仮想環境に最適化したスマートストレージのアーキテクチャ(後)
前回に引き続き、Tintri VMstoreの特徴について解説します。③仮想マシン単位での「見える化」の実現従来型のストレージを仮想環境で使った場合の大きな課題の1つとして、「LUN/ボリューム単位でのストレージの動きは把握できるが、ストレージの内部でそれぞれの仮想マシンがどのように扱われているのか
2015年6月3日 4:00
前回に引き続き、Tintri VMstoreの特徴について解説します。
③仮想マシン単位での「見える化」の実現
従来型のストレージを仮想環境で使った場合の大きな課題の1つとして、「LUN/ボリューム単位でのストレージの動きは把握できるが、ストレージの内部でそれぞれの仮想マシンがどのように扱われているのかがまったくわからない」ということがあります。仮想環境のVM数が50~100ぐらいの規模に達すると、ストレージの性能問題に直面することが増えるため、そのような悩みを感じる傾向にあるようです。
例えば、仮想マシンを使用しているユーザーからストレージI/Oの遅さを指摘された場合、明らかにストレージ全体でも遅延が発生していれば、ストレージ性能の限界として迅速に対処が可能です。しかし、LUN/ボリュームやストレージ全体としては問題なく稼働しているように見える一方、対象の仮想マシンのストレージI/Oがどうして遅くなっているのか切り分けの糸口が見いだせずに数週間も時間を使ってしまい、有効な対応策を打てず、結果的に対応策としてコストをかけてストレージ増強するケースが数多く見受けられます。
Tintri VMstoreは前述の通り「仮想マシン」も管理オブジェクトとして扱うよう設計されているため、仮想マシン単位のさまざまな稼働情報をストレージ内部で保持しています。それらの情報と、VMware vSphere vCenter、RHEV Manager、Microsoft SCVMMのような管理ソフトウェアと連携することで得られた仮想環境側の情報を、ストレージ側で有機的に組み合わせ、「仮想マシン単位」での見える化を実現しています。図1はVMstoreの管理GUIでの表示例であり、表のような体裁になっています。この1行1行が、このVMstore上に収容されている1台ごとの仮想マシンとして表されています。
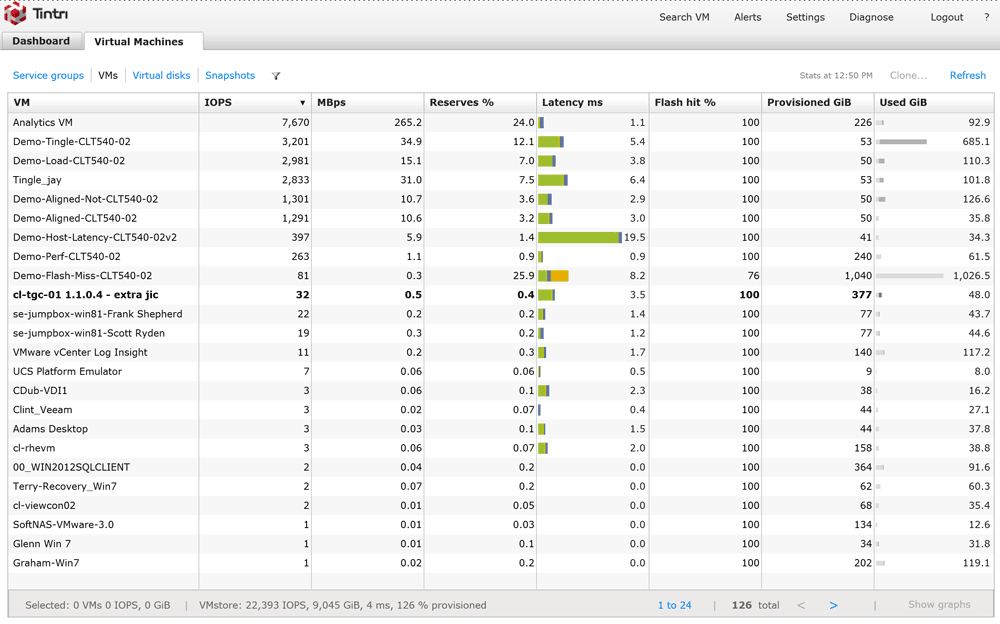
図1:Tintri管理GUI:ストレージ上の仮想マシンを一覧表示
