KubeCon Seattleでも耳目を集めたカオスエンジニアリング
意図的にシステムを壊すカオスエンジニアリングはKubeCon Seattleでも注目されており、2セッションが開催された。
2019年1月30日 6:00
これまで紹介してきたように、KubeConではサービスメッシュやサーバーレスだけではなく、Kubernetesのエコシステムを拡大する様々なツールが紹介されていた。このレポートではちょっと趣向を変えて「意図的にシステムを破壊することで、耐障害性を高めるカオスエンジニアリング」のセッションを紹介したい。これはIntroductionとDeep Diveの2セッションが2日間に渡って行われたものだ。セッションを担当したのは、ChaosIQのCo-FounderでCTOのSylvain Hellegouarch氏と、56K CloudのJulien Bisconti氏だ。
Introduction

ChaosIQのCTO、Sylvain Hellegouarch氏
ここでHellegouarch氏はカオスエンジニアリングの始まりとして、いくつかの過去の経歴を説明した。まず、Amazonで最初にGameDayという障害を起こすイベントを考え出した「Master of Disaster」と呼ばれるJesse Robbins氏を紹介。Amazonでは2004年頃から、意図的に障害を起こすことでWebシステムの信頼性を高めるためのエンジニアリングをしていたようだ。その後、NetflixがChaos Monkeyを2010年頃に開発、Simian Armyというツールセットの名前で公開されたのは2012年だ。その後、Gremlinが2016年に創業、2018年9月には最初のChaos Conferenceが開催された。
そのChaos Conferenceでキーノートに立ったのが、AWSのVPであるAdrian Cockroft氏だ。このChaos Conferenceでは、なぜAWSがChaos Engineeringに注目しているのかが解説されている。この中から、Chaos Engineeringの定義の部分を抜き出してみよう。

AWSのAdrian Cockroft氏によるカオスエンジニアリングの定義
ここでCockroft氏は、カオスエンジニアリングを「本番環境において破滅的な状況になった際に信頼できるシステムの可用性を構築するための実験」であると語っている。つまり火災や洪水などの自然現象から、コンピュータハードウェアの故障、さらにバグや外部からの攻撃までを含んだ本番システムに破滅的な被害が及んだ時に、どういう対応をするべきかを実際に実験してみるための行為が、カオスエンジニアリングであるという定義だ。
この定義を理解した上で、Sylvain Hellegouarch氏のIntroductionのセッションを紹介しよう。
Hellegouarch氏は上述のAdrian Cockroft氏のキーノートを参考として紹介し、その後にスペースステーションの事故を紹介、続いてイギリスの通信会社O2の通信障害について解説を行った。O2の通信障害については、2018年の12月に起きたソフトバンクの携帯通信網における通信障害(原因は証明書の失効による)として記憶されている方も多いだろう。
そこから、CNCFに提案しているカオスエンジニアリングのワーキンググループなどについて説明を行った。全体として壊れることが不可避な複雑なクラウドネイティブのシステムにおいては、障害を避けるのではなく、障害が起こることを前提としてシステムを構築するべきという解説を行った。
ここで重要なのは、ディザスターリカバリーのように「Aという障害が起こった時はBという対応を行う」という発想ではなく、想定しない障害が起こることを前提として実験を行い、それに耐えうるシステムを作ろうという姿勢だ。つまり全ての障害を記述することは出来ないため、常に何かが壊れてしまうというようにシステムを意図的に壊したり、失敗を注入したりすることで、それに起因して何がどこまで壊れるのかを観測するという実験の発想だ。結果的に壊すことが目的なのではなく、壊れても元に戻るシステムを作るための基礎的なデータを取るというのが、カオスエンジニアリングの真髄であろう。

