Oracle Cloud Hangout Cafe Season 4 #5「Kubernetesのオートスケーリング」(2021年8月4日開催)
第2弾の連載第6回では、2021年8月4日に開催された「Oracle Cloud Hangout Cafe Season4 #5『Kubernetesのオートスケーリング』」の発表内容に基づいて紹介していきます。
2024年5月29日 6:30
目次
- はじめに
- スケールの復習とKubernetesにおけるスケールの種類
- Podの水平スケール
以降では、上記で整理した3つのスケール手法について深掘りしていきます。まずは、Podの水平スケール(Horizontal Pod Autoscaler、以下HPA)から見ていきます。
Podの水平スケールの概要
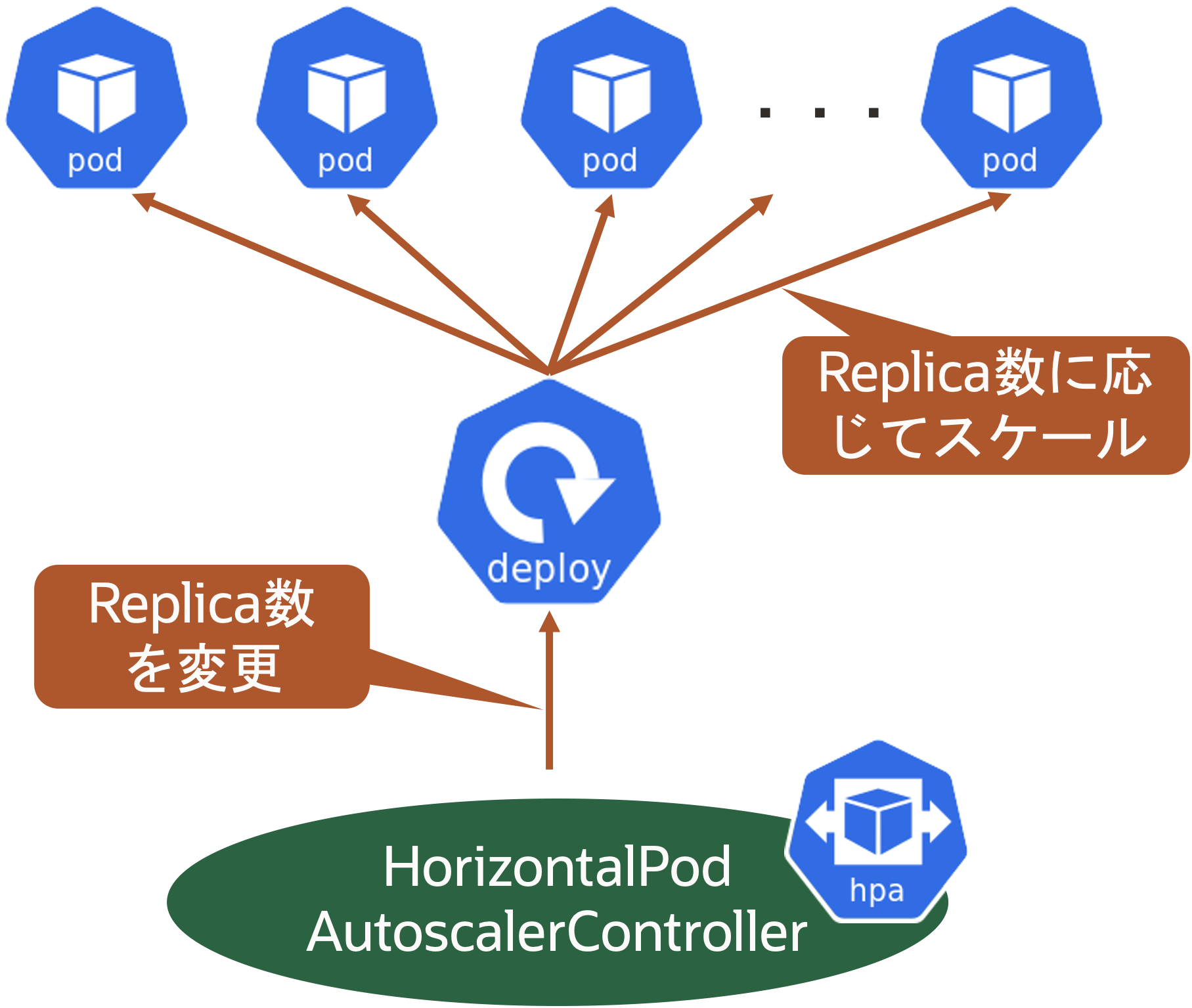
Podの水平スケール(HPA)は、コンテナアプリケーション環境(Pod)を水平スケール(スケールアウト/イン)させる仕組みです。厳密には、Deployment(ReplicaSet)のレプリカ数を変更することで水平スケールを実現します。
HPAを実現するためには、スケールの定義としてHorizontal Pod Autoscalerリソース(以下、HPAリソース)を作成する必要があります。このHPAリソースを管理するのがController Managerの1つであるHorizontalPodAutoscalerControllerです。
HorizontalPodAutoscalerControllerは、デフォルトで15秒間隔でメトリクスの値を取得しており、スケールの判断材料となるメトリクス値がHPAリソースに定義したターゲット値に近づくようにPodの数を調整します。
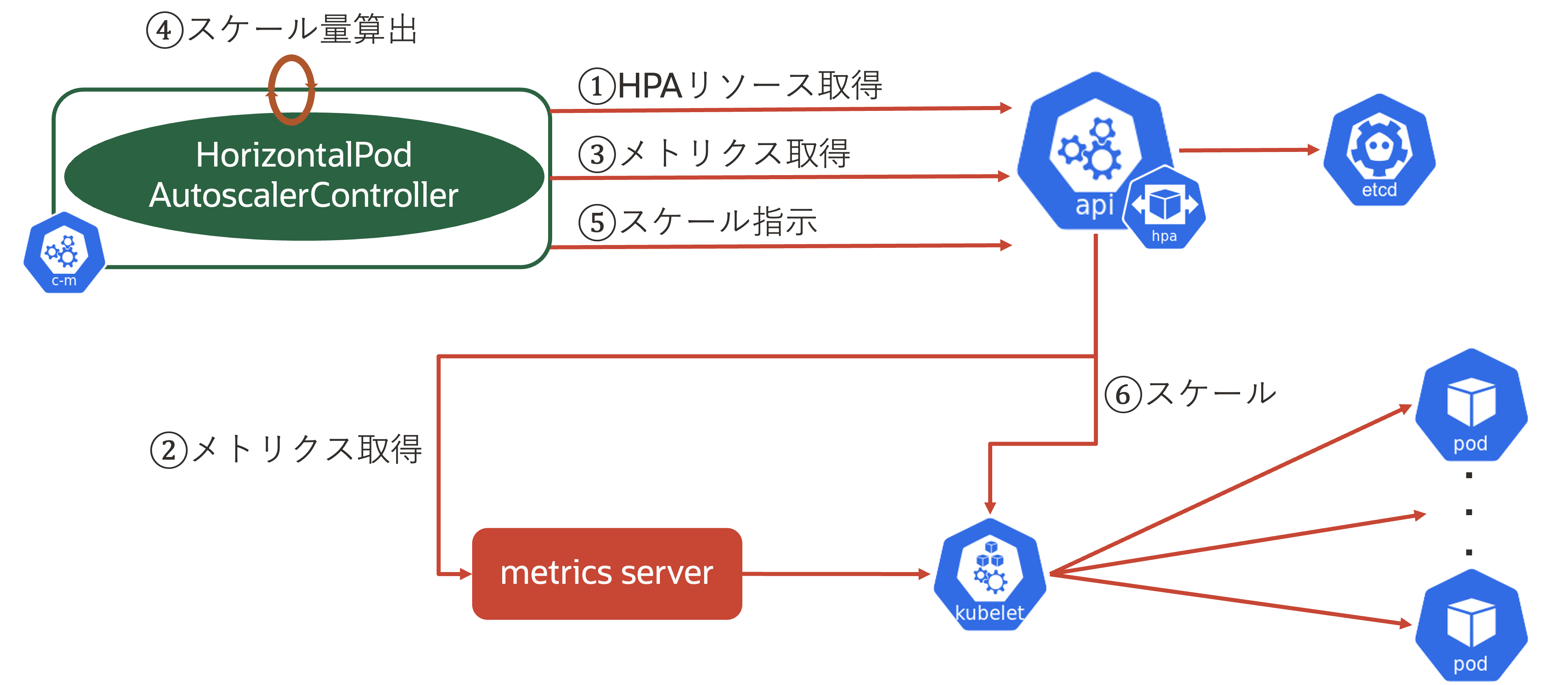
基本的には、Podの平均CPU/メモリ使用率を利用しますが、ユーザ独自のメトリクスも利用できます。続いて、HPAの仕組みを見ていきます。 まずは、HPAの流れを図で示します。この流れを順番に説明します。
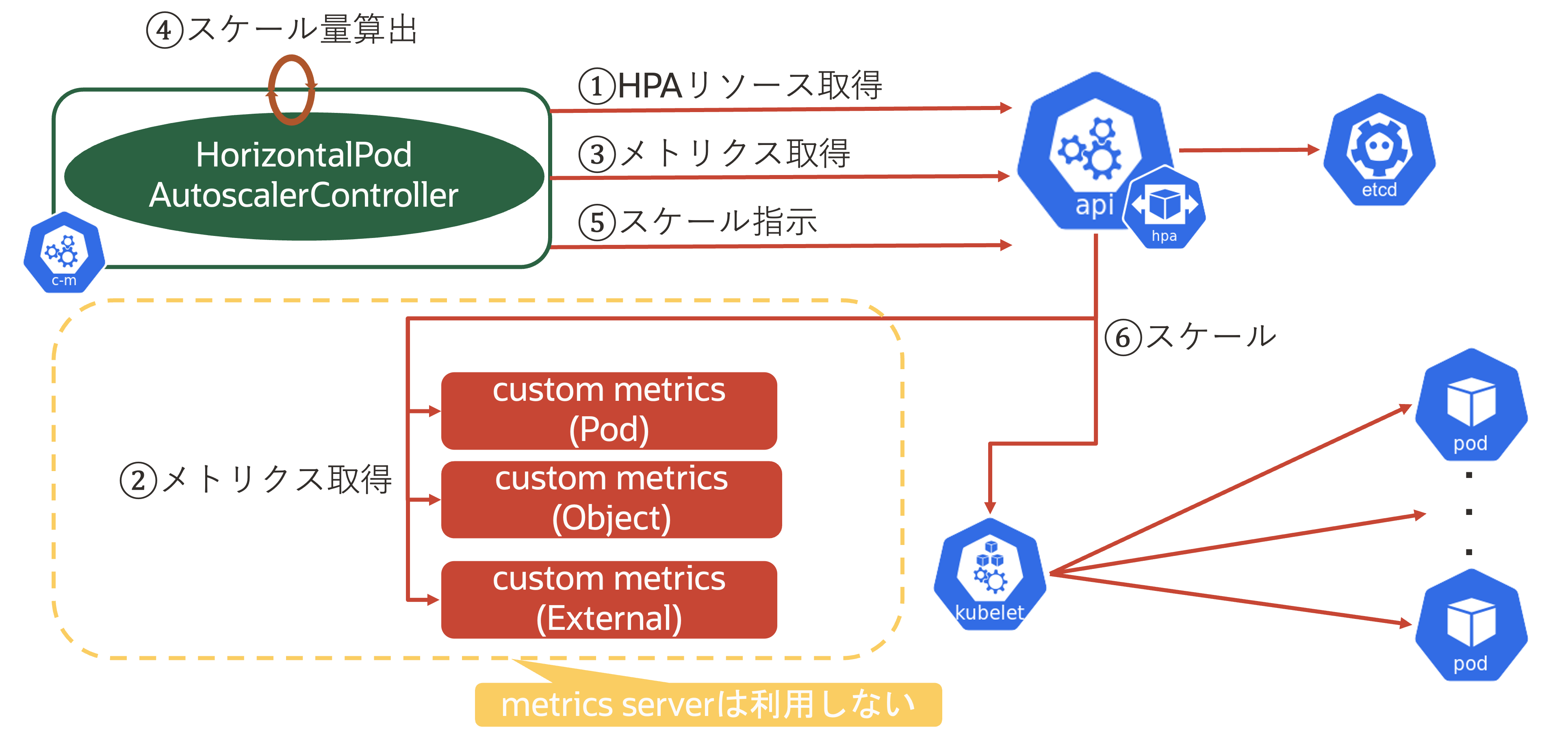
- HorizontalPodAutoscalerControllerがkube-apiserverからHPAリソースを取得
- kube-apiserverがmetrics server(後述)からkubelet経由でPodの現状のメトリクス情報を取得
- HorizontalPodAutoscalerControllerがkube-apiserverから(2)のメトリクスを取得
- HorizontalPodAutoscalerControllerがスケール量を算出
- HorizontalPodAutoscalerControllerがkube-apiserverに対してスケールを指示
- kube-apiserverがkubeletに対してスケール指示
kubectl topコマンドで取得できます。 metrics serverは本連載で紹介する3つのスケール手法(Podの水平/垂直スケール、Nodeの水平スケール)で利用する目的で想定されており、監視サーバへのメトリクスソースとしての利用は禁止されています。利用する場合はkubeletの/metrics/resourceエンドポイントから収集することが推奨されています。 スケール量の算出 HPAの解説に戻りましょう。先ほどHPAの動作イメージについて図示しましたが、その中でHorizontalPodAutoscalerControllerがスケール量を算出するという動作がありました。ここからは、HPAでどのようにスケール量が算出されるかを見ていきます。 HPAで算出されるスケール量は、以下のシンプルな式で構成されます。CPUをスケール時のメトリクスとした場合を例にします。必要なレプリカ数 = 現在のレプリカ数 * ( Podの平均CPU使用率 / ターゲットのCPU使用率 )つまり、Podが利用しているCPU使用率とユーザが定義したターゲットとするCPU使用率の比に現在のレプリカ数(Pod数)を掛けたものです。以下に具体例を示します。- Pod(現レプリカ数:5)の平均CPU使用率の合計が90%、ターゲットのCPU使用率が70%の場合
- 必要なレプリカ数 = 5 * (90(%) / 70(%)) = 6.42…
- 7個のレプリカが必要(2個のレプリカが追加)
- Pod(現レプリカ数:5)の平均CPU使用率の合計50%、ターゲットのCPU使用率が70%の場合
- 必要なレプリカ数 = 5 * (50(%) / 70(%)) = 3.57…
- 4個のレプリカが必要(1個のレプリカを削除)
- スケール量(レプリカ数)は整数で表現する必要があるため、小数点切り上げ
Podの平均CPU使用率は、各Podの過去1分間のCPU使用率
使用率という言葉が出てきました。では、どの値をCPUの100%とするのかについて説明します。 KubernetesのPodにはResource RequestsとResource Limitsという2つの設定値があります。この値はコンテナのリソースを制御する上で非常に重要な設定値です。それぞれについて以下に整理します。- Resource Requests
