はじめに
前回は、学習済みモデルを利用したシステム/サービスの特徴と、学習済みモデルを利用する際の注意点の1つである「ユーザーのデータリテラシ(分析結果を理解し、それを説明できる能力)」について解説しました。今回は、学習済みモデルを利用する際のもう1つの注意点である「学習済みモデル開発における従来とは異なるソフトウェア開発方式や契約形態」について解説します。
学習済みモデル開発の特徴
自社固有のデータを活用して一から開発する場合には、従来とは異なるソフトウェア開発方式と契約形態が必要となるという点にも注意を払う必要があります。そこで、その前提となる「AI・データの利用に関する契約ガイドライン」のAI編に示されている学習済みモデル開発の特徴を理解しておきましょう。
「AI・データの利用に関する契約ガイドライン(以下、「ガイドライン」)」は、2018年6月15日に経済産業省が公表したもので、AI関連のプロジェクトに携わるあらゆる立場の人間が把握すべき内容を示しています。このガイドラインは、AI編とデータ編で構成されており、そのうちのAI編で示されている学習済みモデル開発の特徴は、次の4点です。
- 学習済みモデルの内容・性質などが契約締結時に不明瞭な場合が多い
- 学習済みモデルの内容・性能などが学習用データセットによって左右される
- ノウハウの重要性が特に高い
- 生成物についてさらなる再利用の需要が存在する
学習済みモデルを利用したシステムやサービスは、AI/機械学習の技術を利用して開発されているため、このような特徴があてはまります。特に(2)は重要で、一旦完成し、結果の精度が保証されたと思われるシステムやサービスでも、学習用データセット、つまり実績データが変化することで精度も変化するため、追加学習が必要となります。
学習済みモデルの開発方式
学習済みモデルを開発する場合、従来のウォーターフォール型の開発方式は適しません。そのため、前述したガイドラインのAI編では探索的段階型の開発方式が提唱されています。「探索的段階型」とは、開発工程ごとに目的の実現可能性を検証し、次工程へ進む可否を探索しながら当事者相互の確認をとって開発を進める方式を指します。
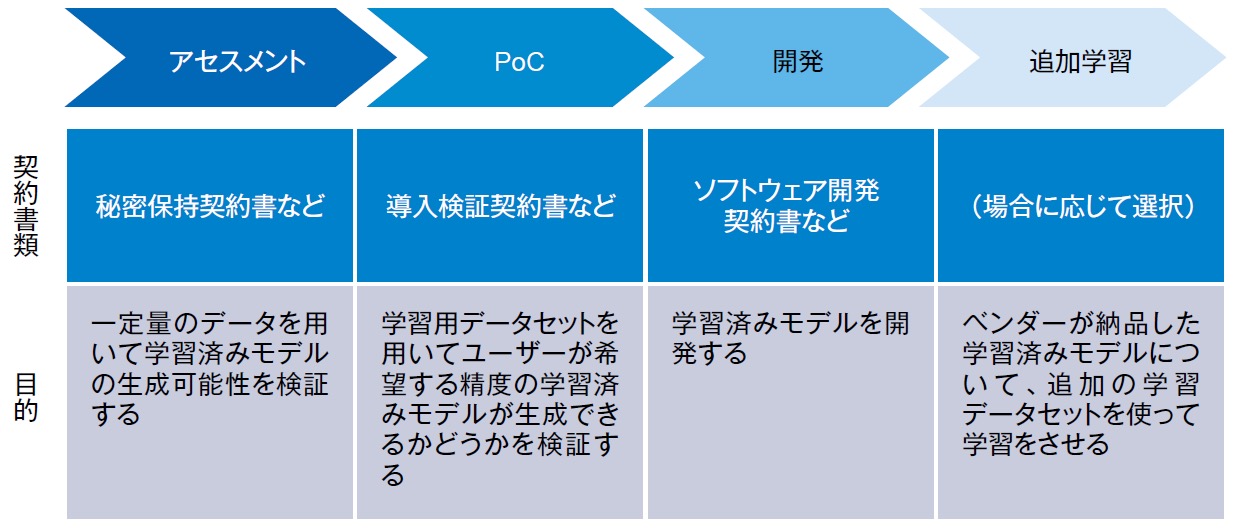
図1:探索的段階型の開発方式【出典】ITR
ここで理解すべきは、学習済みモデル開発とは、アセスメント、PoC、開発、追加学習のそれぞれの段階で学習済みモデル生成のプロセスを実施し、試行錯誤を繰り返しながらユーザーの求める品質の学習済みモデルにしていく点です。したがって、アセスメントは、従来のシステム開発におけるフィージビリティスタディのレベル感の評価や効果測定は想定されていません。
また、AI編においてこの段階で利用すべき契約書雛形として示された「秘密保持契約書」は、従来のシステム開発において提案依頼の前段で複数のベンダーと締結する秘密保持契約書と比べ、いくつかの点で異なります。それは、利用企業側がベンダーにサンプルデータを提供することを前提にするほか、サンプルデータの取り扱いを定めた例を示すこと、簡便ではあるが知的財産権の条項を設けている点などです。
つまり、アセスメントでベンダーに提供したデータの品質とボリュームでどの程度の成果が得られたかというレポートを提出し、これを基に最終的にどのような学習済みモデルが開発可能かを利用企業自身も推測してPoCに進むかを判断することを想定した内容となります。
追加学習段階の契約
探索的段階型の開発方式で示された追加学習はどのようなものでしょうか。従来型のソフトウェア開発では「開発」が最終段階であり、開発完了をもって保守フェーズに移行します。しかし、AI技術を利用したソフトウェア開発では開発完了の明確な線引きがなく、場合によっては開発の段階で調整を繰り返し行うこともありえます。そういった段階を経て実施される追加学習は、ベンダーが納品した学習済みモデルに対し、改めて品質を向上させるために追加データを用いた学習を行う再調整のような段階です。そして「追加」という言葉から誤解される場合がありますが、AI技術を利用したソフトウェア開発においては、追加学習の段階は必須となります。