誰もが信頼性の高いシステムを必要としている
1日目のIntroductionはスライドを使ったレクチャーが中心となり、Hellegouarch氏としてはもっとデモを見せたかったようだ。それは次の日のDeep Diveに任せて、ここでは前提条件とカオスエンジニアリングの基礎を示すことに終始した。
Deep Dive
2日目に行われたDeep Diveに登壇したのは、スイスにあるコンテナ関連のコンサルティング会社の56kCloudのJulien Bisconti氏だ。Bisconti氏が前半のデモを担当し、後半のデモと説明を行ったのは前日のHellegouarch氏だ。
このDeep Diveセッションでは、Bisconti氏がインターネットのRFC1925で記述されている「12のネットワークに関する真実」というジョークRFCからの引用を紹介。これはインターネットで信用してはいけない項目を説明した。すべての項目が否定されるべき内容になっていることに注意されたい。つまり、ネットワークは信用できないし、遅延はゼロではなく、帯域は無限ではないなどなど、昨今のネットワークエンジニアであれば、頷ける内容だ。
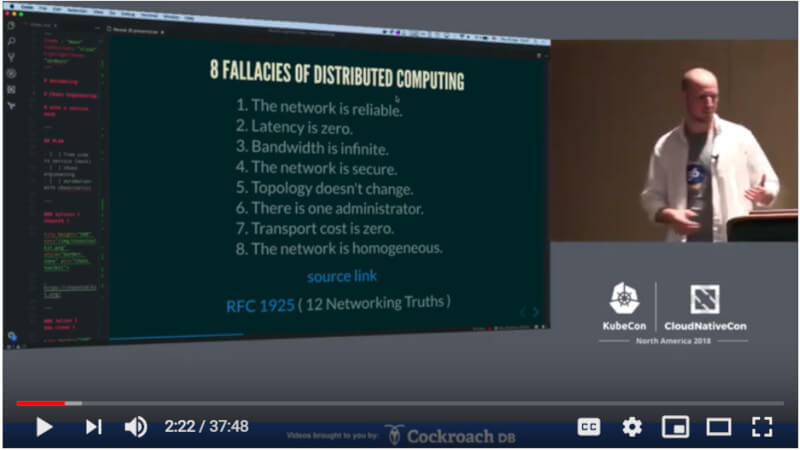
ネットワークのリアルを紹介するBisconti氏
次にコンテナについて言及し、コンテナ自身は良い技術だが、まだ足らない部分があり、それを補完したのがKubernetesであるという。

コンテナの不足部分を補うKubernetes
さらにKubernetesにおいても足らない部分、ロギングやトレーシング、サーキットブレーキング、フェイルオーバーなどを補う形で登場したのが、サービスメッシュであるという筋書きだ。