- Podをデプロイする際に必要とするリソース(メモリ/CPU)を指定できる仕組み
- Podがスケジューリングされる際にはResource Requestsに定義されたリソースを確保
- スケジューリング時にNodeにResource Requests分のリソースが空いているかをチェック
- Nodeにリソースに空きがない場合、Podの状態が
Pendingになる - PodはResource Requestsを超過してリソースを利用できる
- Podをデプロイする際に必要とするリソース(メモリ/CPU)を指定できる仕組み
- Resource Limits
- Podが最大で利用できるリソース(メモリ/CPU)を制限する仕組み
- 制限しない場合は無制限(Nodeの空きリソース分)にリソースを利用できる
- Resource Limitsを超過した場合は、それぞれ以下の挙動
- メモリ:OOM killもしくは再起動
- CPU:強制終了はされない。場合によってはCPUスロットリングが発生
- Nodeがもつキャパシティよりも大きな数値で指定することもできる
- Podが最大で利用できるリソース(メモリ/CPU)を制限する仕組み
0.2=200mMemory Mi もしくは Gi100Mi≒0.1Gi≒104MB、1Gi≒1024Mi≒1074MB次に、これらを利用したQoS(Quality of Service) Classという仕組みも補足します。QoS Classはスケジューリングやevict(削除)される際に、Podへのリソース割り当ての振る舞いを決定する仕組みです。Resource RequestsとResource Limitsを元に判断されます。 例えば、Nodeのリソース不足の場合に、どのPodをevictするかをQoS Classにより決定します。このClassはGuaranteed/BestEffort/BurstableからKubernetesが付与(.statusフィールドに存在)します。 QoS 割当条件 Guaranteed(優先度高) 全PodにCPU/メモリのResource RequestsとResource Limitsが指定済みかつ同一値の場合 BestEffort(優先度低) 全PodにCPU/メモリのResource RequestsとResource Limitsが未指定の場合 Burstable Guaranteed/BestEffortいずれも該当しない場合(Resource Requestsのみ指定、Resource RequestsとResource Limitsの値が異なるなど) ちなみに、QoS Classが同一の場合は、OutOfMemory (OOM) scoreをもとにevictするPodを決定します。 HPAリソースの定義 ここからは、HPAリソースの定義方法を説明します。HPAリソースに定義する内容は、主に以下の4つです。 項目 フィールド 内容 スケール対象 .spec.scaleTargetRef スケール対象リソースのapiVersion、kind、nameを指定。基本はapiVersion: apps/v1、kind: Deploymentを指定 スケール範囲 .spec.minReplicas
.spec.maxReplicas スケール時のPodのレプリカ数の最小値と最大値を指定 スケール条件となるメトリクス .spec.metrics スケール条件にするメトリクスを指定。CPU/メモリの他にカスタムメトリクスも指定できる スケール時の振る舞い .spec.behavior スケール時のリードタイムとレプリカ増減のポリシーを指定 実際のHPAリソース例は以下です*1。*1: セッション当時はHPAリソースをapiVersion: autoscaling/v2beta2として解説しましたが、この記事では最新のapiVersion: autoscaling/v2を用います。そのため、セッション資料とは異なるフィールドや値が存在します apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50 behavior: scaleUp: stabilizationWindowSeconds: 60 policies: - type: Percent value: 100 periodSeconds: 15 scaleDown: stabilizationWindowSeconds: 300 policies: - type: Percent value: 10 periodSeconds: 60 - type: Pods value: 4 periodSeconds: 60 selectPolicy: Max この定義を先ほどの表に当てはめると以下になります。 項目 フィールド 定義 スケール対象 .spec.scaleTargetRefphp-apacheという名前のDeploymentが対象 スケール範囲 .spec.minReplicas
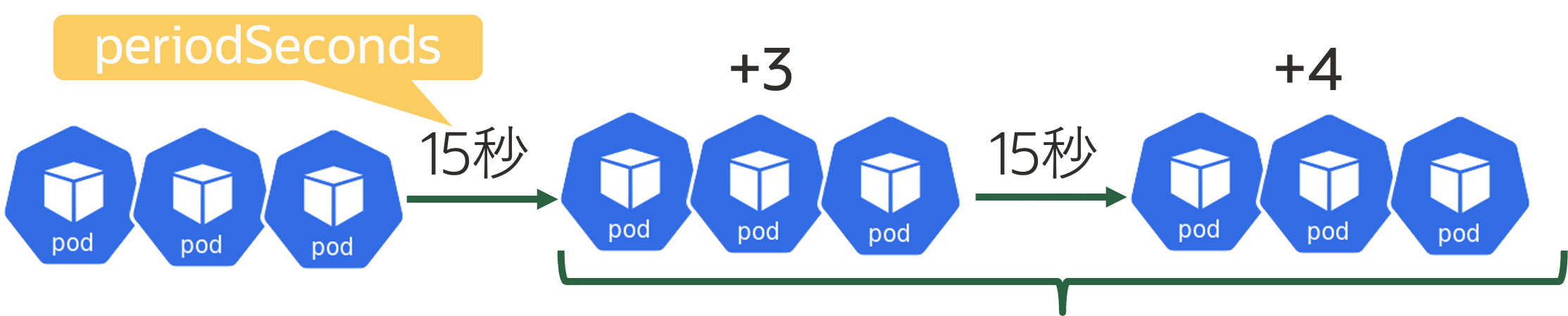
