KafkaにWASMモジュールを組み込んでリアルタイムで機械学習を実行するRedpandaのデモセッションを解説
KafkaにWASMを組み込んでリアルタイムで機械学習を実行するRedpandaのデモセッションを解説する。
2024年10月16日 6:00
ストリーミング処理のKafkaとAPI互換のあるRedpandaを使ってストリーミングでデータを受け取り、機械学習をバッチではなくリアルタイムでモデルを更新する、よりモダンなデモを使ってKafka互換のストリーミング処理を解説した動画セミナーを紹介する。これはThe Linux Foundationが2024年7月26日に公開したYouTubeの動画である。
●動画:Real-Time Predictions with Machine Learning & Streaming Data Transforms
動画の長さは50分を超えており、日本時間の7月26日深夜1時に行われたZoomによる配信がソースである。セッションを行ったのはRedpandaのDeveloper Advocate、Christina Lin氏だ。

デモとプレゼンテーションを自宅から行うLin氏
Lin氏は台湾出身で、Redpandaの前のキャリアはRed Hatのアーキテクトという名称の役職に就いていたようだが、LinkedInのプロフィールを見るとテクニカルなマーケティングというよりも顧客のシステムを解説し、販促に使うという仕事だったようだ。現在はマサチューセッツ州在住で、Redpandaのデベロッパー向けのマーケティング職となっている。