Podの水平スケール
Podの水平スケール
以降では、上記で整理した3つのスケール手法について深掘りしていきます。まずは、Podの水平スケール(Horizontal Pod Autoscaler、以下HPA)から見ていきます。
Podの水平スケールの概要
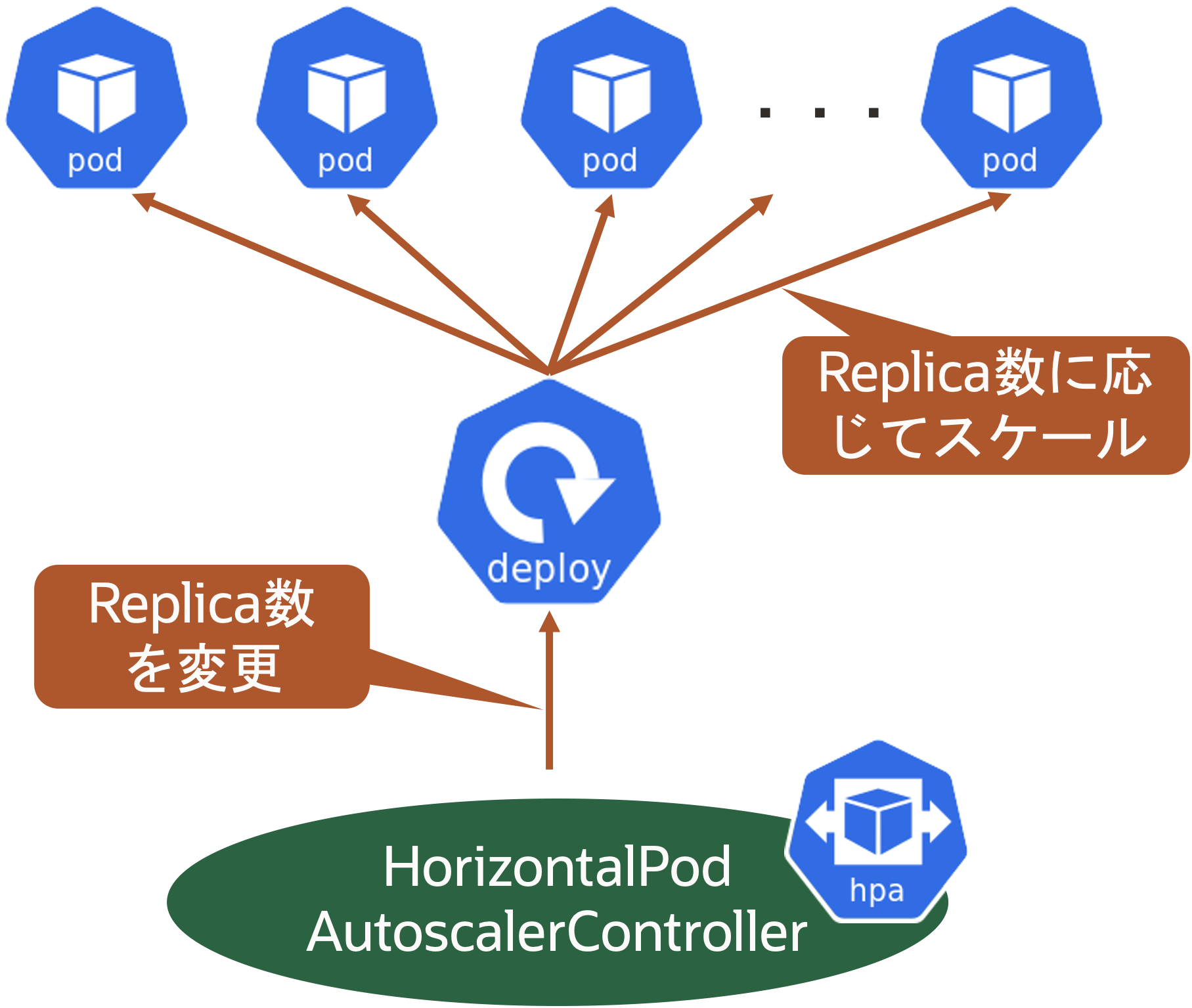
Podの水平スケール(HPA)は、コンテナアプリケーション環境(Pod)を水平スケール(スケールアウト/イン)させる仕組みです。厳密には、Deployment(ReplicaSet)のレプリカ数を変更することで水平スケールを実現します。
HPAを実現するためには、スケールの定義としてHorizontal Pod Autoscalerリソース(以下、HPAリソース)を作成する必要があります。このHPAリソースを管理するのがController Managerの1つであるHorizontalPodAutoscalerControllerです。
HorizontalPodAutoscalerControllerは、デフォルトで15秒間隔でメトリクスの値を取得しており、スケールの判断材料となるメトリクス値がHPAリソースに定義したターゲット値に近づくようにPodの数を調整します。
基本的には、Podの平均CPU/メモリ使用率を利用しますが、ユーザ独自のメトリクスも利用できます。
Podの水平スケール
続いて、HPAの仕組みを見ていきます。 まずは、HPAの流れを図で示します。
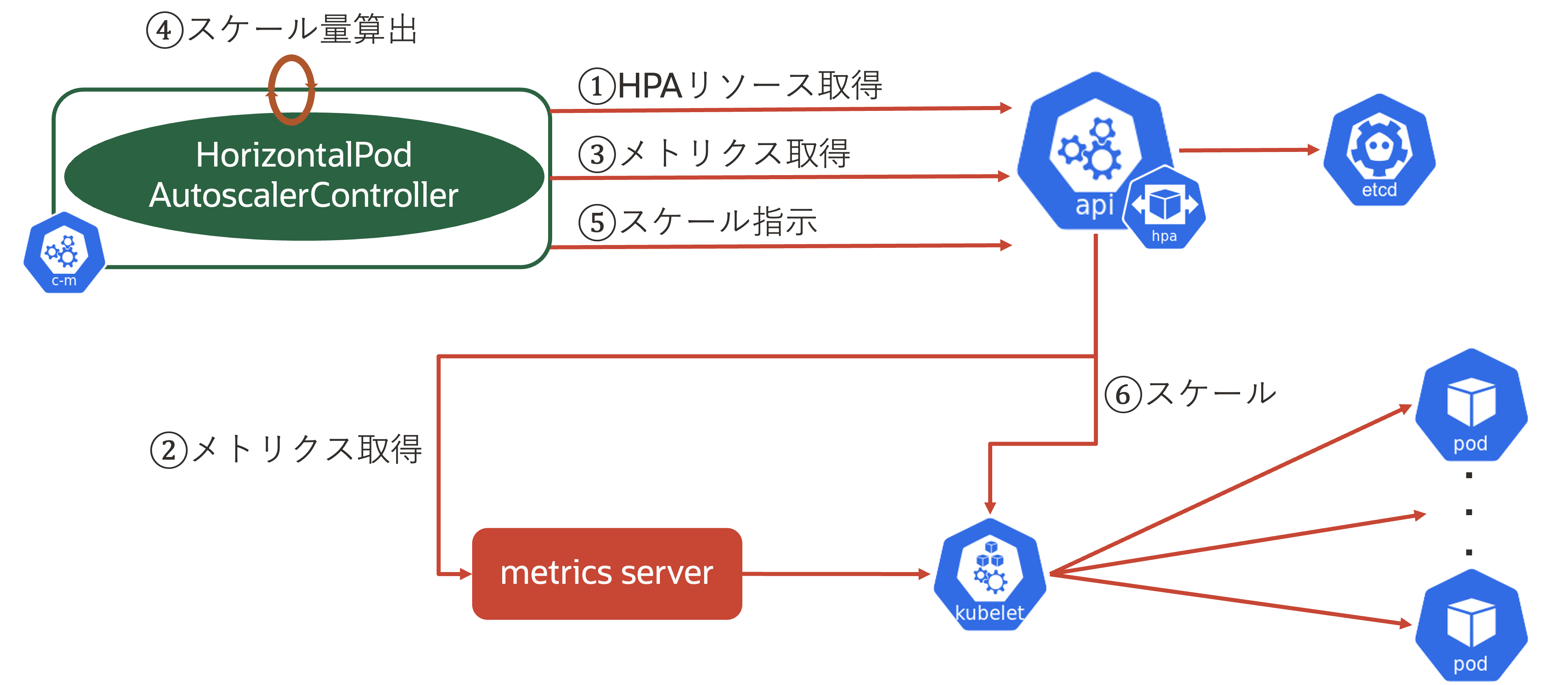
水平スケールの流れ
この流れを順番に説明します。
- HorizontalPodAutoscalerControllerがkube-apiserverからHPAリソースを取得
- kube-apiserverがmetrics server(後述)からkubelet経由でPodの現状のメトリクス情報を取得
- HorizontalPodAutoscalerControllerがkube-apiserverから(2)のメトリクスを取得
- HorizontalPodAutoscalerControllerがスケール量を算出
- HorizontalPodAutoscalerControllerがkube-apiserverに対してスケールを指示
- kube-apiserverがkubeletに対してスケール指示
ここで、上記で登場したmetrics serverについて説明します。
metrics server
metrics serverはPodのメトリクスを収集するためのコンポーネントです。最新はv0.7.1(2024/5現在)で、単一のDeploymentで動作します。デフォルトでは15秒ごとにメリクスを収集します。
metrics serverはKubernetesのマネージドサービスにおいてデフォルトでインストールされている場合もあれば、別途ユーザ自身でインストールが必要な場合もあります。kubeletからリソースのメトリクスを収集し、api-serverのMetrics APIを利用して公開します。公開されたメトリクスはkubectl topコマンドで取得できます。
