KubeConにKelsey Hightower氏登壇、コンテナからサーバーレスへ移行するデモを実演
KubeCon Seattle、最終日にKelsey Hightower氏が登壇し、コンテナからサーバーレスへと移行するデモで魅せた。
2019年1月29日 6:00
KubeCon最終日のキーノートでは、Uberの巨大な分散データベースのユースケース、GoogleのJanet Kuo氏によるKubernetesのエコシステムに関するアップデート、Red HatのRob Szumski氏によるOperator Frameworkの説明があり、そして最後にGoogleのKelsey Hightower氏によるプレゼンテーションとデモが行われ、最終日にふさわしい豪華な内容となった。
Kelsey Hightower氏によるデモ
Kelsey Hightower氏はこれまでも多くのカンファレンスで、Kubernetesやサーバーレスのプレゼンテーションを実施しており、常に注目されている存在だ。その理由はほとんどスライドを使わずにデモ、それもライブデモを中心にプレゼンテーションを組み立てることで、観客を引き込む強力な魅力と伝えたいメッセージをデモの形に作り込む技術があるからだろう。今回もサーバーレスに関する非常に説得力のあるコンテンツとなった。

GoogleのKelsey Hightower氏
Hightower氏は2016年に公開された「Hidden Figures」(邦題は「ドリーム」という陳腐なものなので、ここではHidden Figures、つまりNASAの宇宙計画に存在した黒人女性エンジニアたちが文字通り影に隠れた人物たちであったという意味に敬意を表して、英語表記のままとする)のエピソードを紹介するところから始まった。
これまで筆者が見たHightower氏のプレゼンテーションは、1枚のスライドに自分の名前とセッションタイトルだけというものがほとんどだったが、今回はHidden Figuresの登場人物、Dorothy Vaughanのシーンを借りて、数学に長けたエンジニアが紙と鉛筆による計算からIBMのコンピュータを借りてFortranを使って軌道計算などを行う部分に触れ、「手段がどうであれ、最も重要なのはその仕事の中身」として、暗にKubernetesやサーバーレスなどのプラットフォームの部分に注目が集まることを批判したように思える出だしとなった。