セッションのタイトルが「Real-Time Predictions with Machine Learning & Redpanda Streaming Data Transform」となっているように、機械学習をリアルタイムで実行し、予測を行うシステムの解説とストリーミング処理をKafkaではなくRedpandaを使うことによる利点を前後半に分けて解説している。
前半はストリーミング処理の入門編という内容で、KafkaとRedpandaの比較を含めて解説している。そして後半は、現状の機械学習で主流のバッチ処理によってデータセットを生成するという方法に対して、リアルタイムでデータを更新するデモを解説することで、バッチに頼らない方法が可能であることを説明する内容となっている。

前半でストリーミング処理、後半はリアルタイムによる機械学習のデモを解説
前半の一番大事なスライドはコレだろう。Kafkaを構成するJavaとJVM、そしてここでは省略されているがZooKeeperという状態管理のためのクラスターからなる複雑なシステムから、C++で書かれたシンプルで高速なストリーミング処理のためのRedpandaを比較している。

KafkaとRedpandaを比較
そして機械学習や大規模言語モデル(LLM)を使ったアプリケーションの実装例を示して解説。ここでは包括的なモデルを提供するLLMとドメインに特化した推論を提供する機械学習モデルがハイブリッドになることで、現実的なアプリケーションとなるということを抽象的に解説している。
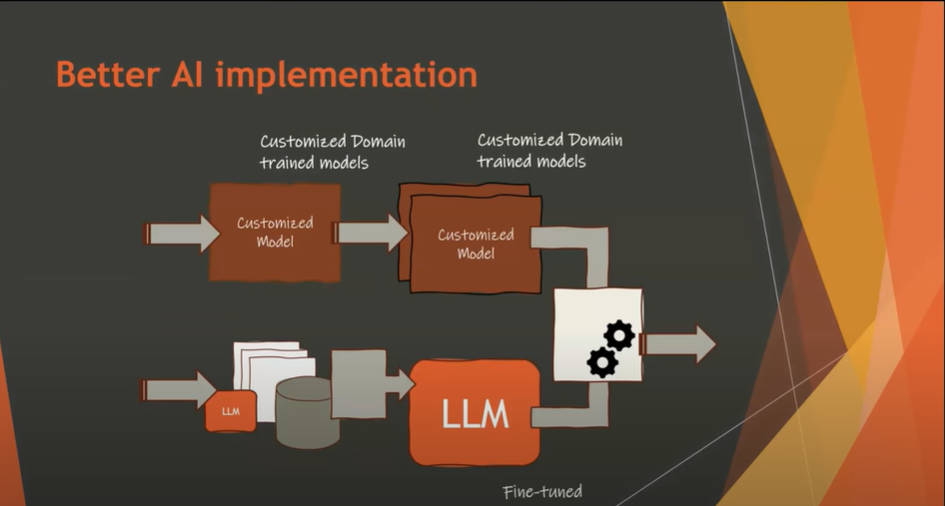
LLMと機械学習モデルのハイブリッドなアプリを提案