ガイドラインでは開発と追加学習が分かれていますが、追加学習が学習済みモデルの精度向上に必須であることから、速やかにプロジェクトを進捗させるために開発段階の契約に追加学習を含めることが望ましいといえます。開発を実施したベンダーとは異なるベンダーに追加学習の依頼を検討していない限り、追加学習の条件なども開発契約に盛り込むことが推奨されます。
学習済みモデル開発の契約形態
次に、AI技術を利用したソフトウェアの開発で望まれる契約形態について確認しましょう。
従来型のシステム開発においては、2007年に経済産業省が公表した「情報システム・モデル取引・契約書」で示唆された通り、開発工程ごとに契約を分割し、さらに成果物により請負契約と準委任契約を使い分ける「多段階契約」が推奨されています。つまり、従来のソフトウェア開発は、企画・要件定義などの工程に応じて契約形態を考慮する必要があったものの、開発段階ではほぼ請負契約が採用されてきたと考えられます。
しかし、AI技術を利用したソフトウェアの開発では、これとは異なり、全段階で準委任型の契約締結がガイドラインでは推奨されています。その理由は探索的段階型の開発方式の特性で述べた通り、各段階における契約締結までに成果物である学習済みモデルの仕様や検収基準を確定させることが難しいことにあります。これは設計開発の工程も同様で、AI開発はその品質が開発段階においても保証できないため、準委任型でベンダーと協調しながら開発することになるといえます。
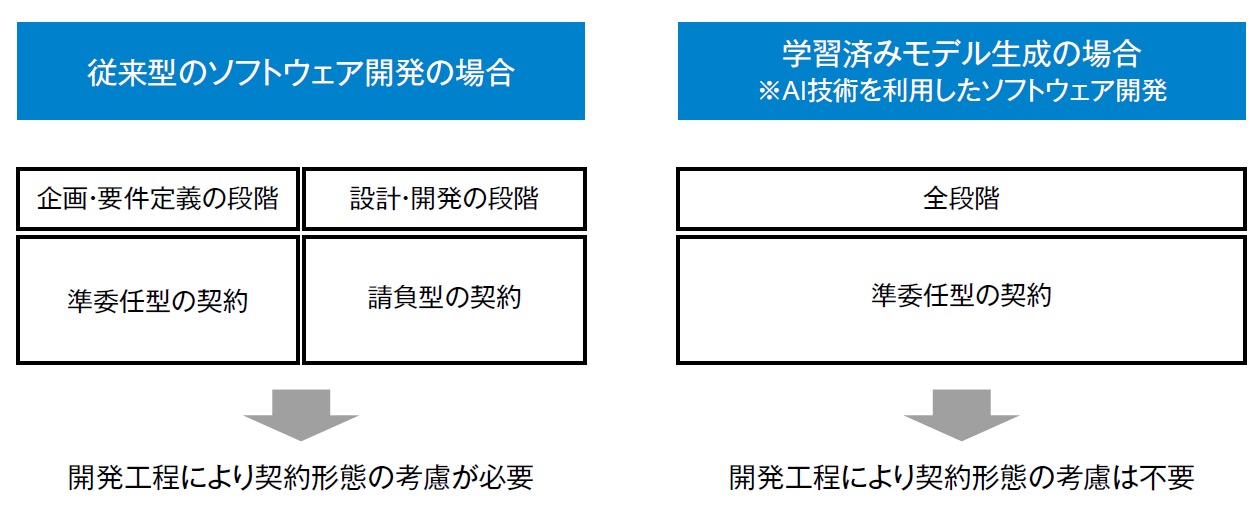
図2:学習済みモデル開発の契約形態の従来との違い【出典】ITR
おわりに
今回まで、データ分析の高度化ステップの最終段階である「推論・予測」までを解説してきました。これまでに登場した分析用データベースであるデータウェアハウスとデータレイクは、いずれも分析用データを物理的に1箇所に統合するというのが基本的な考え方になっています。しかし、今後はデータ分析システムを支えるデータベース構成はより複雑化し、システム間でのデータ連携を必要とするものになっていくでしょう。このような複雑なシステムを企画、構築、運用するためには、データマネジメントの知識が必要不可欠となってきますが、データマネジメントが対象とする範囲は広く、実現方法も多岐にわたるため、全体像を体系的に理解すると同時に、実現に向けては段階的な取り組みが必要となるでしょう。
そこで、次回からはテーマを「データマネジメントの基礎を学ぶ」と改め、データマネジメントを体系化したDMBOK(Data Management Body of Knowledge)の概要と、その最新版で追加されたデータ統合領域を解説するとともに、データマネジメントの高度化ステップについて考察していきます。
この記事をシェアしてください
関連記事
データマネジメントの基礎を学ぶ(4)データマネジメント高度化ステップ(後編)
2022年3月11日 6:30
データマネジメントの基礎を学ぶ(1)データマネジメントの全体像
2021年12月17日 16:31
データマネジメントの基礎を学ぶ(3)データマネジメント高度化ステップ(前編)
2022年2月9日 6:30
AI/機械学習とデータ分析の関係を知る(1)データ分析業務と組織の現状
2021年8月4日 6:47
データマネジメントの基礎を学ぶ(2)データ統合の実現方法
2022年1月25日 6:30
データ分析システムの全体像を理解する(1) データ分析の高度化ステップ
2020年12月17日 8:20
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