Fortranを紹介するHightower氏
つまり紙と鉛筆だろうが、IBMのコンピュータ上でFortranを使おうが、軌道計算を行って宇宙飛行士を地上に戻すと言う仕事そのものには変わりはないということから、コンテナがオーケストレーションされようが、サーバーレスのファンクションとして実行されようが、やるべき仕事の内容には変わりはないということを実演する流れとなった。
ここからデモが開始される。Fortranの簡単なソースコードを見せ、質量(mass)に速度(velocity)を乗算して運動量(momentum)を得るという非常にシンプルかつHidden Figuresに沿ったコードをコンテナで実行するところから始まった。
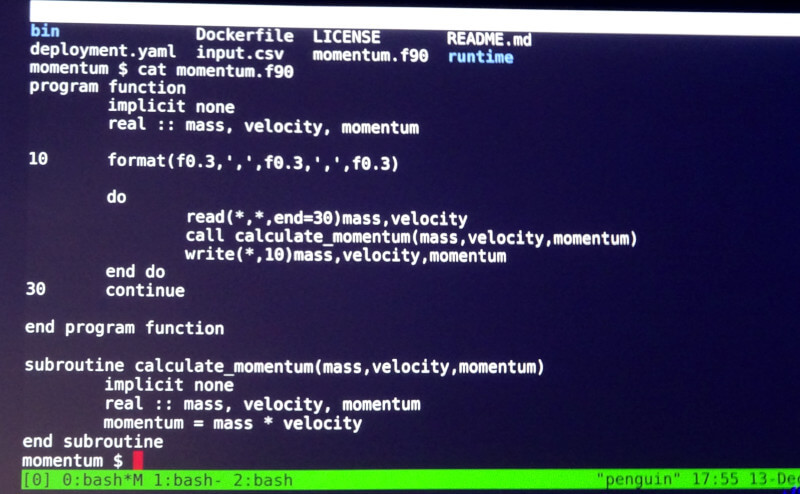
デモで使われたシンプルなFortranのソースコード
そのコードをGCPを使ってコンテナの中で実行し、入力データとなるCSVからデータを読み込み、乗算を行った結果が表示されるところで、会場からは少ないながらも拍手が起こる。
次に作成されたコンテナイメージをDiveというツールでコンテナのレイヤーを可視化し、その中から必要な実行形式のファイルを会場に示した。
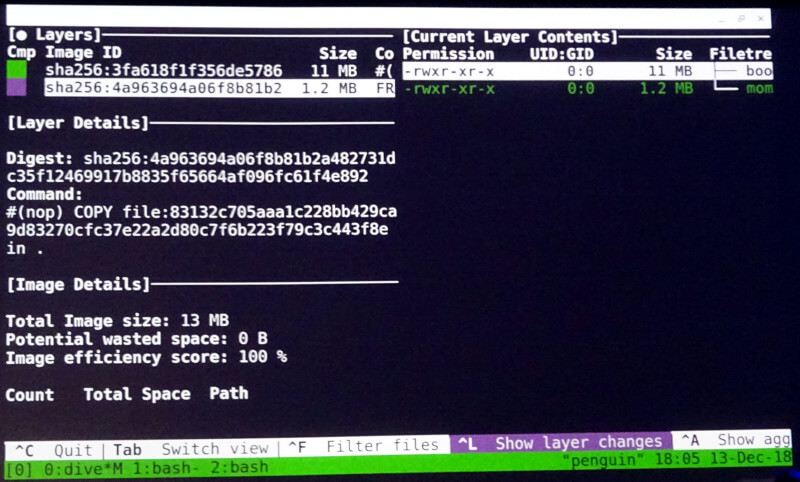
Diveを使ってコンテナのレイヤーを可視化
その次が、今回のデモの最も湧いた部分だ。それはHightower氏が自ら開発したというdianaというツールを用いてコンテナから必要なイメージを抜き出し、それをAWS Lambdaで実行できるようにZIPファイルにまとめるというフェーズだ。コマンドラインから入力された直後に「I'm coming out ...」というメッセージがターミナルに表示され、同時にダイアナ・ロスのヒット曲「I'm Coming out」が再生されたのだ。
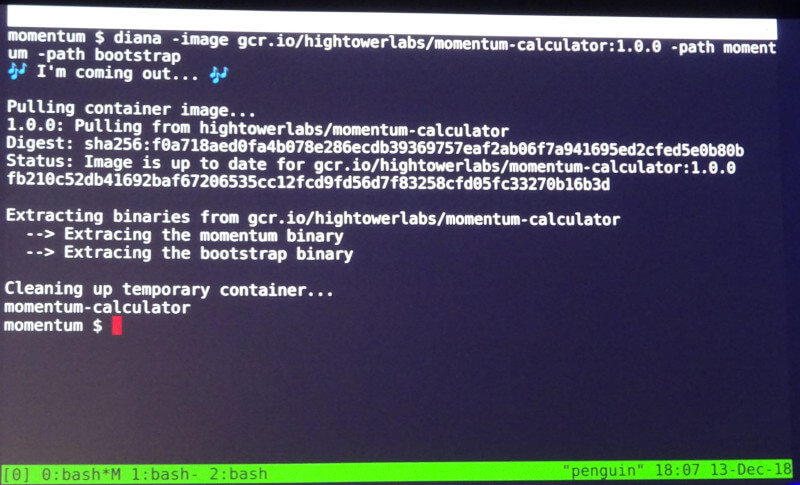
ダイアナ・ロスのヒット曲が再生された瞬間。会場は大ウケだ
この曲は1980年にリリースされたもので、当時の売れっ子ミュージシャンChicのギタリストのNile Rodgersと、ベーシストのBernard Edwardsによって作られたもので、コンテナからイメージファイルを取り出すという部分と「I'm Coming out」というフレーズが見事にシンクしており、KubeConの会期中で最も湧いた瞬間となった。
実際にこの音源を開始するタイミングとツールの実行を合わせるのが非常に難しかったと語り、このデモに賭けたKelsey Hightower氏のこだわりを見た瞬間となった。その後、それをAWSにアップロードし、CSVデータをアップロードした段階でトリガーが実行され、AWSのLambdaのファンクションとして、このFortranのアプリケーションが実行されたことを確認した。