これには背景があると考えるべきだろう。Kafkaのストリーミング処理はイベントから発生するデータを複数のアプリケーションで活用するために、BrokerとConsumerが連係してやり取りすることで実装される。その前提からすればLLMも機械学習もアプリケーションのひとつとしてデータを消費する対象であるべきだというのがKafkaやRedpandaの発想だと思われる。
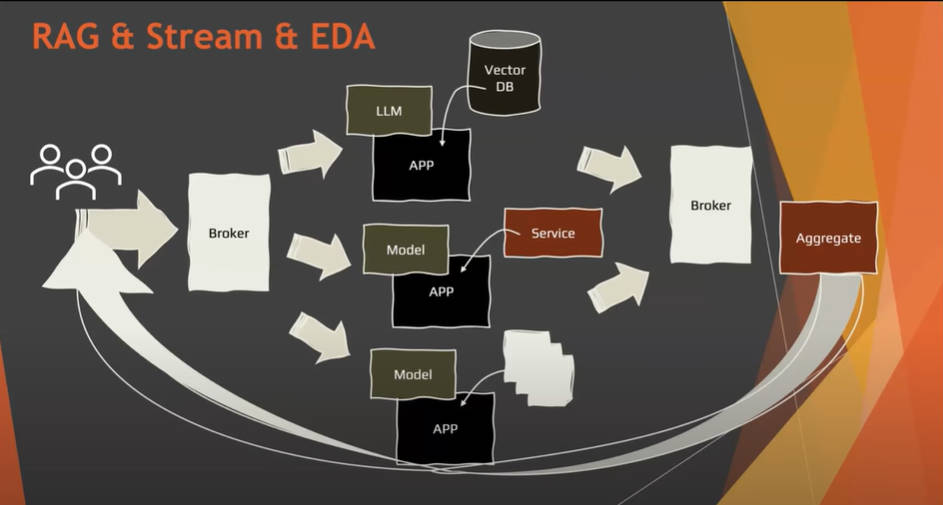
LLMも機械学習もデータを消費するアプリケーションとして位置付け
この図では、左側で発生したイベントデータがBrokerを通じてLLMや他のアプリケーションに配信され処理される概念を示している。アプリケーションによって処理されたデータは最終的に集約されてフィードバックされることも想定されている。
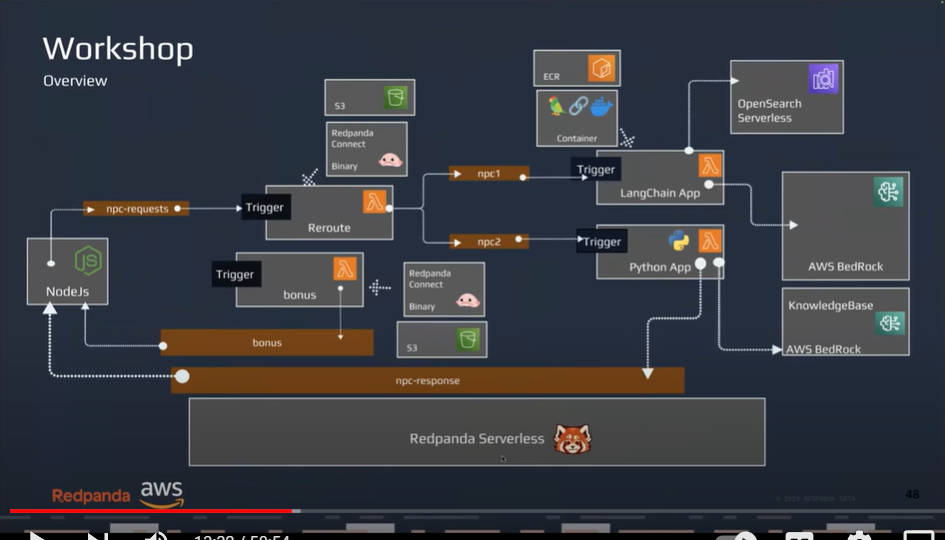
前半のデモのシステム構成図
ここからは、ストリーミング処理の中で複数のConsumerアプリケーションがメッセージを処理するというデモを解説するフェーズになった。デモの構成図は複雑だが、実際にはRPGを模したゲームのキャラクターが対話を行う内容となっている。
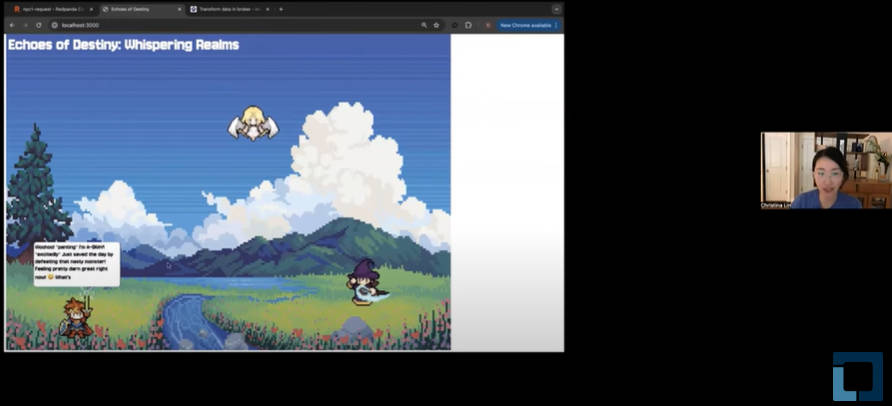
ゲーム上のキャラクターが対話を行うデモ
ここでは対話の処理の部分に複数のLLMを使って、それぞれの対話のトーンを変えるという内容のようだ。
そしてAIの実装についても解説を行っている。これは後半のデモの前振りとなるもので、さまざまなイベントデータを取り込んで機械学習のためのデータセットの生成(テストや学習を含む)を経てモデルが完成し、そのデータセットを使って推論を行うという機械学習のプロセスの中では定番という内容となっている。
