導入しやすい工数見積もり手法とは
なぜ、モデルによる工数見積もりが普及しないのか 実際のエンタープライズ系ソフトウエア開発では、モデルを使った見積もりは全体の7%にすぎない。なぜモデルを使った見積もりが普及していないのか?今回は2つの理由を考えた上で、amazon.comの「推薦システム」などで採用されている協調フィルタリングの手
2008年10月20日 20:00
なぜ、モデルによる工数見積もりが普及しないのか
実際のエンタープライズ系ソフトウエア開発では、モデルを使った見積もりは全体の7%にすぎない。なぜモデルを使った見積もりが普及していないのか?今回は2つの理由を考えた上で、amazon.comの「推薦システム」などで採用されている協調フィルタリングの手法をモデルによる工数見積もりに応用し、新しい可能性を探る。
普及を妨げる理由の1つは、個々の見積もりモデルの適用可能範囲が狭く、自分たちのプロジェクトには当てはまらない可能性がある、という開発者の不安である。別の言い方をすれば、多様なソフトウエア開発プロジェクトを、1つのモデルで表現することの難しさである。例えば「モデルによる見積もりを自社プロジェクトに導入しようとする技術者」と「見積もりモデルに懐疑的なプロジェクトリーダー」との間では、図1のような会話が交わされることになる。
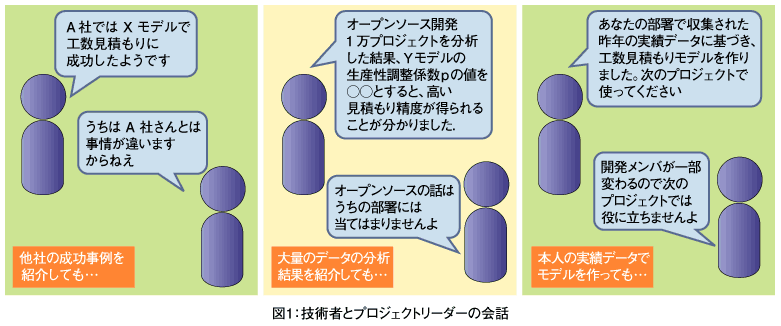
従来の工数見積もりモデルの問題点(1):適用範囲が狭い
図1のように、定量的なデータ分析を前にしても、プロジェクトの個別性を理由に導入に踏み切らないプロジェクトリーダーもいるだろう。
「第1回:工数見積もりの見える化(http://www.thinkit.co.jp/article/137/1/)」でも述べたように、COCOMOなどの既製モデルでは、見積もりに必要なパラメータ(説明変数)は開発規模(ソフトウエアサイズ)などによりあらかじめ定められており、パラメータ数もそれほど多くない。
見積もりを行うためのコストは比較的小さいと言えるが、同時に、そのモデルが前提としているソフトウエア開発が実際とずれていればいるほど、見積もり精度は低下する。
既製モデルでの見積もりに疑問がある場合、重回帰分析などによるモデル構築が1つの解決策となるが、そこでもやはりモデルの適用範囲が問題となる。重回帰分析では、モデル構築に使われた実績データに最もよく適合するようにモデルが構築される。実績データが多様なソフトウエア開発プロジェクトから集められていればよいが、それには膨大なコストと時間が必要となるため、実際には、モデル構築に用いられる実績データに多かれ少なかれ偏りが生じる。
その偏りが、自分たちのプロジェクトの実態からずれていればいるほど、先ほどの既製モデルの場合と同様、見積もり精度は低下することになる。他社でのソフトウエア開発やオープンソース開発での実績データに基づいて構築されたモデルでは、高い見積もり精度が得られないとプロジェクトリーダーが考えるのも無理はないのかもしれない。
そして2つ目の理由は、従来モデルの多くがデータ欠損に対して非常に脆弱(ぜいじゃく)であることだ。その原因や影響を次ページで解説する。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
