Bigtable
Bigtable
前ページで、MapReduceの出力は、再びMapReduceの入力になりうると述べましたが、それは入力/出力の両者がいずれも<Key,Value>の形式をしているからです。
Googleのシステムの中では、この形式をしたデータが重要な意味を持っています。当初は、こうしたデータもGoogleのファイル・システムの上に置かれ、MapReduceの操作もファイル・システム上のデータを扱っていたのですが、やがて、こうしたデータを格納する特別の場所を作るという方向に、Googleのシステムは発展していきます。
こうして生まれたのが、「BigTable」というKey/Value型のデータベースです。
Bigtableは、数千台のサーバー上のペタバイト単位の非常に大きなサイズにまでスケールするようにデザインされた、構造化されたデータを管理する分散データベース・システムです。
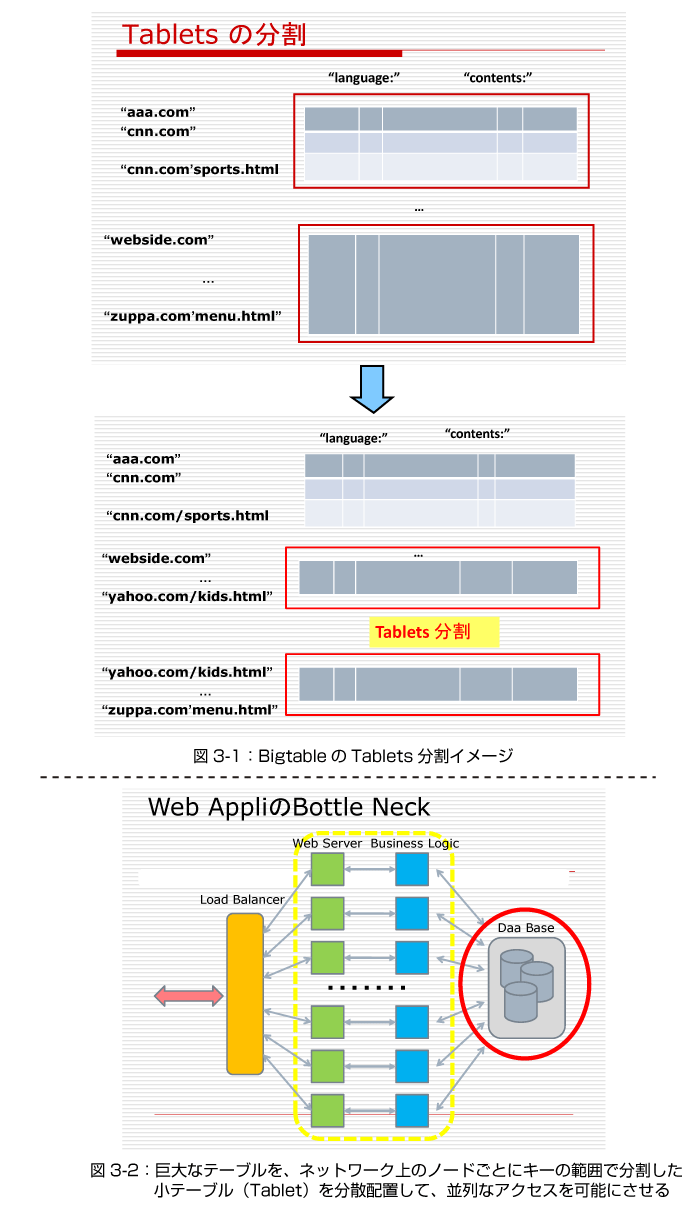
Bigtableの最大の特徴は、そのテーブルが小さなテーブルTabletに分割されていることです。Tabletは同一のノードにも複数置かれているのですが、基本的にはネットワーク上の多数のノードに分散されて配置されています。
Bigtableのテーブルは、単一のキーにしたがって辞書式順序に並べられているので、テーブルが大きくなれば、Bigtableは行の連続する範囲を維持するようにTabletを分割して、ネットワーク上のノードに再配置します。こうして、自然な形でノードの数に応じてテーブルの大きさを拡大できるのです(図3-1参照)。
そればかりではありません。現在のエンタープライズのIT技術で、もっとも一般的に用いられているのは、3-Tierのサーバー・サイドのWebアプリケーションです。
このシステムのScale-outは、ある程度まではWeb層とビジネス・ロジック層を多重化することで可能になるのですが、システム全体のデータを単一のデータベースが担っているので、その部分の多重化はできませんでした。
しかし、データベースが、3-Tierモデルのボトルネックになるというこの問題についても、BigTableは、新しい解決をもたらしました。
巨大なテーブルを、ネットワーク上のノードごとにキーの範囲で分割した小テーブル(Tablet)を分散配置することで、それらへの並列なアクセスが可能になったからです(図3-2参照)。
この点で、Scale-outする、超大容量の高速データ・ストアであるBigtTableのKey/Value型のデザインは、その後のクラウド・システムのデータベース設計に決定的な影響を与えることになります。
データセンター建設技術
今回の記事では書ききれませんでしたが、Googleでは、彼らの巨大な分散処理システムをデータセンターとして運用する際にそのエネルギー・コストの問題の重要性にいち早く気づきました。そして徹底して無駄を省き、経済的であると同時に環境にも配慮した(2重のeco)データセンター構築技術を作り上げたということについて、少しだけ触れておきます。
それでは、次回も引き続きクラウドについて解説していきます。
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