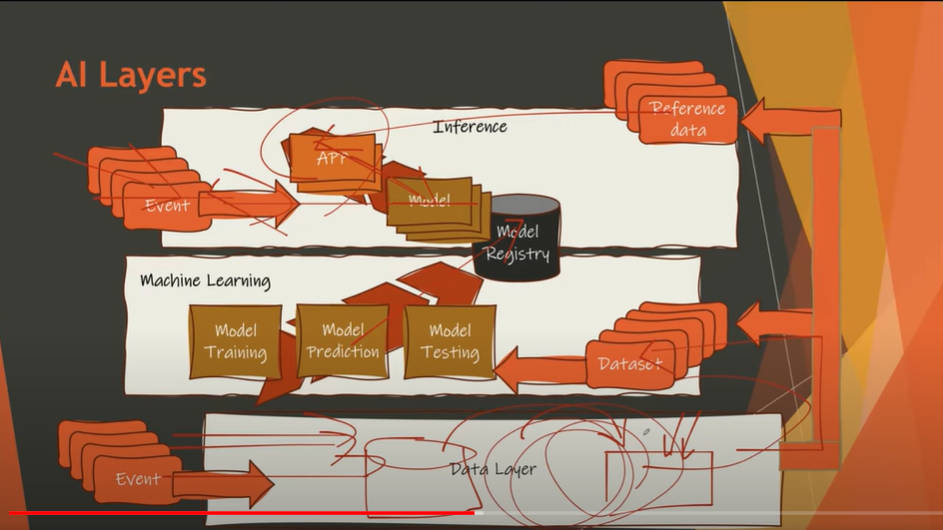
AIのためのデータがどのように処理されるかを説明するアーキテクチャー図
ここでは特にデータ処理のパイプラインが実行されることを強調している。そしてそのパイプラインの種類について解説したのが次のスライドだ。
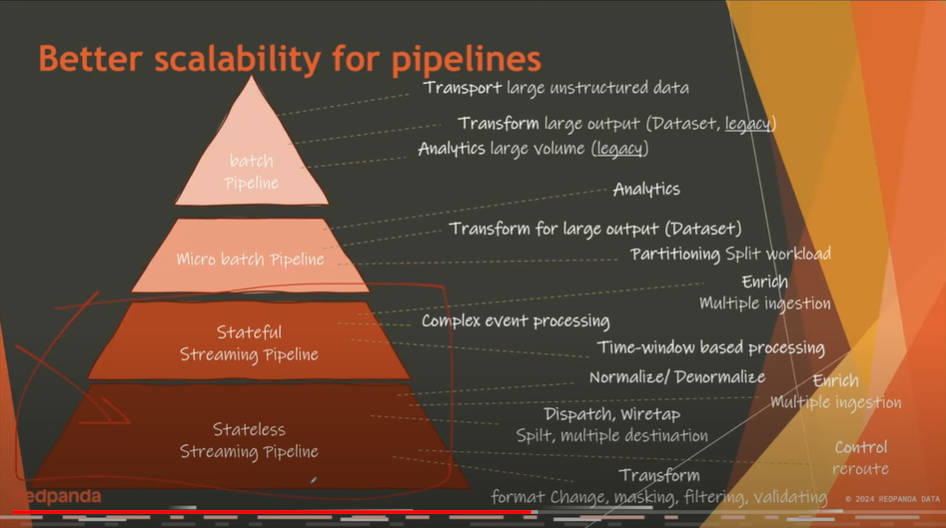
バッチからストリーミング処理までのデータ処理の違いを解説
この図にある三角形のトップにあるのが、従来の機械学習に使われるバッチ式でデータセットを処理する部分を表している。ここでは非構造的なクレンジングされていないデータを使うためにはバッチ式で行うことが示されているが、必ずしもそれを否定しているのではなく、バッチ式で構造的データに整形された後は、マイクロバッチ、ステートフルなストリーミング処理、最後にステートレスなストリーミング処理に移行していくということを意図していると思われる。
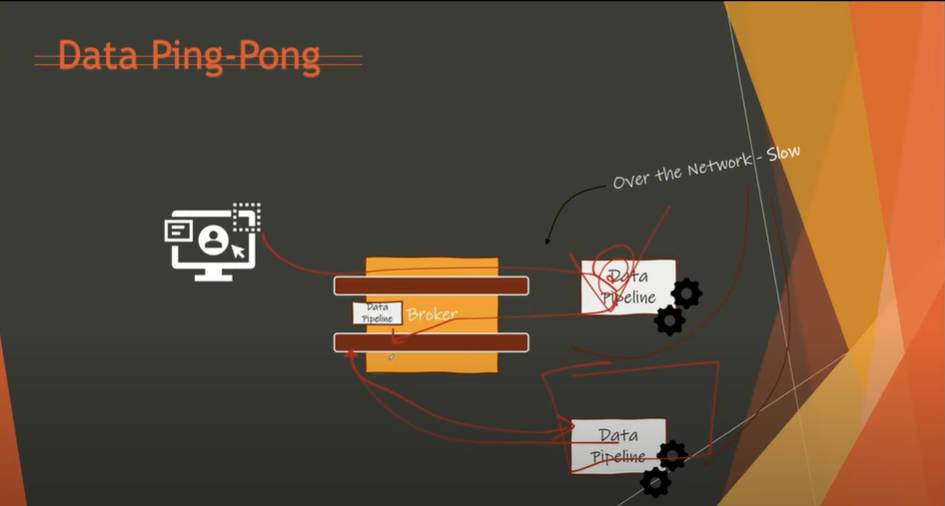
Kafkaによるデータ処理の問題点を指摘
そしてデータ処理がステートレスなリアルタイム処理に近付くに従って、問題として浮き上がってくるのが「データピンポン問題」であると説明。ここで「データピンポン」とはデータを処理するアプリケーションが分散していることでピンポンのボールのようにデータが行ったり来たりを繰り返すことでシステム全体の効率を落とすことだと説明。ここでもKafkaのレガシーなシステム構成が非効率的な構造であることを指摘していると言える。
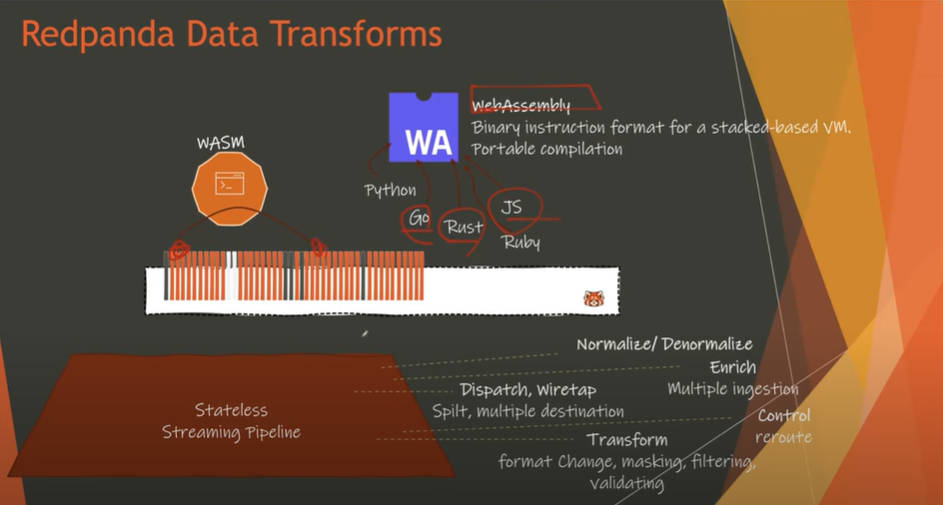