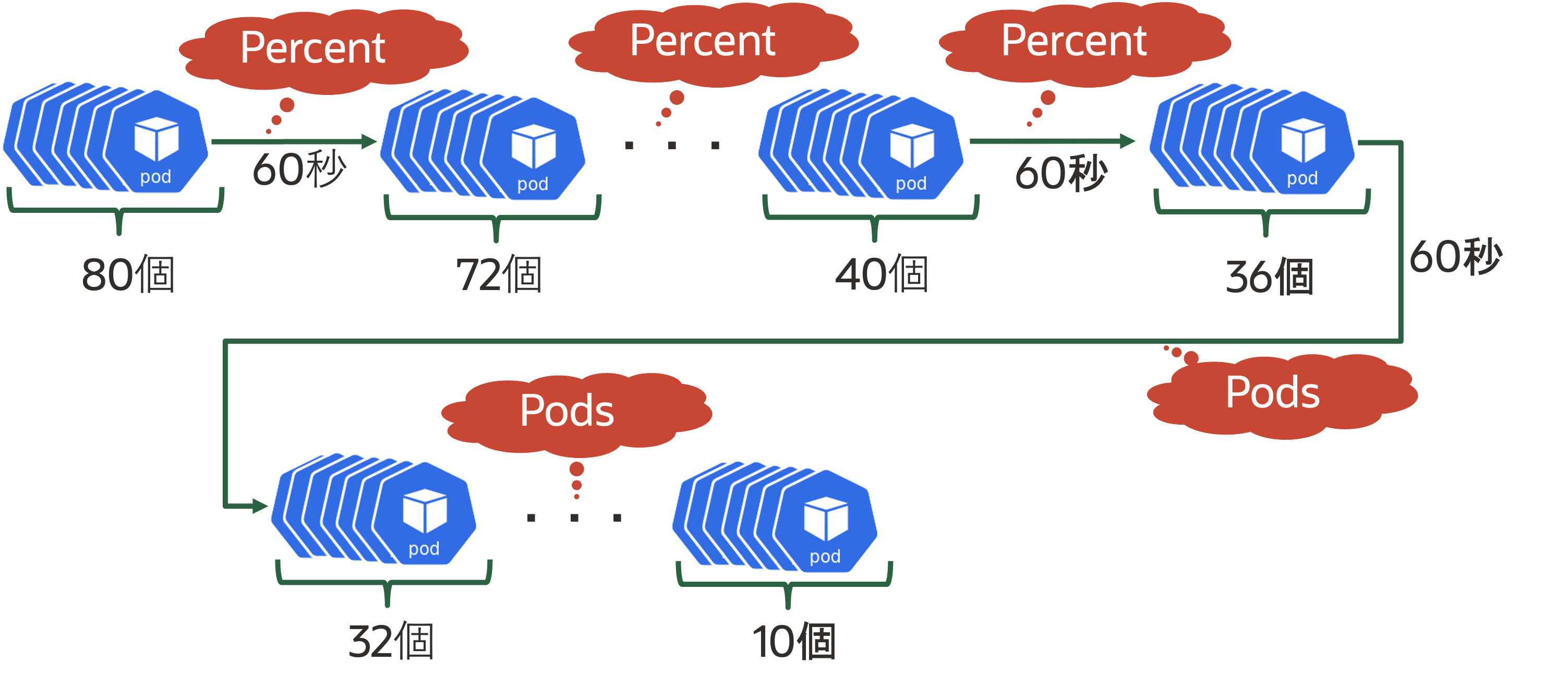
.spec.maxReplicas 最小レプリカ数が1、最大レプリカ数が10 スケール条件となるメトリクス .spec.metrics Podの平均CPU利用率が50%となるようにレプリカ数を調整 スケール時の振る舞い .spec.behavior 後述 スケール時の振る舞いについて補足します。上記の例では、以下の定義になります。 behavior: scaleUp: stabilizationWindowSeconds: 60 policies: - type: Percent value: 100 periodSeconds: 15 scaleDown: stabilizationWindowSeconds: 300 policies: - type: Percent value: 10 periodSeconds: 60 - type: Pods value: 4 periodSeconds: 60 selectPolicy: Max まずは、スケールアウト時の挙動を説明します。 scaleUp: stabilizationWindowSeconds: 60 policies: - type: Percent value: 100 periodSeconds: 15stabilizationWindowSecondsは、スケール条件を満たしてからスケールを行うまでのリードタイムです。そのため、今回はスケール開始まで60秒のリードタイムがあります。 次に、実際のスケール時の振る舞いです。今回の例ではスケール開始から15秒毎に判定が実施され、既存のレプリカ数を100%としてスケールアウト(ただし、最大レプリカ数を超過しない)します。例えば、現状のレプリカ数が3つの場合は、下図のイメージです。次に、スケールイン時の挙動です。 scaleDown: stabilizationWindowSeconds: 300 policies: - type: Percent value: 10 periodSeconds: 60 - type: Pods value: 4 periodSeconds: 60 selectPolicy: MaxstabilizationWindowSecondsは5分(300秒)です。 実際のスケール時の振る舞いですが、2通りのポリシーが定義されています。複数のポリシーが定義されている場合はselectPolicyによってどちらが選択されるかが決定します。今回の場合はMaxなので、削除するレプリカ数が多い方が選択されます。 ポリシーの1つ目は60秒おきに判定され、既存レプリカ数の10%分の数が削除されます。ポリシーの2つ目は60秒おきに判定され、既存レプリカ数から4つが削除されます。 例えば、今のレプリカ数が80個あり、必要なレプリカ数が10個の場合は下図のようにスケールインします。図に示すように、レプリカ数が40個まではPercentポリシー(既存レプリカ数の10%)が選択され、36個以下の場合はPodsポリシー(レプリカ数4個)が選択されます。PodやContainerのCPUやメモリ利用率以外でのスケール ここまでの例では、PodのCPUやメモリの利用状況でのスケールでしたが、他にも4つのメトリクスを利用できます*2。 種別 メトリクス 収集元 スケールロジック Resource CPU利用率
メモリ利用率 metrics-serverがkubeletから取得した値 PodのCPU/メモリ利用率で評価 ContainerResource CPU利用率
メモリ利用率 metrics-serverがkubeletから取得した値 ContainerのCPU/メモリ利用率で評価 Pods Podの任意のメトリクス API Aggregation Layerから取得した任意のエンドポイント 値での評価(≠率) Object 任意のメトリクス(Pod/Container以外のKubernetesオブジェクト) API Aggregation Layerから取得した任意のエンドポイント 単一の値と目標値の比較 External 任意のメトリクス(Kubernetesオブジェクト以外) API Aggregation Layerから取得した任意のエンドポイント 単一の値と目標値の比較 ここで登場したAPI Aggregation Layerについて補足します。API Aggregation Layerとは、広く利用されているOperatorを利用したCRD(カスタムリソース)での拡張とは異なる手法でkube-apiserverに新しい種類のオブジェクトを認識させる仕組みです。kube-apiserverのフラグでAggregation Layerを有効に設定する必要があり、拡張APIサーバとなるPodを実行し、APIServiceオブジェクトを登録することで利用できます。 CRD(カスタムリソース)よりも詳細なAPIを定義でき、apiserver-builder(OperatorでのKubebuilder相当)を利用して実装できます。 