これらの情報の中には、ストレージにおける遅延時間やフラッシュI/O率など、ストレージの内部情報でないとわからない項目も含まれています。ここでは、遅延時間に注目してもう少し詳細に見てみましょう。
図2は特定の仮想マシンの遅延時間に注目して拡大表示したものです。この仮想マシンでは、仮想ディスクへのアクセスにおいて平均17.0[msec]の遅延が発生しています。しかも、遅延の大部分(16.1[msec])がホスト(仮想マシン側)で発生しており、ネットワークやストレージ側では1[msec]以下の遅延しか発生していないことがすぐにわかります。つまり、仮想環境における遅延が、インフラのどの部分で発生しているのかが一目でわかるように表示されます。今まではこのボトルネックの切り分けに数日から数週間必要でしたが、このGUIでは数秒で現状分析が可能です。
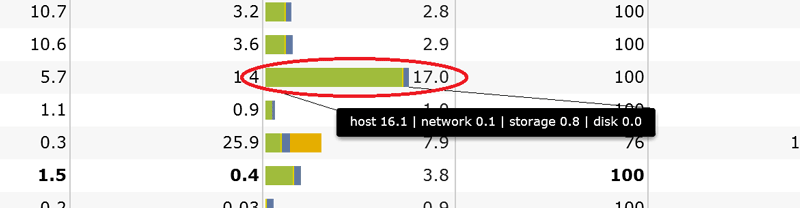
図2:仮想マシン単位でのボトルネック分析
さらに、この分析は最大1週間前まで過去に遡れます。図3の例では、4月9日午後2:30頃の地点にマウスのポインタを当てることで、その時点の遅延時間分析を表示しています。全体で23[msec]ある遅延のうち、ここでもホストが大部分の21.9[msec]を占めているのがわかります。
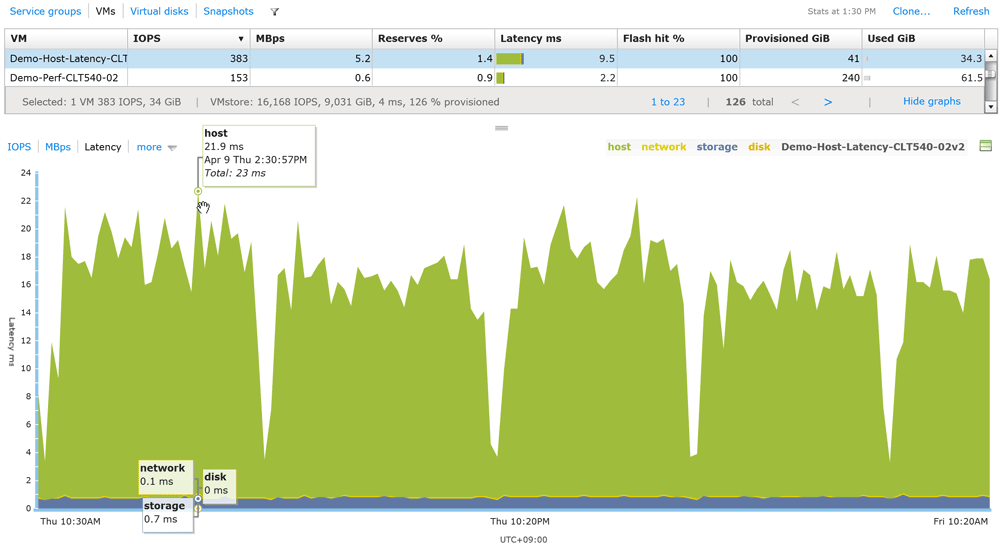
図3:遅延時間を過去に遡ってグラフ表示
より分析を進めるためには、IOPSと遅延時間、スループット値と遅延時間など、複数の情報を組み合わせた考察が求められることもあります。そのようなときのために、複数の情報を上下に表示し、状況の分析をより効率的に行うための表示形式もサポートしています。図4の例では、仮想マシンのCPU/メモリの使用状況と遅延時間のヒストリカルデータを同時に表示しています。
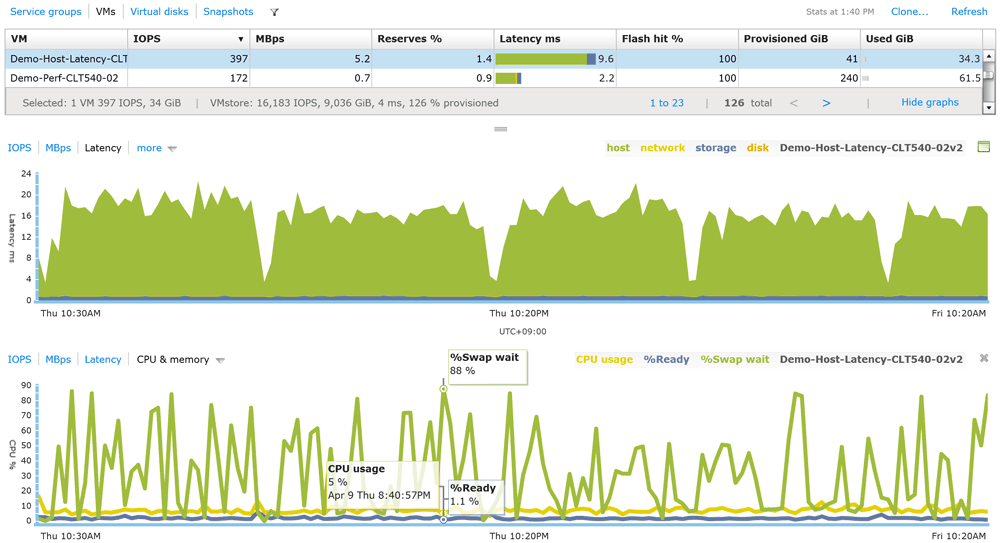
図4:遅延時間と仮想マシンのCPU/メモリ利用状況を同時に表示
このように、実際の性能問題が発生してから数日してからユーザー側からストレージ遅延の申告があったとしても、この管理GUIを使って迅速にその当時の状況が把握できます。仮想環境全体の状況把握をストレージ内部に関しても仮想マシンの観点から行えるようになり、運用管理性の大きな向上を実現します。
④性能安定化とSLA維持