Redpandaのデータ処理。WebAssemblyに注目
そしてKafkaに比べて高速で非効率なデータ交換が不要なシステムとして紹介したのが、Redpandaのデータ変換のためのパイプラインだ。WebAssemblyがデータ変換アプリケーションとして実行されることで通信が削減されることを解説した。
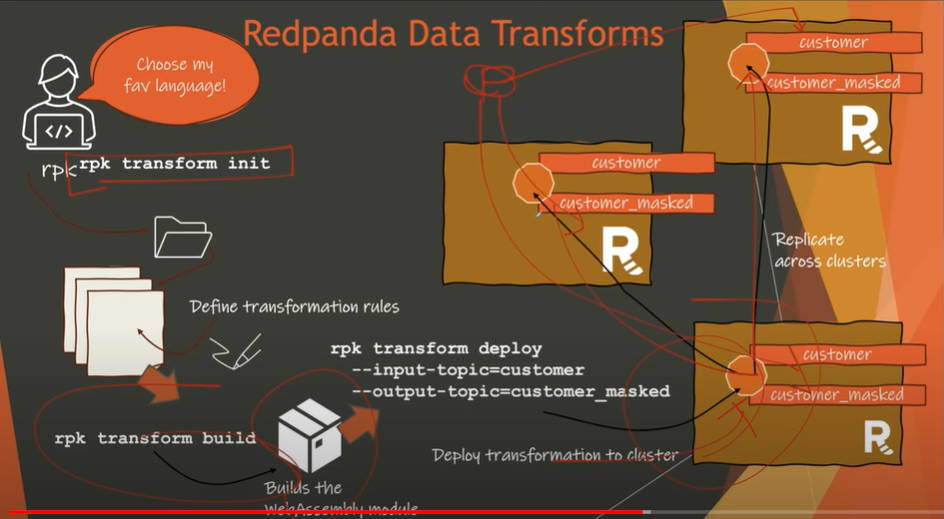
データ変換のアプリケーションが複製されることで可用性を保持
このスライドではKafkaのコンセプトである複数のノードでデータを複製することで障害時にもデータが保全される機能をRedpandaも持っていることを示している。そしてrpkというRedpandaのクラスターを管理するためのコマンドライン(rpkはRedpanda Keeperの略)を示して、初期化から実装までが行われることを説明している。これはこの後で実際にrpkコマンドでデモアプリを管理していることから、Redpandaを知らないエンジニアに簡単に操作が行えることを見せたということだろう。
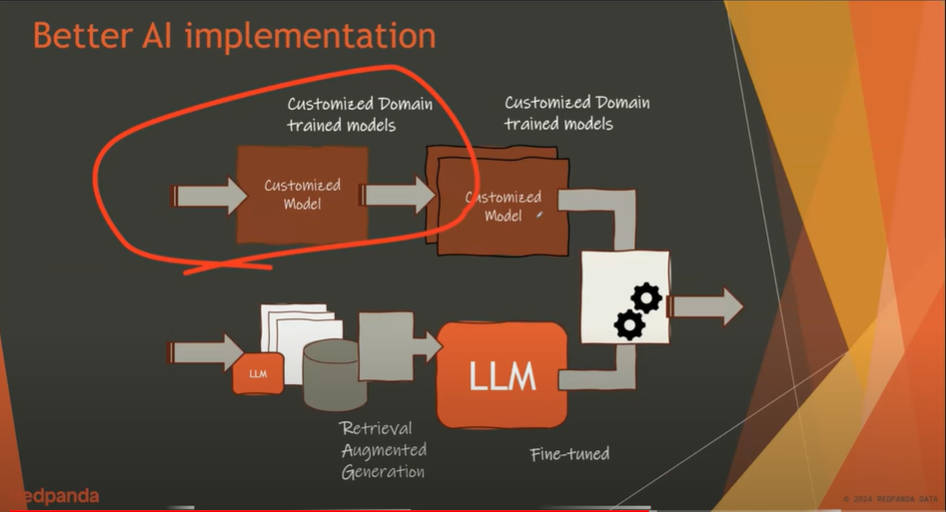
リアルタイムでデータセットを更新して機械学習で利用するデモを説明
ここからは後半のデモに移行して、バッチによるデータ処理ではなくリアルタイムでデータを更新することで、即座に推論に使える仕組みを解説するフェーズとなった。このデモで使われている例はフードデリバリーのアプリケーションだ。ここでは過去のデリバリーの結果のデータから、実際にデリバリーを依頼した時にどのくらいの時間で配達が行われるのかを推論するというものだ。