PodもしくはContainerのCPU/メモリ利用率以外をスケール時のメトリクスとして利用する場合はmetrics serverを利用しないため、下図のような処理フローになります。PodやContainerのCPUやメモリ利用率以外でのスケールでのHPAリソース定義例を示します。*2: セッション当時はHPAリソースをapiVersion: autoscaling/v2beta2として解説しましたが、この記事では最新のapiVersion: autoscaling/v2を用います。そのため、セッション資料とは異なるフィールドや値が存在します・type:Podsの場合apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Pods pods: metric: name: packets-per-second target: type: AverageValue averageValue: 1k.spec.metrics.metrics[].typeにPodsを指定すると、任意のPodメトリクスをスケール条件に利用できます。例えば、上記のケースではpackets-per-secondというメトリクスの平均値が1000になるようにレプリカ数が調整されます。任意のPodのメトリクスを利用する場合は平均値(≠率)での判定になります。・type:Objectの場合apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1 kind: Ingress name: main-route target: type: Value value: 2k.spec.metrics.metrics[].typeにObjectを指定すると、同一Namespace内のPod以外の任意のメトリクスをスケール条件に利用できます。例えば、上記のケースではmain-routeという名前のIngressリソースにおけるrequests-per-secondというメトリクスの値が2000になるようにレプリカ数が調整されます。Pod以外の任意のメトリクスを利用する場合は値か平均値(≠率)での判定になります。・type:Externalの場合apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: External external: metric: name: kafka_consumergroup_sum target: type: AverageValue averageValue: 30.spec.metrics.metrics[].typeにExternalを指定すると、Kubernetesクラスタ外の任意のメトリクスをスケール条件に利用できます。例えば、上記のケースではkafka_consumergroup_sumというメトリクスの平均値が30になるようにレプリカ数を調整します。Kubernetesクラスタ外の任意のメトリクスを利用する場合は実値か平均値(≠率)での判定になります。・複数のスケール条件
ここまでは、単一のスケール条件で説明をしてきましたが、HPAでは複数のスケール条件を定義できます。 apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50 - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1 kind: Ingress name: main-route target: type: Value value: 2k - type: Pods pods: metric: name: packets-per-second target: type: AverageValue averageValue: 1k 例えば、上記のケースでは、以下すべての条件下でのレプリカ数を算出し、最もレプリカ数が大きい結果が適用されます。各PodのCPU使用率50%になるレプリカ数main-routeという名前のIngressリソースにおけるrequests-per-secondというメトリクスの値が2000になるレプリカ数packets-per-secondというPodメトリクスの平均値が1000になるレプリカ数
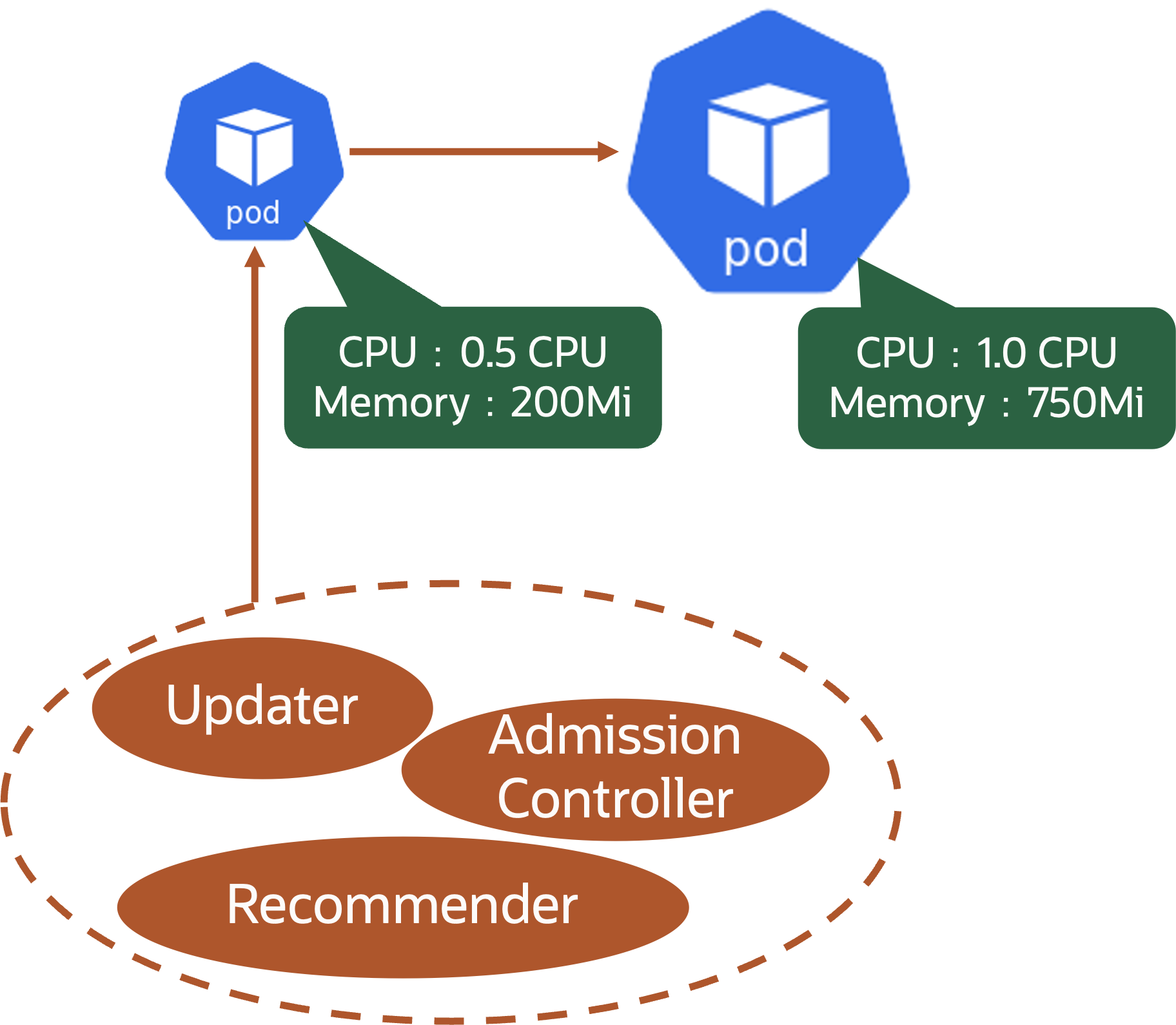
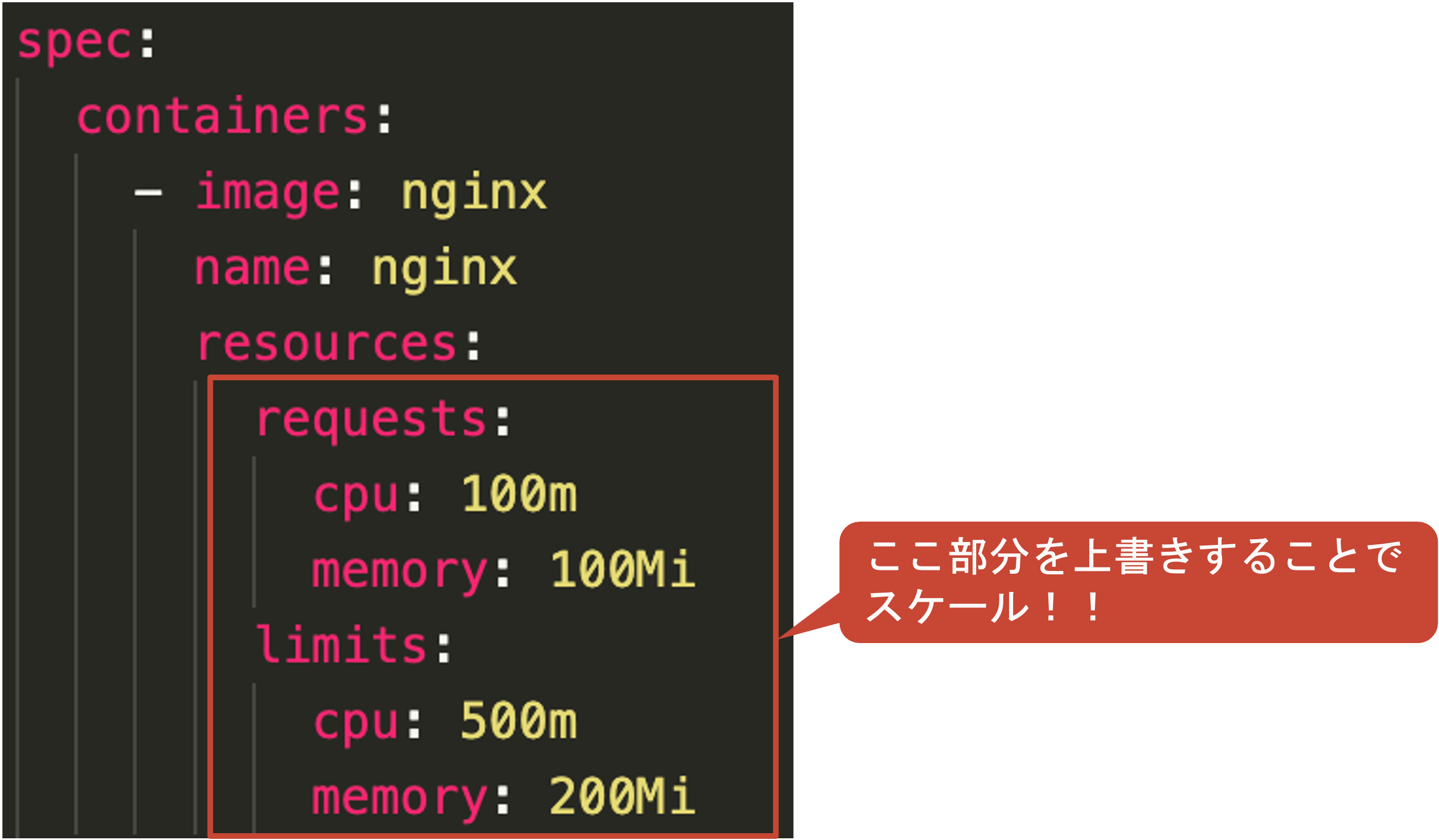
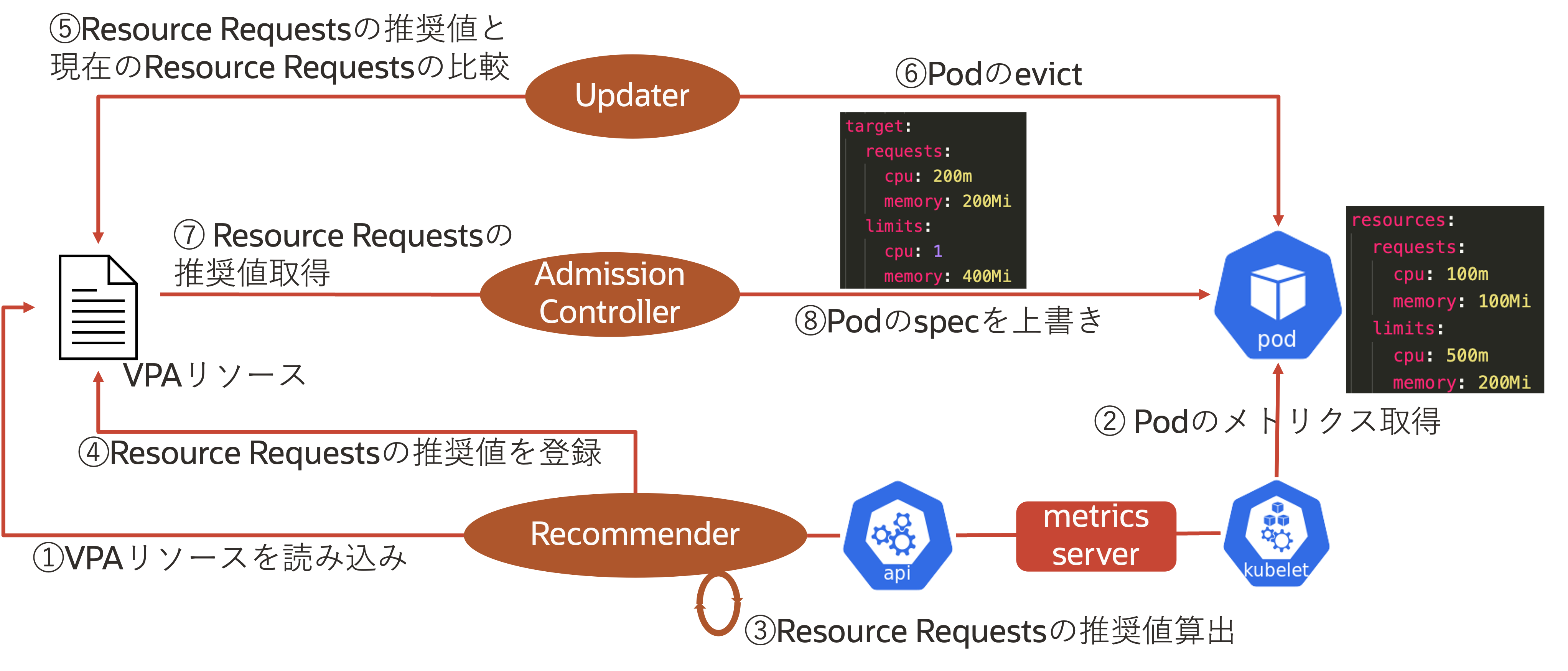
.spec.containers[].resources.requests(起動時に割り当てるCPU/メモリ)の推奨値を算出し、以下のイメージのように.spec.containers[].resources.requests/limitsを上書きすることで実現します。このとき、Resource Limitsの値はResource RequestsとLimitsの初期値の比率によって決定され、同様に上書きされます。 例えば、Resource Requestsに定義したCPUが0.1 core、Resource Limitsに定義したCPUが0.5 coreの時、VPAが算出したResource Requestsの推奨値が0.2 coreだった場合、Resource Requestsは0.2 core、Resource Limitsは1 coreに上書きされます(Resource Requests:Resource Limits=1:5)。VPAを実現するコンポーネントには、Recommender、Updater、Admission Controllerの3つがあります。この3つのコンポーネントは、それぞれ以下の役割で動きます。 コンポーネント 役割 Recommender (1)VPAリソースを読み込み
