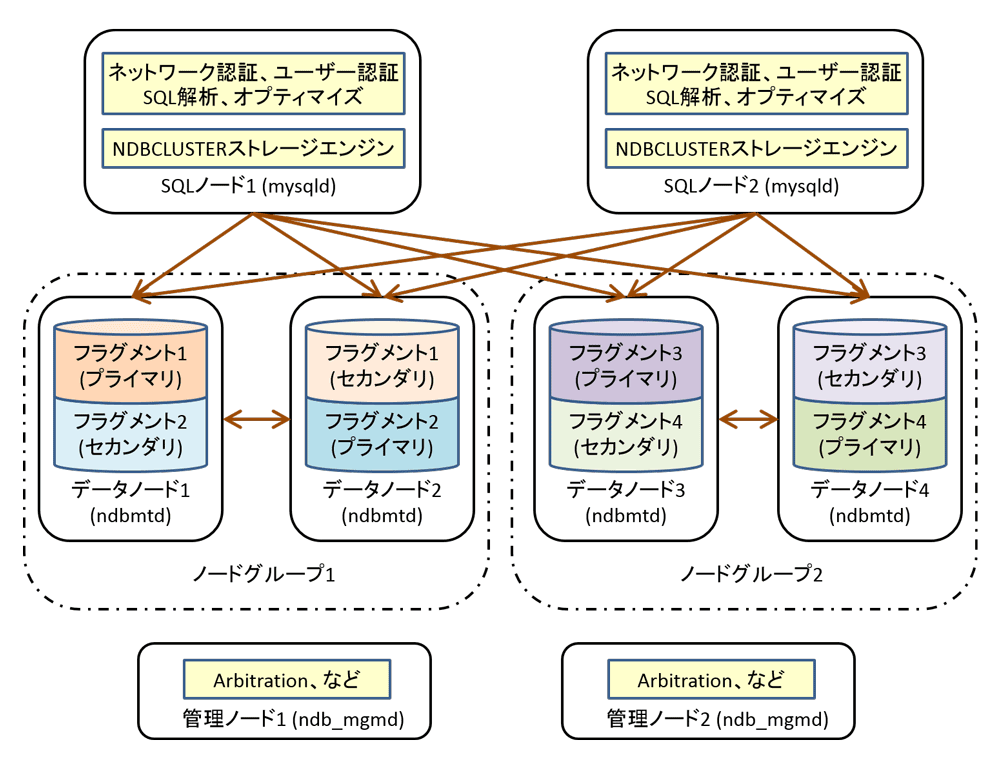
図1:MySQL Clusterアーキテクチャ概要
表1:MySQL Clusterの各ノードの役割
| ノード名 | プロセス名 | 主な役割 |
|---|---|---|
| データノード | ndbmtd | ・データ、インデックスの管理 ・トランザクションの制御 |
| SQLノード | mysqld | ・アプリケーションとデータノードをつなぐSQLインターフェース ・ユーザー認証、権限付与 |
| 管理ノード | ndb_mgmd | ・MySQL Clusterの起動/停止 ・各ノードの設定管理 ・バックアップ/リストア処理の開始 ・Arbitration(スプリットプレインの解消) |
データノード:データ管理とトランザクション制御
データノードはMySQL Clusterの肝となるノードで、データやインデックスを保持し、トランザクションを制御します。データノードでは、挿入されたデータを各テーブルの主キーのハッシュ値に基づいて水平分割(行単位で分割)して格納します。さらに、分割したデータを同じノードグループ内のデータノードに複製して持つことで、データを冗長化します。データの冗長化はデフォルトでは2重化ですが、最大4重化まで設定できます。
図1の例ではデータノードが4台存在するため、データは4分割され、4つのデータノードに分散して格納されています。分割された各フラグメント(断片)の複製を別のデータノードが保持するため、データノード1はフラグメント1だけでなくフラグメント2の複製も保持しています。同様に、データノード2はフラグメント2だけでなくフラグメント1の複製も保持しています。同じデータを複数のデータノードで保持しているので、あるデータノードに障害が発生した場合でも、別のデータノードで処理を継続できます(図1の例ではデータノード1に障害が発生した場合、フラグメント1上のデータにアクセスする必要がある処理は、データノード2にアクセスすることで処理を継続できる)。また、障害が発生したデータノードを復旧する際も、オンラインでデータノードをクラスタに戻すことができます。
