運用担当者向けの自動化機能が充実
運用担当者向けの自動化機能が充実
バージョン8.4になり、運用性が向上する変更も行われています。
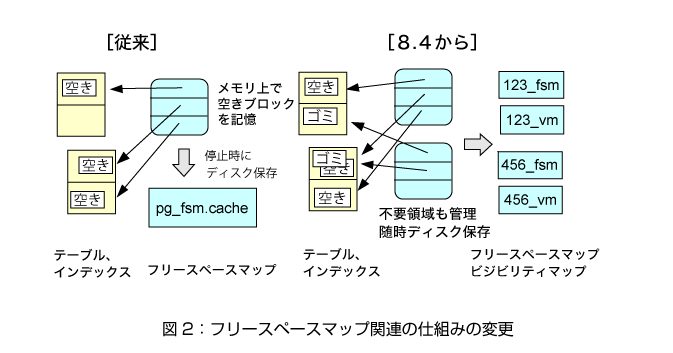
例えば、データ格納ファイルの空きブロックを記憶するフリースペースマップに関する設定項目が廃止され、自動的に調整されるようになりました。これまでは、データ規模に応じて、使用するメモリ量を管理者が設定する必要がありました(データ規模やアクセスパターンが変わると、それに応じた再設定が望ましいため、大変面倒でした)。さらに、単に自動化しただけでなく、仕組み全体も変更されています(図2)。
さらに、性能をチューニングする際に便利な機能として、インストールツール(contribツール)がオプションで追加されています。
このうちの1つ、contrib/pg_stat_statementsは、実行したSQL文と処理時間を、テーブル上に集計するものです。従来では、SQLの性能分析をしようと思った場合、これらの情報をいったんメッセージログファイルに出力させ、それを別途、何らかのツールや応急的に作ったスクリプトで分析する、ということが行われていました。contrib/pg_stat_statementsにより、これまでよりも簡単に性能を分析できるようになりました。
このほか、contrib/auto_explainは、SQLの計画プラン(実行計画)情報を自動で取得してくれるツールです。
PostgreSQLには、EXPLAIN文というSQL命令があります。実行するSQLについて、内部でどのような実行プランを立てているか、また、その結果、各処理の過程でどのようなデータを得て、どのように時間がかかったかを出力させることができます。
ところが、あるSQLが遅いと言われて、EXPLAINで分析しても、問題が再現しないことがよくあります。
ここで、contrib/auto_explainを使うと、あらかじめ指定した所要時間のしきい値を超えたSQLについて、その場でEXPLAINを取ってくれます。これにより、まさに問題が起こっている最中の分析データを得ることができるというわけです。
これらの機能は、まさに運用の現場にいる人の発案を反映したものであるといえます。
特定の場面で性能が向上
PostgreSQLバージョン8.4は、前版と比べると機能の向上が中心ですが、性能の向上も行われています。すべての処理に関係する基本部分の性能というよりは、特定の処理に当てはまる処理のときに大きく性能が改善されるといったものが中心です。前回記事(http://thinkit.jp/article/1045/1/)のpgbench結果のグラフにおいてバージョン8.3と差がないのはそのためです。
これまで、PostgreSQLでは、「(重複行を削除したい場面で)DISTINCTを使うくらいならGROUP BYを使ったほうが速い」というイディオム(ソフトウエア設計における小さなノウハウ)が知られていました。バージョン8.4では、このDISTINCTからGROUP BYへの変換が、プランナ内で自動化されました。もはやDISTINCTを使っても損はありません。
このほか、SQLの実行プランで利用可能な新たなクエリオペレータが追加され、IN、ANY、EXISTS句を使ったSQLの実行プランが改善されました。
また、ハッシュインデックスが大幅に書き換えられています。これまで、PostgreSQLのハッシュインデックスは性能面でBTreeインデックスに負けることが多く、あっても使われない存在でした。ところが、バージョン8.4からは、使用を検討すべき性能となりました。100文字以上の長い文字列に一致検索のインデックスを付ける場面では、ハッシュインデックスを検討しましょう。
テキストの全文検索機能においては、前方一致検索ができるようになりました。これまでは、(同義語や語形変化を調整する機能はあるにせよ)単語の一致検索しかできませんでした。また、全文検索に使われるGIN(Generalized Inverted Index)インデックスの更新にかかる時間を短縮するオプションが追加されました。
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