(2)Podのメトリクス取得
(3)Resource Requestsの推奨値算出
(4)Resource Requestsの推奨値を登録 Updater (5)RecommenderがVPAリソースに書き込んだ推奨値と動作中のPodのResource Requestsの値を比較
(6)Podのevict(再起動) Admission Controller (7)Resource Requestsの推奨値取得
⑧Podのspecを上書き これらを図にすると、下図のようなイメージです。VPAリソースの定義 VPAリソースの定義方法を説明します。VPAリソースに定義する内容は主に以下の3つです。 項目 フィールド 定義 スケール対象 .spec.targetRef スケール対象リソースのapiVersion、kind、nameを指定。基本はapiVersion: apps/v1、kind: Deploymentを指定 リソースポリシー .spec.resourcePolicy 対象Deployment(Pod)内のコンテナ名、スケール範囲、スケール対象のリソース(CPU/メモリ)を指定 アップデートポリシー .spec.updatePolicy Auto、Recreate、Initial、Offのいずれかを指定。それぞれの詳細は後述 上記のアップデートポリシーには、以下の4種類がありします。アップデートポリシーはスケールする際の挙動を示します。 項目 意味 Auto 現状はRecreateと同様 Recreate 再起動によってPodをスケールアップ Initial 作成時のみにPodのリソースを割り当て(再起動はしない) Off スケール値の算出のみで、実際にはスケールしない 実際のVPAリソース例は以下です。 apiVersion: autoscaling.k8s.io/v1 kind: VerticalPodAutoscaler metadata: name: php-apache spec: targetRef: apiVersion: "apps/v1" kind: Deployment name: php-apache resourcePolicy: containerPolicies: - containerName: '*' minAllowed: cpu: 100m memory: 50Mi maxAllowed: cpu: 1 memory: 500Mi controlledResources: ["cpu", "memory"] updatePolicy: updateMode: Auto Podリソースのin-place Resize Kubernetes v1.27からPodリソースのin-place Resize(再起動なしでのスケールアップ)がα機能として実装されています。この機能をVPAと連携させることで、evict(再起動)なしでのPodのスケールアップを実現できます。ただし、VPAではまだPodリソースのin-place Resizeを利用したin-place updateは実装されていません。詳細はAEP-4016で管理されています。 Podリソースのin-place Resizeを利用するにはInPlacePodVerticalScalingのFeatureGatesを有効化する必要があるため、クラウドベンダーなどが提供するマネージドなKubernetesサービスでは利用できない可能性があります。 以下に一例を示します。 apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - name: nginx image: nginx resizePolicy: - resourceName: cpu restartPolicy: NotRequired - resourceName: memory restartPolicy: RestartContainer resources: limits: memory: "100Mi" cpu: "100m" requests: memory: "100Mi" cpu: "100m".spec.containers[].resizePolicyにCPUとメモリに対するスケールアップ時の挙動を定義します。上記のケースではCPUのスケール時は再起動なし(restartPolicy: NotRequired)でのスケールアップが実施され、メモリのスケール時には再起動が実施されます(restartPolicy: RestartContainer)。 