コンテナがGCP上で実行され、ソースコードを何も変更せずにそれをAWSのサーバーレスプラットフォームで実行する、大事なのは環境ではなく、デベロッパーが書くコードであり、そのためにインフラストラクチャーはもっと抽象化されるべき、サーバーレスはそのための最適な道筋である。このメッセージを、シンプルなデモでまとめたHightower氏の本領発揮と言えるセッションとなった。かつて「GCPは私にとってのオンプレミスだよ」とステージ上でコメントしたこともあるHightower氏だが、サーバーレスの実行環境と言う部分では先行するAWS Lambdaを使うという部分も非常に説得力があるものだった。
Kelsey Hightower氏のキーノート動画:Kubernetes and the Path to Serverless - Kelsey Hightower, Staff Developer Advocate, Google
UberのM3DBの解説
最終日のこの日は、他にもUberの分散タイムシリーズデータベースであるM3DBに関する解説があった。これはUberが利用する自社製のタイムシリーズデータベースで、オープンソースの分散データベースCassandraとFacebookが開発したインメモリーデータストアGorillaにインスパイアされたものであるという(Gorillaは、システムのモニタリング用のデータをストアするものとして開発された)。
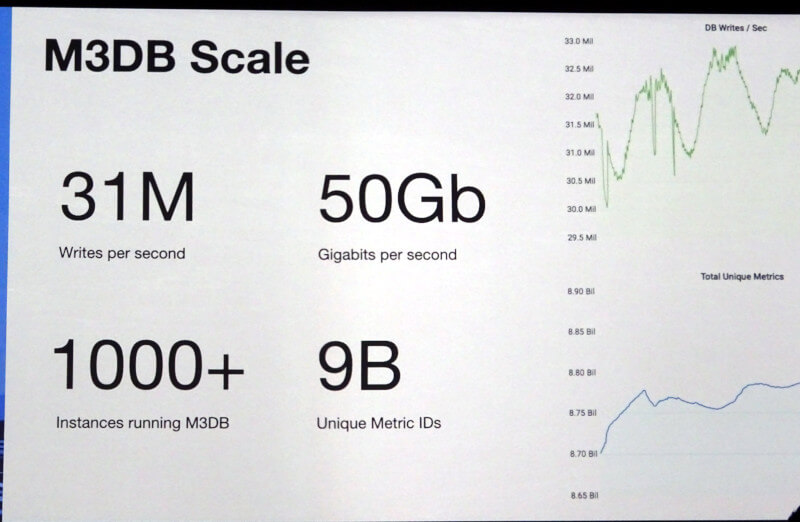
UberのM3DBの規模感がわかるスライド
スライド:What is M3?
参考:M3: Uber’s Open Source, Large-scale Metrics Platform for Prometheus
詳細なドキュメンテーション:M3DB, a distributed time series database
2016年は2クラスターで構成も1種類だけだったものが、2018年現在は40以上のクラスターで稼働、構成は10種類以上存在する。Uberが利用する多くのサーバー/クラスターのメトリクス情報をストアし、障害時に原因解析のために利用するというのがM3DBの目的だ。Uberの巨大かつ地理的に分散されたトラフィックからメトリクスを保存するためには、シングルノードのPrometheusではダメで、分散したクラスターからのメトリクスに最適なデータストアを考えた時に、ブロックストレージやオブジェクトストレージなども検討したが、最終的にKubernetesにアタッチしたローカルストレージを集約する分散データベースに落ち着いたという。
またUberはM3DB運用のためにOperator Frameworkを活用して、よりプロアクティブな運用を行っている点にも注目だ。