Kubernetesに足らない部分
Bisconti氏はサービスメッシュはサービス同士の通信を担当すると紹介し、ここからデモを行う段となった。Istioを使って本のレビューを行うサンプルサイトをマイクロサービスとして構成、そこからレビューのプロセスがV1からV2、V3とアップデートされる部分を使って解説した。Istioのプロセス間の通信の可視化にはKialiを用いて、実際にどのようにトラフィックが流れているのかを示した。
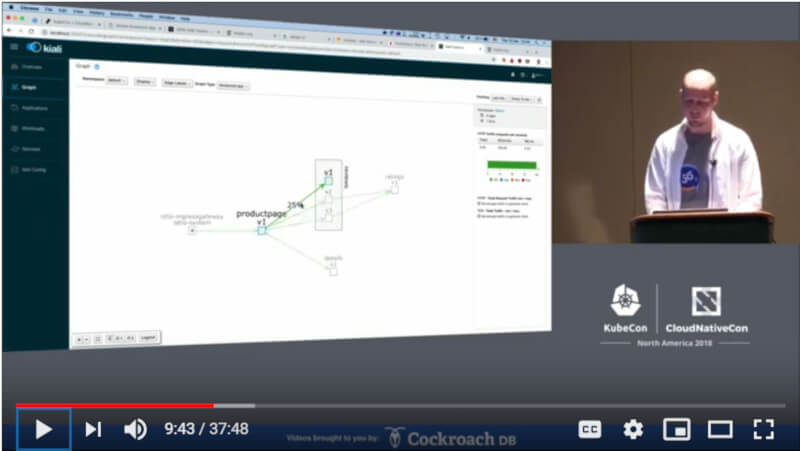
Kialiを使ってトラフィックを可視化
その後で、Istioのパラメータを変えてトラフィックの割合が変化する部分をデモンストレーションとして見せた。ここまでの部分は、Istioのサービスメッシュの機能を紹介したに過ぎない。ここからChaos Toolkitの紹介を行うHellegouarch氏にバトンタッチした。
Hellegouarch氏は、前日のIntroductionはスライドが多過ぎたとして、Chaos Toolkitのデモを実施。Chaos Toolkitはオープンソースソフトウェアとして公開されているもので、Hellegouarch氏が創業したChaosIQはそれに機能を追加し、エンタープライズ向けSaaS及びオンプレミス用のソフトウェアとして提供している。
参考:オープンソースソフトウェアのChaos Toolkit
Hellegouarch氏は、デモとして今回のサンプルサイトに意図的に遅延が発生するような設定を行ってその実行ログを見せた。ここでのポイントは遅延を起こすことが目的ではなく、それが起きたとしてビジネスとしてそれを許容できるのかを判断すると言う部分だろう。もしもそれが許容できるなら、それは障害ではないし、それ以外を実験するべき、というスタンスだ。通常のWebサイトであれば、全体もしくは一部の表示に数秒の遅延があれば大きな問題だが、それを実際に起こしてビジネスオーナーと議論することができるのは大きな進歩だ。
興味深いのは「失敗」、この場合Webアプリケーションのレスポンスが遅くなるというものを故意に設定すると、1回目は正常に動いた後で、実際に記述された「遅れ」が注入され、Webのレスポンスが遅くなると言う部分だろう。1回目が正常に動くのは正常時と異常時を比較するためだと説明した。Chaos Toolkitの大きなポイントは、意図的に起こした障害をRollbackできる機能だろう。その後、実際にレポートを出力する機能を見せて、失敗を注入することによる影響を確認することができるのも、カオスエンジニアリングが単に「壊す」だけのものではないという部分を強調した形になった。
また、単にスタンドアローンの実験を行うだけではなく、チームでその実験を共有することで、組織の中で共有する機能があるという部分も実際に開発及び運用がチームで行われていることに即したツールになっていることを紹介した。この部分は、ChaosIQが提供する有償のEnterprise版の機能のように見えるが、あえてそこは説明しなかったようだ。
全体としてサービスメッシュのデモからChaos Toolkitのデモまで駆け足ではあるが、網羅した良いセッションだったように思える。失敗を意図的に起こすというとリスクが高いように思えるが、サービスメッシュの通信をわざと遅くすることでどこまで影響が及ぶのか? といった使い方なら十分に応用範囲が見えてくると思えるセッションとなった。
Deep Dive Chaos Engineering BoFの動画は、以下から参照できる。
Deep Dive:Chaos Engineering BoF - Sylvain Hellegouarch, ChaosIQ & Julien Bisconti, 56k.cloud
この記事をシェアしてください
関連記事
Gremlinがアプリレベルの障害注入ソリューションALFIを発表
2018年11月7日 6:00
Red Hat Summit 2019で訊いたAPI管理と開発ツールがRed Hatにとって重要な理由
2019年6月19日 6:00
CNCFのサンドボックスプロジェクト、カオスエンジニアリングのLitmus Chaosを紹介
2021年7月1日 7:29
KubeCon 2日目の注目はAirbnbのユースケースとBallerina
2019年1月25日 6:00
JKD v18.12でWantedlyが語ったマイクロサービス導入の実態
2019年1月11日 6:00
KubeConで失敗を紹介したMonzo Bankのキーノート
2018年5月29日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