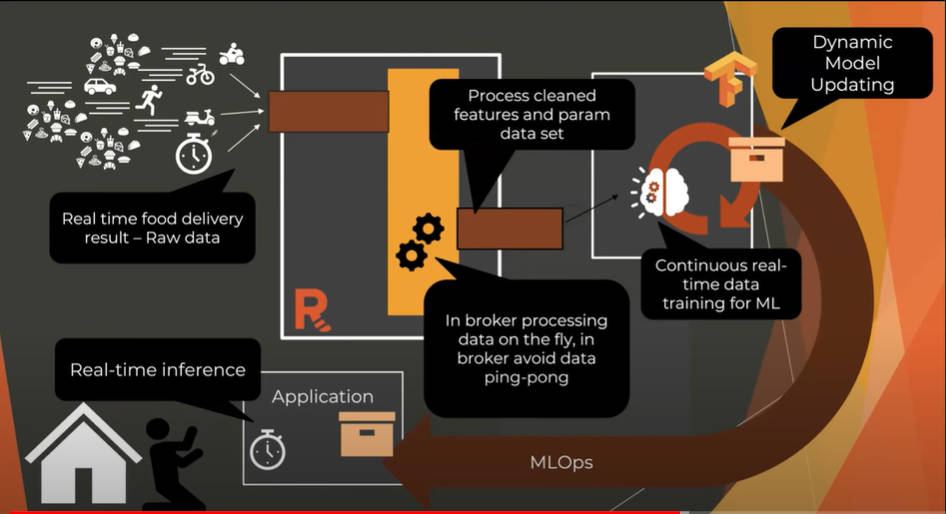
フードデリバリーを例に配達時間を推論
実際にデモのためのデータをJupyter Notebookを使って見せながら、データ処理、データの相関関係を検証、追加データをリアルタイムでデータセットに追加、更新されたデータセットを使って推論という部分を解説している。
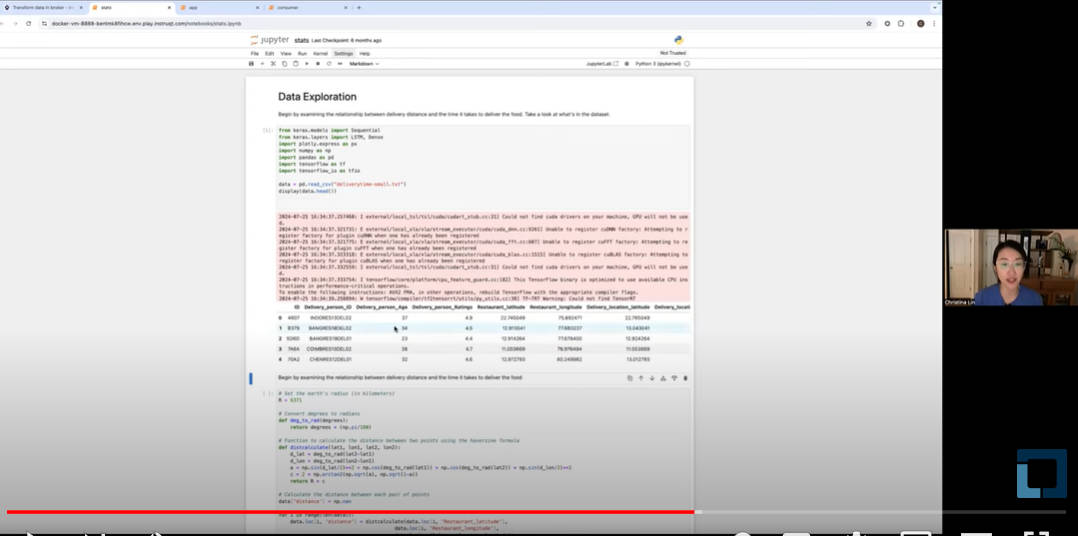
データ処理をJupyter Notebookで随時実行
データに存在する配達した距離、ドライバーの年齢や配達に利用する車種、ドライバーのレイティングなどの相関関係を見せながらデモを行っている。
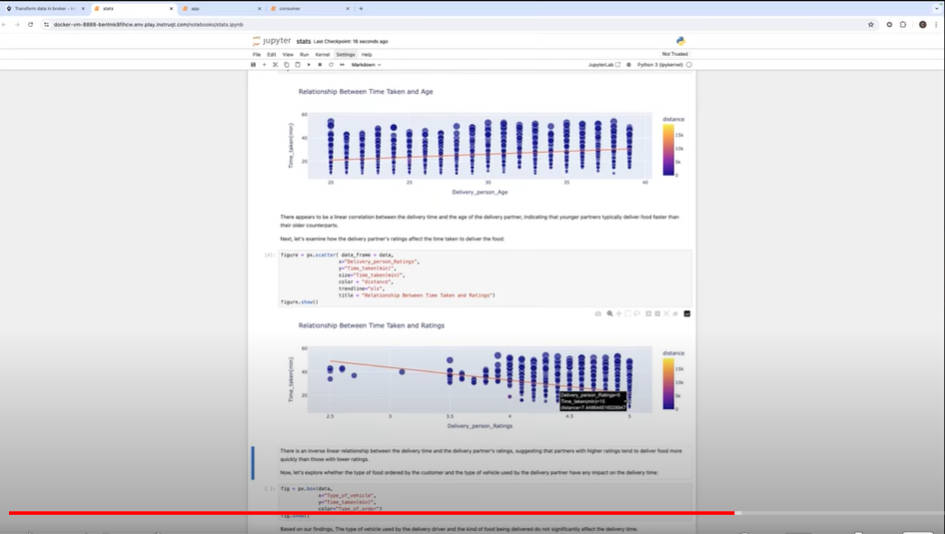
データの相関関係を可視化
Redpandaのコンソールから実際にデータが処理されていく状況を見せて説明。
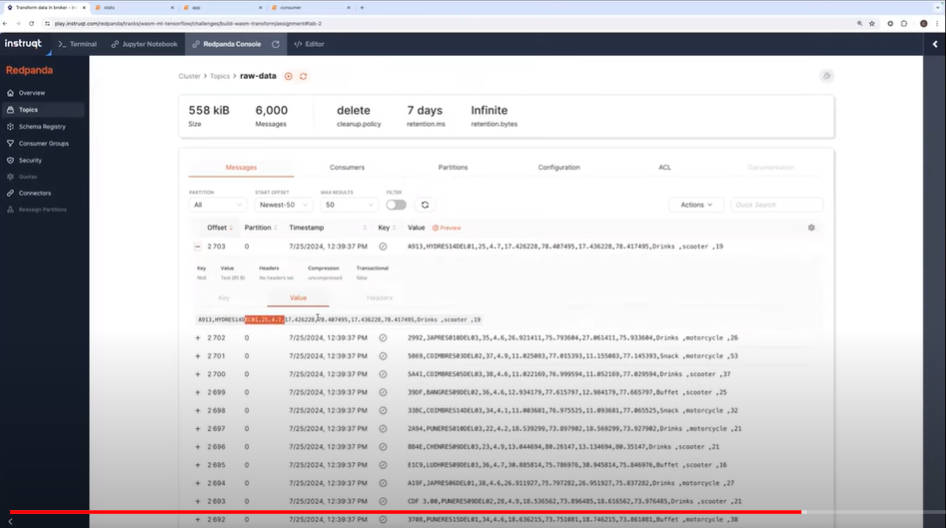
Redpandaのコンソールを見せながらデータ処理のデモ
複数のソースコードを見せながら、コンソールを使いつつコマンドを実際に入力してデモを行っているため、スクリーンが何度も変わっていく。それゆえに理解するのが難しい部分もあるが、システムの概念図は至ってシンプルだ。
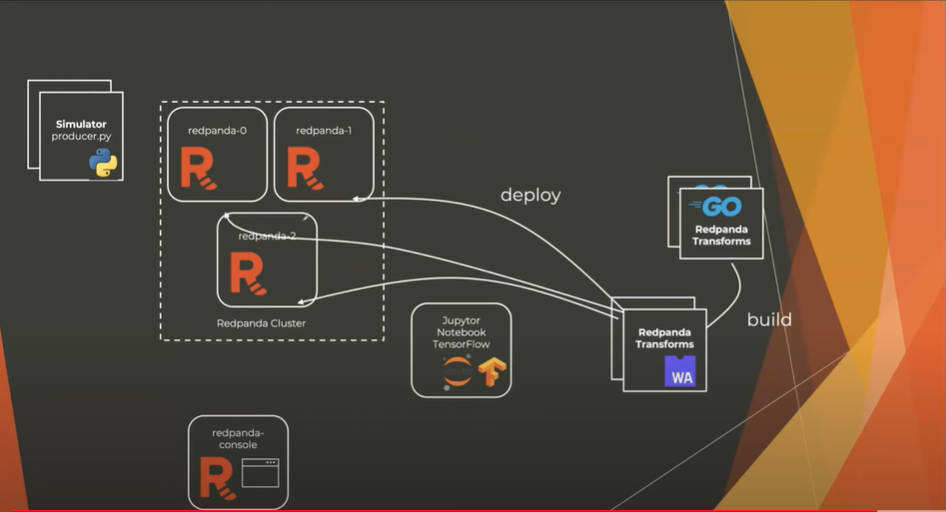
データを生成するシミュレーターからデータを受け取って配達時間を推論するデモ
デモの最後の部分では、実際にリアルタイムで更新されたデータセットを使って予想される配達時間を推論させている。この画面の赤い部分の下にLin氏がデータを入力して推論させた結果が表示されている。