また、再起動なしでのスケールアップの場合には、現状時間を要することも確認されており、今後修正予定です(Pod Resize - long delay in updating)。 HPAとVPAの併用 HPAとVPAの併用について説明します。HPAとVPAの併用は、それぞれがCPUとメモリを利用する場合は禁止されています(参考)。 CPUとメモリを利用したHPA/VPAでは、スケール対象がそれぞれDeploymentとPodで異なるため、VPAによりスケールされたPodにHPAでのスケールを適用するとPod毎のResource Requestsが煩雑になり、想定通りのスケール挙動にならない可能性があります。例えば、HPAが実施された結果Pod毎のスペックが異なり、オーバースケールだったり、スケール不足になることがあります。 HPAとVPAを併用する場合は、HPAとVPAのスケールメトリクスを分離する(HPAはCPUを利用する、VPAはメモリを利用するなど)か、PodsのCPU/メモリ以外のメトリクスを利用しましょう。 VPAのデモ 当日のセッションでは、VPAのデモを実施しています。詳細はセッション動画をご確認ください。 HPAとVPAのまとめ ここまでで、HPAとVPAについて整理します。- HPA(Podの数が増減するスケール方式)
- Podが使用しているリソースとResource Requestsをもとに水平スケール、スケール対象はDeployment
- スケールの範囲や振る舞いをユーザ側で定義する必要性
- アプリケーション(Pod)にかかる負荷の傾向を把握
- コスト(経済/リソース)を考慮しながらスケール範囲の見極め
- アプリケーションの特性や運用、サービス指標(SLA/SLOも含む)などを考慮し、スケールの振る舞いを定義
- Podが使用しているリソースとResource Requestsをもとに水平スケール、スケール対象はDeployment
- VPA(Podのスペック(
.spec.containers[].resources.requests/limits)を拡張するスケール方式)- Podが使用しているリソース(CPU/メモリ)をもとに垂直スケール
- 実際のリソース使用量を把握できていなくても、よしなにスケール(実績値との乖離を防止)
- 実際にスケールさせなくても、算出された推奨値を確認するだけという利用方法もある
- クラスタ全体のリソースを有効活用できる
- 現時点では、原則としてはPodの再起動が必要(in-place updateは未実装)
- Podが使用しているリソース(CPU/メモリ)をもとに垂直スケール
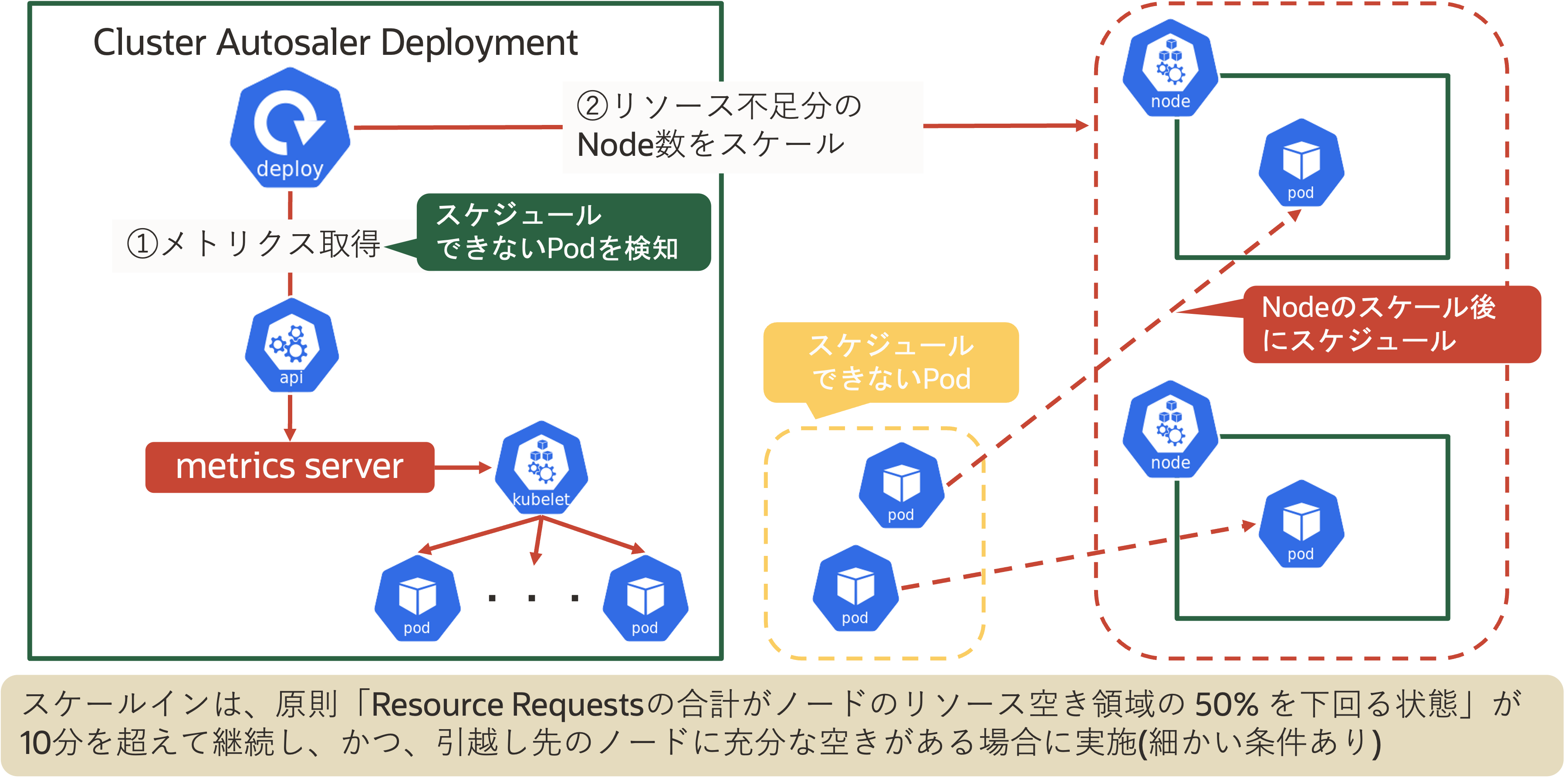
kubectl drain node→evict)が発生し、サービスにダウンタイムが発生する可能性があります。 これを防ぐためには、PodDisruptionBudget(PDB、後述)を設定することで、なるべくGraceful shutdownが実施されるように設定を実施することが重要です。 また、以下の場合(一部)は、Nodeが削除されないこともあります。- kube-system namespaceで実行されているシステムコンポーネント関連のPod
- PodDisruptionBudget(PDB)により制限されているPod
- Controllerにより管理されていないPod(Deployment/ReplicaSet/Job/StatefulSetでないPod)
- NodeAffinity/NodeSelectorによりスケジュールされているPod
- .metadata.annotationsに
"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"が設定されているPod
PodDisruptionBudget(PDB)は、自発的な中断(Cluster Autoscalerによるスケールイン時やkubectl drain実行時)が発生した場合に同時にダウン(再スケジューリング)するレプリカを制限する仕組みです。このリソースを定義することで最低限稼働しておくべきPod数を確保でき、サービスのダウンタイムを防止できます。 PodDisruptionBudget(PDB)では、主に以下の2つを定義します。 項目 内容 最低限稼働しておくべきレプリカ数 minAvailable/maxUnavailableで定義 Selector 対象PodをSelectorで指定 PodDisruptionBudget(PDB)の例は以下の通りです。 apiVersion: policy/v1 kind: PodDisruptionBudget metadata: name: myapp spec: # 最大で無効状態な Pod は 1 に設定。これを超えてevictできない maxUnavailable: 1 # 対象 Pod のセレクタ selector: matchLabels: run: myapp・PriorityClass
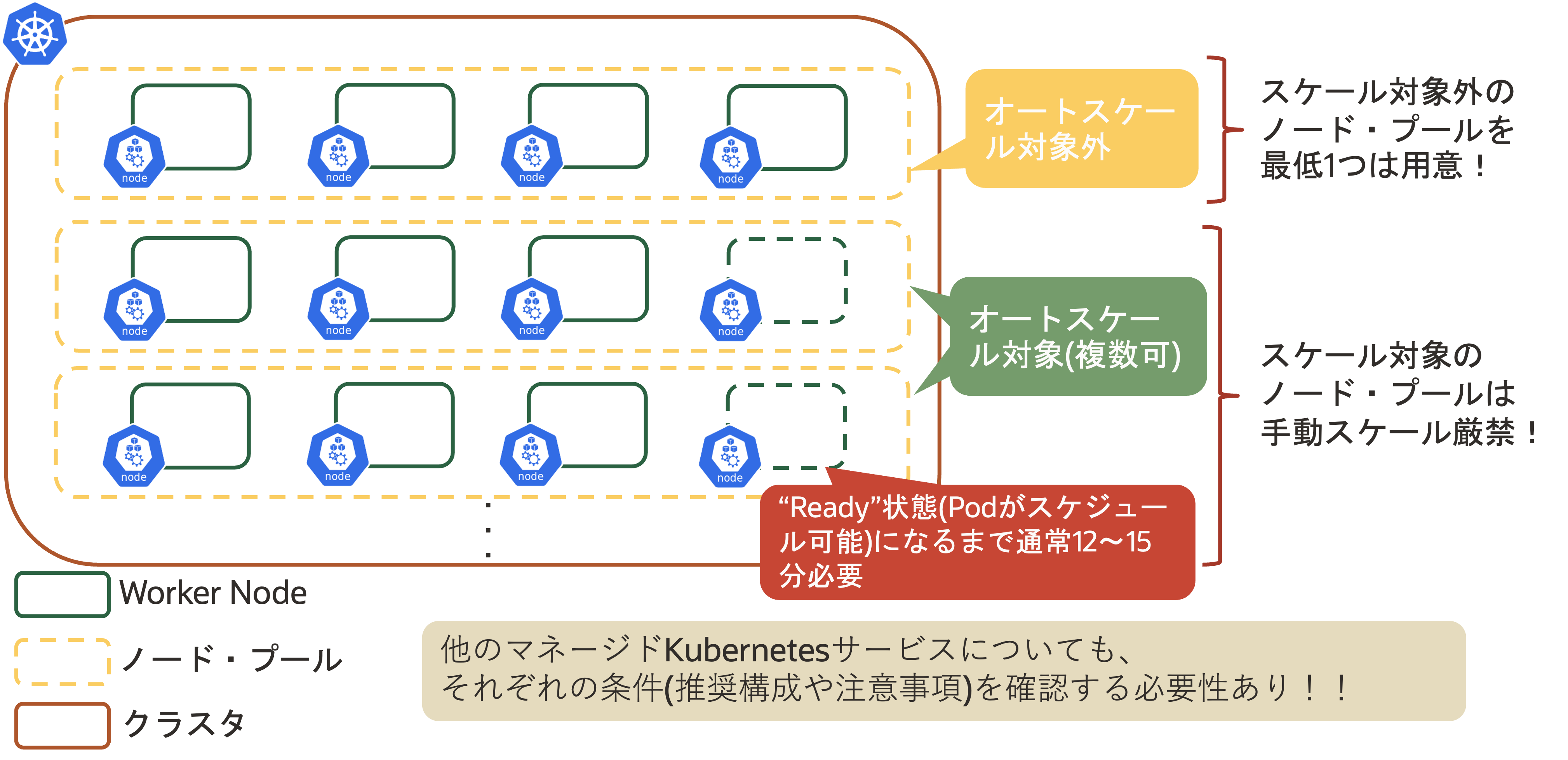