データノードへのアクセスがボトルネックになっている場合、データノードの台数を増やすことで1データノード当たりが持つデータ量が少なくなり、負荷分散によってスループットを向上できます。図2はMySQL Cluster開発チームが実施したベンチマーク結果ですが、極めて高いスループットを実現できているだけでなく、データノードの台数を増やすにつれて線形にスループットが向上していることが確認できます(横軸がデータノード数、縦軸が1秒当たりのSQL実行数)。
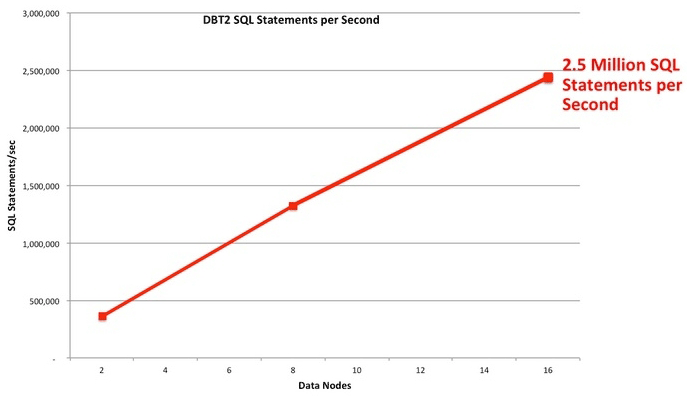
図2:MySQL Clusterのベンチマーク結果(DBT-2)
出典:MySQL Clusterのベンチマーク
参考サイト:Mikael Ronstrom:200M reads per second in MySQL Cluster 7.4
SQLノード:SQLのインターフェース
SQLノードでは、NDBCLUSTERストレージエンジンを追加したMySQL Serverが稼働しています。データノードはMySQL Serverのストレージエンジン(NDBCLUSTERストレージエンジン)として実装されているため、NDBCLUSTERストレージエンジンを使用しているデータはデータノード上に保持され、MyISAM、InnoDB等のストレージエンジンを使用しているデータはSQLノード上に保持されます(図3)。通常はユーザー情報やテーブル定義などのメタデータのみSQLノード上に保持し、ユーザーデータは全てデータノード上に保持して利用します。
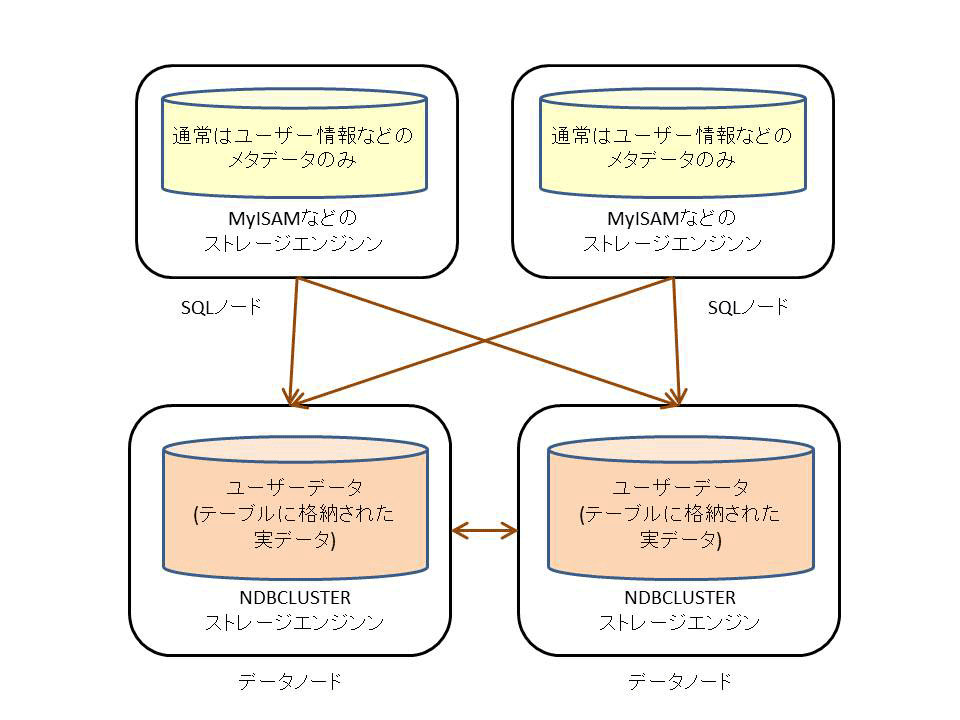
図3:MySQL Clusterのデータ保持方法
アプリケーションからはSQLノードのMySQL Serverを経由してデータノード上のデータにアクセスできます。必要なデータがどのデータノードに存在するかはSQLノードが自動的に判断してくれるため、アプリケーションでは通常のMySQL Serverを利用するのと同様の手法(同様のSQL)でMySQL Cluster上のデータにアクセスできます。
管理ノード:データノードやSQLノードを管理
管理ノードは補助的な役割を担うノードで、役割は限られています。管理ノードでは各ノードの設定を管理しているので、各ノードはまず管理ノードにアクセスし、設定情報を受け取ってから起動します。また、データノードの起動/停止やバックアップ/リカバリ操作なども管理ノード上からコマンドで実行します。