metrics serverは本連載で紹介する3つのスケール手法(Podの水平/垂直スケール、Nodeの水平スケール)で利用する目的で想定されており、監視サーバへのメトリクスソースとしての利用は禁止されています。利用する場合はkubeletの/metrics/resourceエンドポイントから収集することが推奨されています。
スケール量の算出
HPAの解説に戻りましょう。先ほどHPAの動作イメージについて図示しましたが、その中でHorizontalPodAutoscalerControllerがスケール量を算出するという動作がありました。ここからは、HPAでどのようにスケール量が算出されるかを見ていきます。
HPAで算出されるスケール量は、以下のシンプルな式で構成されます。CPUをスケール時のメトリクスとした場合を例にします。
必要なレプリカ数 = 現在のレプリカ数 * ( Podの平均CPU使用率 / ターゲットのCPU使用率 )
つまり、Podが利用しているCPU使用率とユーザが定義したターゲットとするCPU使用率の比に現在のレプリカ数(Pod数)を掛けたものです。以下に具体例を示します。
- Pod(現レプリカ数:5)の平均CPU使用率の合計が90%、ターゲットのCPU使用率が70%の場合
- 必要なレプリカ数 = 5 * (90(%) / 70(%)) = 6.42…
- 7個のレプリカが必要(2個のレプリカが追加)
- Pod(現レプリカ数:5)の平均CPU使用率の合計50%、ターゲットのCPU使用率が70%の場合
- 必要なレプリカ数 = 5 * (50(%) / 70(%)) = 3.57…
- 4個のレプリカが必要(1個のレプリカを削除)
この際の考慮事項として以下があります。
- スケール量(レプリカ数)は整数で表現する必要があるため、小数点切り上げ
Podの平均CPU使用率は、各Podの過去1分間のCPU使用率
Resource RequestsとResource Limits
HPAのスケール量算出ロジックのうち、CPU使用率という言葉が出てきました。では、どの値をCPUの100%とするのかについて説明します。
KubernetesのPodにはResource RequestsとResource Limitsという2つの設定値があります。この値はコンテナのリソースを制御する上で非常に重要な設定値です。それぞれについて以下に整理します。
- Resource Requests
- Podをデプロイする際に必要とするリソース(メモリ/CPU)を指定できる仕組み
- Podがスケジューリングされる際にはResource Requestsに定義されたリソースを確保
- スケジューリング時にNodeにResource Requests分のリソースが空いているかをチェック
- Nodeにリソースに空きがない場合、Podの状態が
Pendingになる - PodはResource Requestsを超過してリソースを利用できる
- Podをデプロイする際に必要とするリソース(メモリ/CPU)を指定できる仕組み
HPAでは、このResource Requestsの値をCPU/メモリの100%の値とみなします。
- Resource Limits
- Podが最大で利用できるリソース(メモリ/CPU)を制限する仕組み
- 制限しない場合は無制限(Nodeの空きリソース分)にリソースを利用できる
- Resource Limitsを超過した場合は、それぞれ以下の挙動
- メモリ:OOM killもしくは再起動