PriorityClassは、スケジュール時にリソースを確保できない場合(通常であればPending状態)に優先的に起動できるようにする仕組みです。このリソースをCAで活用して意図的に「優先度低の待機用Pod」でノードを多めに起動しておくことで、Podのスケールアウト(HPA)時のNodeリソース不足を防止できます。 PriorityClassでは、主に以下の2つを定義します。 項目 内容 優先度 10億以下の整数。値が大きいほど優先度高 グローバル適用要否 priorityClassNameが付与されていないPodへの適用要否。trueの場合はクラスタに一つだけ適用可能 PriorityClassの例は以下の通りです。 apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: high-priority value: 1000000 globalDefault: false --- apiVersion: apps/v1 kind: Deployment metadata: name: nginx labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: nginx name: nginx resources: memory: "500Mi" ports: containerPort: 80 priorityClassName: high-priority #PriorityClassの適用 CA利用時の留意事項(OKEの場合) OKEについても、いくつかの留意事項が存在します。OKEではスケール対象外のNodePoolを最低1つは用意することが推奨され、スケール対象に設定したNodePoolの手動スケールは厳禁です。このように、マネージドKubernetesサービスでCAを利用する場合は、それぞれの条件(推奨構成や留意事項など)を確認することが重要です。Kubernetesの各スケール手法まとめ これまで見てきたスケール手法を以下に整理します。 HPA VPA CA スケール対象 Deployment(ReplicaSet) Pod Node(Worker Node) スケール手法 水平スケール 垂直スケール 水平スケール 追加コンポーネント metrics server metrics server
Updater
Admission Controller
Recommender metrics server
Cluster Autoscaler Deployment スケールメトリクス Podや任意のリソース Resource Requests Resource Requests スケール時の即応性 高(スケールの振る舞いはカスタマイズ可能) 低 低 スケールイン時のダウンタイム なし あり(in-placeは未実装) あり(PDB等より一部制御可能) Kubernetesでの各種スケールのユースケース 最後に、これまでご紹介してきた各種スケール手法を組み合わせた1つのユースケース例を紹介します。- VPAを利用したResource Requestsの決定
- Resource Requestsの最適値を確認
- Resource Limitはアプリケーションの特性やNodeのリソースに応じて定義
- アプリケーションの特性やサービス指標に応じて、Podの水平スケール(HPA)範囲を決定
- 2.で定義したPodの水平スケールにおいて、Nodeのリソース不足に備えてCluster Autoscalerを定義
- 定常時のNode数を考慮しつつ、2.で定義したスケール範囲で不足すると想定されるリソース分のNode数を判断
- PodDisruptionBudget(PDB)やPriorityClassを利用しながら、Nodeのスケールインによる意図しないサービスダウンの防止、スケールアウト時のNodeプロビジョニングによるリードタイムの短縮を計画
- Podの垂直スケール
- Nodeの水平スケール
- Kubernetesでの各種スケールのユースケース
- おわりに
はじめに
「Oracle Cloud Hangout Cafe」(通称「おちゃかふぇ」/以降、OCHaCafe)は、日本オラクルが主催するコミュニティの1つです。定期的に、開発者・エンジニアに向けたクラウドネイティブな時代に身につけておくべきテクノロジーを深堀する勉強会を開催しています。
連載第6回の今回は、Kubernetesの最も重要な機能の1つである「オートスケーリング」について深掘りしていきます。
アジェンダ
- スケールの復習とKubernetesにおけるスケールの種類
- Podの水平スケール
- Podの垂直スケール
- Nodeの水平スケール
- Kubernetesでの各種スケールのユースケース
発表資料と動画については、下記のリンクを参照してください。
【資料リンク】
【動画リンク】
スケールの復習とKubernetesにおけるスケールの種類
初めに、従来からあるスケールの種類とその特徴を踏まえた上で、Kubernetesにおけるスケールの種類を説明します。
スケールの復習
一般的なスケールの手法としては、以下の通り大きく2種類あります。
- 水平スケール(スケールアウト)
- アプリケーションやソフトウェアが稼働する環境の数を増やすことによって、システムの処理能力を向上させる手法