また、MySQL Clusterの稼働中にネットワーク障害等によりデータノード間の通信が途絶えて「スプリットブレイン」が発生した場合は、データの不整合を防ぐために管理ノードが調停役となってArbitration(調停)を行い、一部のデータノードを停止します。
スプリットブレインはHAクラスタ特有の問題です。MySQL Clusterでは図4のようなネットワーク障害が発生した場合、どちらかのクラスタを停止しないと同じデータをクラスタ1でもクラスタ2でも更新できてしまい、データの不整合が発生してしまいます。このような不整合を防ぐために管理ノードがArbitrationを行い、どちらかのクラスタを停止します。
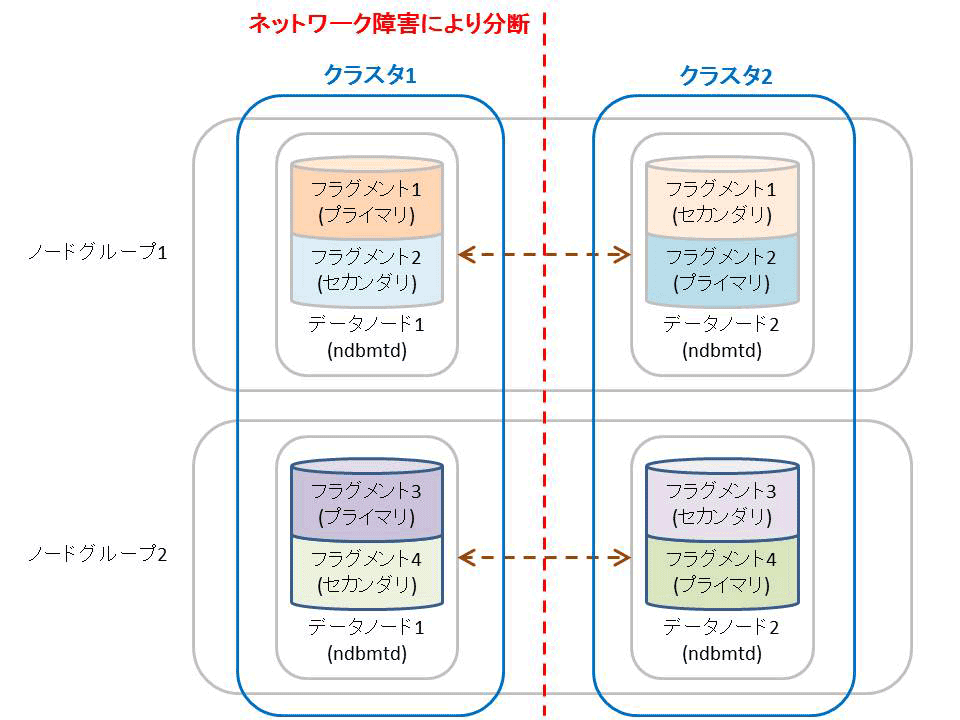
図4:スプリットブレイン状態
なお、デフォルト設定では管理ノードがArbitrationを実行しますが、SQLノードで実行するように設定を変更することもできます。
MySQL Clusterの特徴
MySQL Clusterの主な特徴は、以下のとおりです。
読み込み・書き込み処理に対して高い拡張性を実現
MySQL Clusterは、内部的に自動的にデータをシャーディング(分割して複数のサーバーに分散)することにより、読み込み処理に対して高い拡張性を持っています。前述したようにMySQL Cluster向きのアプリケーションで使用すれば、書き込み処理に対しても高い拡張性を実現できます。
99.999%の高可用性(年間5分程度の停止時間)
単一障害点がない構成を組めるほか、障害発生時のフェイルオーバー時間も極めて短く、カラムやインデックス、ノードの追加・削除といった各種メンテナンス処理もオンラインで実行できるため、停止時間を最小限に抑えることができます。
レプリケーション機能を活用した地理的冗長性(災害対策)
複数のデータセンターなど異なる拠点に構築したMySQL Cluster同士で非同期レプリケーションを行い、地理的な冗長性も確保できます。また、通常のMySQL Serverのレプリケーション機能とは異なり、MySQL Clusterのレプリケーションでは2つのクラスタをそれぞれマスタとする双方向レプリケーションも構築可能です。双方向レプリケーションでは同じデータをそれぞれのクラスタで更新してしまう“データの競合”が問題になりますが、MySQL Clusterのレプリケーション機能にはデータの競合を検出するための仕組みが実装されています。MySQL Clusterのレプリケーション機能については、今後の連載で具体例を紹介する予定です。