- CPU:強制終了はされない。場合によってはCPUスロットリングが発生
- Nodeがもつキャパシティよりも大きな数値で指定することもできる
- Podが最大で利用できるリソース(メモリ/CPU)を制限する仕組み
ここで、Resource Requests/Limitsの定義方法について補足します。Resource Requests/Limitsでは、CPUとメモリの単位をそれぞれ以下のように定義します。
| リソース | 単位 | 補足 |
|---|---|---|
| CPU | core もしくは millicore | 数値だけ(単位を省略)した場合はcoreとして扱う。0.2 = 200m |
| Memory | Mi もしくは Gi | 100Mi≒0.1Gi≒104MB、1Gi≒1024Mi≒1074MB |
次に、これらを利用したQoS(Quality of Service) Classという仕組みも補足します。QoS Classはスケジューリングやevict(削除)される際に、Podへのリソース割り当ての振る舞いを決定する仕組みです。Resource RequestsとResource Limitsを元に判断されます。
例えば、Nodeのリソース不足の場合に、どのPodをevictするかをQoS Classにより決定します。このClassはGuaranteed/BestEffort/BurstableからKubernetesが付与(.statusフィールドに存在)します。
| QoS | 割当条件 |
|---|---|
| Guaranteed(優先度高) | 全PodにCPU/メモリのResource RequestsとResource Limitsが指定済みかつ同一値の場合 |
| BestEffort(優先度低) | 全PodにCPU/メモリのResource RequestsとResource Limitsが未指定の場合 |
| Burstable | Guaranteed/BestEffortいずれも該当しない場合(Resource Requestsのみ指定、Resource RequestsとResource Limitsの値が異なるなど) |
ちなみに、QoS Classが同一の場合は、OutOfMemory (OOM) scoreをもとにevictするPodを決定します。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Oracle Cloud Hangout Cafe Season5 #1「Kubernetes Operator 超入門」(2022年1月19日開催)
2023年3月17日 6:30
Oracle Cloud Hangout Cafe Season 4 #2「Kubernetesのネットワーク」(2021年5月12日開催)
2024年2月20日 6:30
Oracle Cloud Hangout Cafe Season6 #1「Service Mesh がっつり入門!」(2022年9月7日開催)
2023年6月22日 6:30
Oracle Cloud Hangout Cafe Season 4 #5「Kubernetesのオートスケーリング」(2021年8月4日開催)
2024年5月29日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