4つの特徴の最後として、特定の仮想マシンのI/Oがインフラ全体に影響を与えてしまうことを防ぎ、インフラ全体としてのSLA維持を実現する機能をご紹介します。
従来のストレージでは、ある仮想マシンが大きなI/Oを行うと、他の仮想マシンがそのI/O能力を奪われてしまい、結果としてインフラとしての安定性に欠ける状態になることが大きな課題でした(図5)。この不安定さを防ぐために、個別の仮想マシンがどのタイミングでどの程度I/O能力を必要とするのかを綿密に把握し、ストレージ設計に都度反映することは、プロビジョニングや導入後の運用維持という両面で非常に大きな工数がかかります。場合によっては、ストレージ構成の増強という予想外のコスト負担を強いられることさえありました。
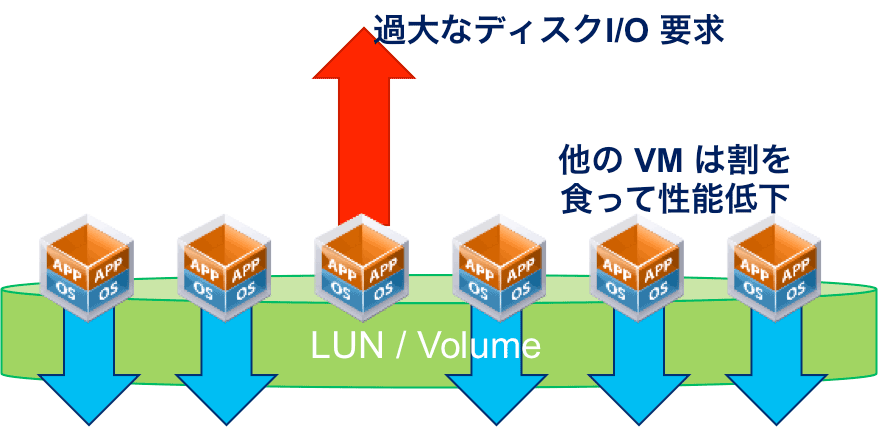
図5:従来型ストレージの不安定さ
前回の特徴①や②でも触れたように、Tintri VMstoreは個別の仮想マシンがどの程度のI/Oを行うのかを把握し、それぞれが必要とするストレージリソースを個別に確保できるよう動作します。この確保の動作を「Performance Reserve」と呼び、仮想マシンごとの過去の稼働実績から割り当て量を算出します。その結果、個別の仮想マシンはそれぞれが安定して動くのに必要なストレージリソースを常に優先的に受け取ることができ、仮に他の仮想マシンが突然大きなI/Oを行ったとしても、割り当てを受けた範囲で今まで通り安定してI/Oを継続することが可能です(図6)。
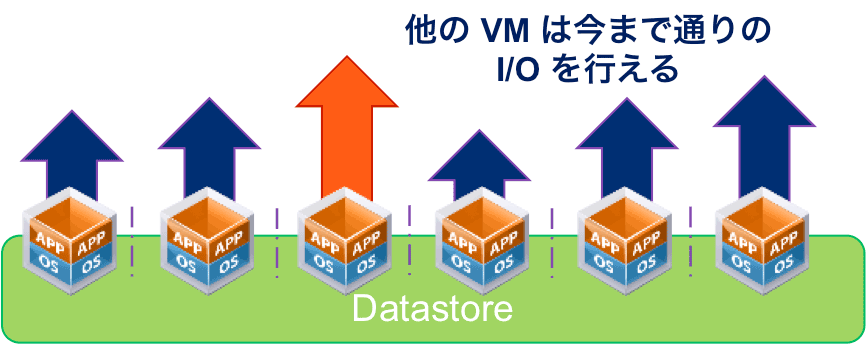
図6:Tintri VMstoreは安定したSLAを提供
この動作は完全に自動で行われるため、個別の設計や設定は一切不要です。仮想マシンを稼働させるだけで、その稼働実績をもとにVMstoreが適切なストレージリソースを割り当て、10分に1回その値の見直しを行い、常に安定したストレージインフラの提供を実現します。
ひょっとすると、フルフラッシュなどの高速なストレージであればこのような制御は不要と思われるかもしれません。確かに従来型のディスクストレージと比べれば、その高速性から改善するように見えます。しかし、性能の高いストレージを使えばそれだけホストが追加され、稼働する仮想マシンの数は増え、ストレージの処理負荷も大きくなります。結果として、従来型のストレージが抱えていた「仮想マシン単位でサービスレベルやQoSなどを制御できないことの課題」は、根本的には何も改善していないのです。