リアルタイム処理
データノードはデフォルトではデータとインデックスをすべてメモリ上に持つインメモリデータベースであるため、トランザクションを高速に実行でき、リアルタイム性が求められるアプリケーションにも適しています。
SQL+NoSQLの柔軟性
データノード上のデータはNoSQLによる読み込み/書き込みも可能です。より高い性能を出したい場合にはNoSQLを使用し、GROUP BYやJOIN等を使用して柔軟にデータアクセスをしたい場合にはSQLを使用するといった“良いとこ取り”をした使い方ができます。
また、現在ではJava、memcached、Node.jsなど各種のNoSQLインターフェースを取り揃えています。NoSQLインターフェースを使用した場合はKVSのように利用できますが、KVSとしてMySQL Clusterをとらえると、一般的なKVSと比較して以下のメリットがあります。
- ACID準拠のトランザクションをサポート
- データの永続化と冗長化が担保されている
- 障害発生時の自動フェイルオーバー機能
- オンラインバックアップ機能
- NoSQLだけでなくSQL文も利用可能
- SQLノード経由でレプリケーション機能も使用可能
低いTCO
共有ディスクを使用せずに、コモディティ化しているハードウェアを複数台並べてスケールアウトすることで性能を拡張できるため、トータルコストを下げることができます。
おわりに
連載第1回の今回は、MySQL Clusterの特徴とアーキテクチャについて解説しました。第2回では、MySQL Clusterのインストール方法や基本操作などをコマンド付きで解説する予定です。MySQL Clusterに興味を持たれた方は、本連載を参考にMySQL Clusterへの第一歩を踏み出して頂ければ幸いです。
※本稿において示されている見解は、私自身の見解であって、私の所属するオラクルの見解を必ずしも反映したものではありません。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
