導入しやすい工数見積もり手法とは
従来の工数見積もりモデルの問題点(2):データ欠損に弱い
既製モデルでは、必要なパラメータの値がなければ見積もりが行えないように、重回帰分析によるモデル構築においても、データ欠損は大きな問題となる。データ欠損率が30%を超えると、重回帰分析により構築されたモデルの見積もり精度は著しく低下することが知られている。
例えば、情報処理推進機構ソフトウエア・エンジニアリング・センターが2005年3月までに15社から収集した1,009件のプロジェクト、約400種類の特性値(説明変数の候補)の実績データでは、全体の87.7%が欠損していた。ソフトウエア開発データの蓄積で世界的にも著名なInternational Software Benchmarking Standards Group(ISBSG)が2006年までに収集した、20か国、3,024件のプロジェクト、99種類の特性値の実績データでも、欠損率は57.6%である。いずれも30%をはるかに超える欠損率であり、これらをそのまま使って見積もりモデルを構築しても、高い精度は到底期待できない。
では、なぜ、ソフトウエア開発の実績データの欠損率がこれほどまでに高いのか。原因は、データ収集における不注意やミスだけではない。
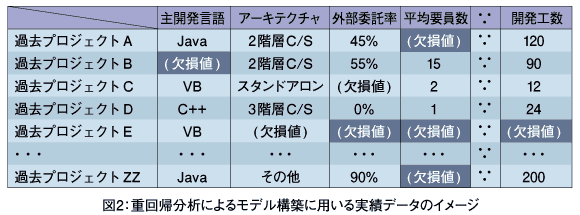
重回帰分析によるモデル構築に用いる実績データのイメージは、表計算ソフトで用いられるスプレッドシートのような二次元の表形式である。図2のように表の各行が(過去の)開発プロジェクト、各列がプロジェクト特性値(説明変数の候補)となる。データ欠損とは、この表形式のセルに実績データが入っていない状態であり、実績データの入っていないセルの割合が欠損率となる。
なぜ欠損率が高くなるのか
欠損率が高くなる大きな理由は、ソフトウエア開発そのものやデータ収集の体制が異なる多様なプロジェクトから実績データが集められていることにある。
例えば、ソフトウエア規模を表す特性値として、ある組織のプロジェクトではプログラム行数(LOC)が記録され、ほかの組織ではファンクションポイントが記録されているとする。それぞれの組織内だけで見ればデータの欠損はないが、それらを合わせて図2に示すような表を作成すると、前者はファンクションポイントのデータが、後者はプログラム行数のデータが、欠損していることになる。平均要員数や発見不具合数が開発工程ごとに収集されているような場合など、開発工程の区切りがプロジェクト間で異なれば、それらデータは同一とみなすことができず、データ欠損率は一気に押し上げられることになる。
データ欠損率を大幅に下げる1つの方法は、収集すべきプロジェクト特性値だけでなく、その収集手順や収集ツールなどを組織全体で統一することである。しかし、そうした統一には、多くのコストと時間が必要となる。米国Software Engineering Institute(SEI)の報告によると、一貫したデータ収集体制を整えるために平均で43か月もの時間が必要とされている。そのような時間とコストを先行投資できる組織は少ないだろう。
以上が、モデルを使った見積もりがソフトウエア開発の現場において必ずしも普及していない主な理由であるが、さらに深刻なのは、これら2つの問題が絡み合っている点である。
つまり、「見積もりモデルの適用可能範囲が狭い」という1つ目の問題を回避するには、自分たちの組織や開発プロジェクトも含め、多様なソフトウエア開発の実績データを収集し、蓄積すればよい。しかし、多様な組織やプロジェクトから収集されたデータは、一般に欠損率が高く、「見積もりモデルがデータ欠損に脆弱である」という2つ目の問題に直面することになる。
一方、「見積もりモデルがデータ欠損に脆弱である」という2つ目の問題を回避するには、一貫したデータ収集体制を整えればよい。しかし、そのためには膨大な時間やコストだけでなく、統一的なデータ収集体制が必要であるが、それをきちんと整えるのが困難だ。結局、どのようなソフトウエア開発においても収集可能な、最大公約数的な特性値だけが実績データとして収集されることになる。しかしそれでは、個別性の高いソフトウエア開発プロジェクトの特性が見積もりモデルに反映されず、「見積もりモデルの適用可能範囲が狭い」という1つ目の問題に直面することになる。
では、どうするか。ここで少し違う視点で見積もりをとらえてみると、別の可能性が見えてくる。