- 処理を並列稼働させることによってスケールする
- 縮小させる場合は「スケールイン」と呼ぶ

水平スケール
- 垂直スケール(スケールアップ)
- アプリケーションやソフトウェアが稼働する環境のリソース(CPU, メモリ...)やスペックを向上させることによってシステムの処理能力を向上させる手法
- 捌ける処理量を増やすことによってスケールする
- 縮小させる場合は「スケールダウン」と呼ぶ
垂直スケール


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
この2種類のスケール手法のメリット/デメリットと、ユースケースを以下に整理します。
- 水平スケール(スケールアウト)
- Pos(メリット)
- システムの可用性が高まる
- Cons(デメリット)
- 密結合なリソースに注意が必要
- メンテナンスが煩雑になる可能性
- ユースケース
- Webアプリケーション(Web/APサーバ)
- 科学技術計算サーバ(HPCなど)
- Pos(メリット)
- 垂直スケール(スケールアップ)
- Pos(メリット)
- システム構成に変更がない
- 分散化に不向きなシステムでも対応できる
- Cons(デメリット)
- サーバが故障した場合のリスクが大きい
- ハードウェア拡張の限界がある
- ユースケース
- データベースサーバ
- ストレージサーバ
- Pos(メリット)
これら2種類のスケール手法は、いずれかを選択するというよりかは、システム全体で適材適所で組み合わせて利用するのが最適です。
例えば、Webアプリケーションなどの一般的なワークロードの場合は水平スケール(スケールアウト)を選択し、データベースなどの密結合なリソースの場合は垂直スケール(スケールアップ)を選択するなどです。

適材適所の垂直スケールを選択
kubernetesのスケール
ここからは、Kubernetesのスケールについて説明します。Kubernetesにおけるスケール手法には大きく3種類あります。以下にそれぞれ整理します。
- Podの水平スケール(Horizontal Pod Autoscaler)
- Podの数を増やすことによって、処理能力を向上させるスケール手法
- CPUやメモリをはじめとして、ユーザ独自のメトリクスも判断材料に利用できる(後述)
- Podの数を増やすことによって、処理能力を向上させるスケール手法
- Podの垂直スケール(Vertical Pod Autoscaler)
- Podが利用できるリソース(CPU, メモリ...)を増強することによって、処理能力を向上させるスケール手法
- 主にCPUやメモリを判断材料に利用
- Podが利用できるリソース(CPU, メモリ...)を増強することによって、処理能力を向上させるスケール手法
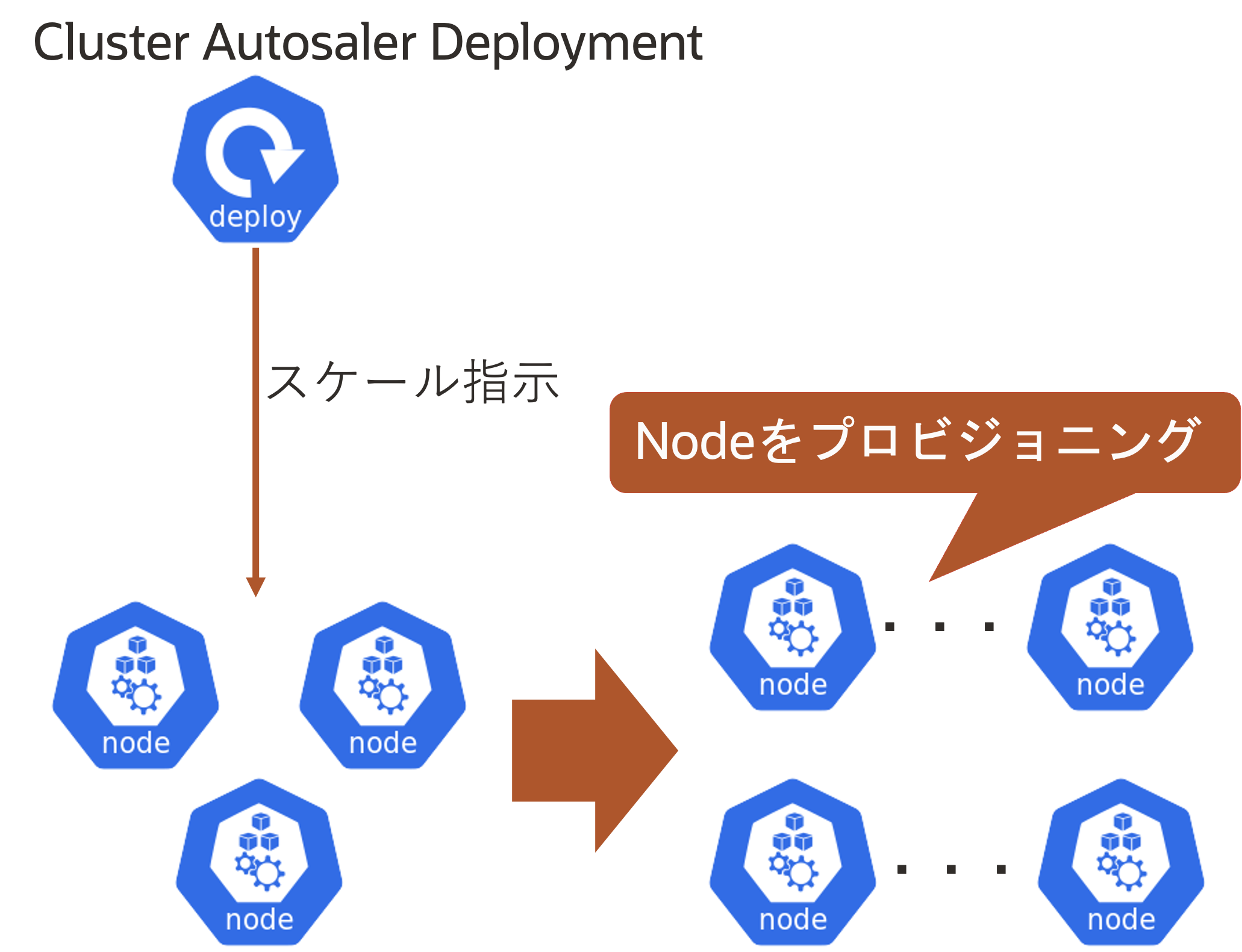
- Nodeの水平スケール(Cluster Autoscaler)
- Worker Nodeの台数を増やす(デプロイできるPod数を増やす)ことによって、処理能力を向上させるスケール手法
- Podの水平スケール(Horizontal Pod Autoscaler)と組み合わせて利用することが多い
- Worker Nodeの台数を増やす(デプロイできるPod数を増やす)ことによって、処理能力を向上させるスケール手法
ここで、"Nodeの垂直スケール"がないと思われた方も多いでしょう。Nodeの垂直スケールはKubernetesとしては実装されていません。また、2024/5時点ではクラウドベンダーなどが提供するAPIなどを利用してNode(Compute)のリソース増強はできますが、リソースをオンラインで変更する仕組みはありません。仮にオフラインで実行するにしても、Node(Compute)のリソース変更後に再起動が必要となるため、現実的ではありません。
このような事情もあるせいか、Kubernetesとしても各ベンダーが提供するマネージドKubernetesサービスとしても、Nodeの垂直スケールは実装されていません。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Oracle Cloud Hangout Cafe Season5 #1「Kubernetes Operator 超入門」(2022年1月19日開催)
2023年3月17日 6:30
Oracle Cloud Hangout Cafe Season 4 #2「Kubernetesのネットワーク」(2021年5月12日開催)
2024年2月20日 6:30
Oracle Cloud Hangout Cafe Season6 #1「Service Mesh がっつり入門!」(2022年9月7日開催)
2023年6月22日 6:30
Oracle Cloud Hangout Cafe Season 4 #5「Kubernetesのオートスケーリング」(2021年8月4日開催)
2024年5月29日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