結局は「仮想マシン」を認識できるかどうか
4つの特徴を順に説明しましたが、その根幹にあるもの、Tintri VMstoreが他のストレージと決定的に違う点は、結局「仮想マシン」をストレージが認識できるかどうかという点に行き着きます。
一部のストレージ製品はこの点に気づき、VMware社vSphereの新版で追加されたVVOL機能への対応によって「仮想マシン」単位の管理を実現しようとしています。VVOLのコンセプトは非常に素晴らしく、ティントリ社もその趣旨に賛同して対応製品リリースを将来的に予定しています。しかしながら、本当の意味で一番重要なのは、表面的なインターフェースとしてVVOLに対応することではなく、“VVOLを通してやり取りしている個別の仮想マシンのデータをストレージとしてどう扱うのか?”という点です。もともと「仮想マシン」という概念を理解できるストレージと、「後からインターフェースとして対応しただけ」のストレージとでは、最終的にできることが変わってくるのは明らかです。実際の差異については、今後各社から対応製品が出揃ってからあらためて評価する機会を持ちたいと思います。
今後の展開
これまでTintri VMstoreは、単なる仮想環境でのストレージであることを超え、クラウド環境をより効率的に構築できるよう、さまざまな機能を追加してきました。例えば、仮想マシン単位でのスナップショット/レプリケーション機能、PowerShellおよびREST APIサポートによる仮想マシン単位での運用管理の自動化、vSphereやHyper-Vなどのような異なるハイパーバイザの同時サポートなど、リリースを重ねるごとに進化を進めて来ました。今後はOpenStackへの対応などさらに機能を強化していく予定です。
このような「仮想マシン」の管理に軸足を置いた製品コンセプトは、今後さらにクラウド化が進むと逆に強く求められるニーズだと考えています。業務アプリやサービスがクラウド上の仮想マシン上で稼働しているとき、それがどこで動作しているのかは意識しなくて良くなる反面、稼働状態の把握、SLA維持/QoS制御、データ保護ポリシーの適用などの運用管理タスクを、インフラ側から仮想マシン単位で実行できることは、より強く求められると考えています。仮想化のニーズが今後高まるにつれTintri VMstoreもさらに進化を遂げていくことでしょう。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