Operatorによってプロアクティブな運用を実行
またKubernetesが持つ宣言的な設計思想が、手続き的な運用方法よりも巨大なシステムの運用には適していると解説した。これは常にあるべき姿(ノード数やPod数など)を宣言し、それを達成するようにKubernetesが自律的に稼働するという部分の解説だが、ペットではなく家畜的にサーバー資源を扱うためには必要な発想だろう。

手続き的ではなく宣言的なシステム運用
Operatorは、この後のRed Hatのセッションでも紹介されたが、CoreOS発祥のソフトウェアとしてRed Hatが強力にプッシュしており、アプリケーションに最適化されたKubernetes運用のためのノウハウが凝縮されたものだ。
この流れで、Red HatのRob Szumski氏によるOperator Frameworkに関するセッションを紹介しよう。これはGoogleのKelsey Hightower氏の直前に行われたもので、3大パブリッククラウドとオンプレミスのハイブリッドクラウドを拡めたいRed Hatにとって、絶好のチャンスとなった。

Operator Frameworkを紹介するRed HatのSzumski氏
Szumski氏はKubernetesが導入される段階として3つのフェーズを紹介。最初はステートレスなアプリケーションのためのプラットフォームとして使う段階、次がレガシーなステートフルなアプリケーションとストレージのために使う段階、その後さらに進化して複雑な分散システムのためのプラットフォームとして使う段階に進んでいくと説明した。その際に運用のためのベストプラクティスが、個々のユーザーやベンダーにだけ存在させるのではなく、それを再利用するための仕組みが必要であるというのが、Operatorを開発した背景であるという。

Kubernetes利用の3段階
様々なユーザー企業が自前のKaaS(Kubernetes-as-a-Service)を作り始めていることが背景にあるとは言え、抽象化するためのコマンドラインツールやユーティリティを作るのではなく、アプリケーションごとのノウハウをコードとして流通させようというのは、いかにもRed Hatらしいやり方のように思える。

運用者のノウハウを凝縮したものがOperator
すでにGitHubにはOperator Frameworkのマーケットプレイスが存在しているが、現状ではPre-Alphaバージョンであり、Red HatのOpenShiftのアップストリーム版のOKDをベースにしたドキュメンテーションとなっている。そのため、パブリッククラウドやオンプレミスの素のKubernetesで利用するためには、もう少し時間が必要かもしれない。
参考:https://github.com/operator-framework/operator-marketplace
続いてSzumski氏は、Operator Frameworkを構成するSDK、Lifecycle Manager、Meteringの3つを説明した。それぞれまだAlphaバージョンであるということだが、興味深いのはOperator Frameworkそのものが実際にはOperatorで構成されているというメタな構造だろうか。

Operator Frameworkの3つのコンポーネント
クラウドネイティブなシステムにおいて多く使われるコンポーネントについては、すでにベンダーオフィシャルのものが多く用意されている。しかし同じコンポーネント用に複数のOperatorが存在するという状況も発生していること、またドキュメンテーションの品質にも差があることなどを見ても、成熟していくのはこれからという状況だろう。この辺りは、Red Hatが持つコミュニティ運用の経験が必要となっていくと思われる。

すでに存在する各種のOperator
https://github.com/operator-framework/awesome-operators
Kubernetesの最新状況まで解説
最後に、GoogleのJanet Kuo氏のプレゼンテーションを紹介する。Kubernetesに関してはKubeConの語り部として上海から登壇しているKuo氏だが、わかりやすいゆっくりとした英語と訥々とした雰囲気で、Kubernetesの生い立ちから最新の状況までを解説した。

Kubernetesの宣言的な設計思想について語るKuo氏
特に最後に挙げた「どうしてKubernetesは単なる流行から、リアルなプラットフォームとして生き残ったのか?」という部分については、Googleでの開発と運用の歴史、ユーザー主体の開発コミュニティ、宣言的なAPIと自動化機能、パブリッククラウドからオンプレミス、SaaSまで稼働する幅広さなどに加えて、最も重要な要因として挙げたのがコミュニティの存在だった。

Janet Kuo氏が挙げたKubernetes成功の要因
この写真は1番目の要因であるCommunityが出てくる前に撮影したものだったが、コミュニティが最も大きな要因だと語ったのは印象的だった。つまり最も大きな貢献をしているGoogleの影響よりも、この会場に集っているエンジニアからの協力、コラボレーションが成功の要因だと締めくくったわけで、これからもコミュニティを重視するというGoogleの、そしてCNCFの姿勢の現れを見た瞬間だった。
Janet Kuo氏のキーノート動画:Kubernetes Project Update - Janet Kuo, Software Engineer, Google
2018年最後のKubeCon North America最終日のキーノートは、サーバーレスのライブデモ、Operator Framework、そしてUberのユースケースと、非常に内容に富んだものとなった。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