50分という長いセッションの中でデータストリーミングの考え方から分散メッセージングを使って複数のアプリケーションをWebAssemblyで実装し、機械学習のためのデータセット更新をリアルタイムで行うデモまでを駆け抜けたという感じのセッションとなっている。
50分のセッションをやり切った感が強いLin氏
このセッションではKafkaの弱点を指摘し、データピンポン問題にも触れ、WebAssemblyによって高速なシングルバイナリーによる実行、そしてリアルタイムでデータセット更新というところまでを一気に説明している。前半のデモに気を取られずに後半のデモ、システム構成などにも注目して欲しい。
またRedpandaがWebAssemblyを使うことに関しては過去の以下の記事も参考にして欲しい。
●参考:Cloud Native Wasm DayからKafkaの拡張にWasmを使うRedpandaのセッションを紹介
またKafkaとAPI互換のあるRedpandaとしては、現在Kafkaを使っているユーザーが機械学習やLLMなどのアプリケーションをKafkaで構築するよりも、より高速でシンプルな構成となるRedpandaの上で構築してもらいたいと思っているのは当然だろう。Kafkaのコミュニティが従来のZooKeeperモードから新しいRaft合意形成プロトコルを使ったKRaftモードに移行することを強く推奨しているが、それには多くのコストが必要となる。そこで、その移行先をRedpandaにして欲しいという内容のブログが公開された。2024年7月30日に公開されたブログ記事では、移行のための複雑なプロセスが解説されている。これから新たなアプリケーションをKafkaで実装するのか、Redpandaというモダンなプラットフォームを選ぶのか、こちらも参考にして欲しい。
●KafkaのKRaftモードへの移行に関するブログ:ZooKeeper to KRaft migration: a brief overview and a simpler alternative
また今回のセッションを担当したCristina Lin氏によるデベロッパーアドボケイトの職を解説するブログも合わせて紹介しておこう。
●Lin氏の仕事を紹介するブログ:A day in the life of a developer advocate
- この記事のキーワード
この記事をシェアしてください
関連記事
Wasmでストリーミングエンジンを実装したRedpandaを紹介
2023年10月20日 6:00
KubeCon Europe 2024からWASMとeBPFを使ってストリーム処理を解説するセッションを紹介
2024年5月30日 6:00
wasmCloudのCosmonicのCEOが新しいデモを紹介
2023年9月4日 6:00
Kafka on Kubernetesを実現するStrimziに特化したカンファレンスStrimziCon 2024からキーノートを紹介
2024年7月8日 6:01
生成AIのためのコンポーネントをパッケージングするKitOpsの解説動画を紹介
2025年4月10日 5:59
KubeCon+CloudNativeCon North America 2023のキーノートとショーケースを紹介
2024年2月16日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
