生成AI向け機械学習クラスター構築のレシピ 北海道石狩編
CNDS 2024から、PFNのエンジニアによる生成AI向けクラスター構築を解説したセッションを紹介する。
2024年10月22日 9:09
2024年に開催されたCloudNative Days Summerにおいて、Preferred Networks(PFN)の清水 翔氏と上野 裕一郎氏が「生成AI向け機械学習クラスター構築のレシピ 北海道石狩編」と題したセッションを行った。生成AIに必要な膨大な計算リソースを活用するためのクラスター構築の要点、とくに石狩データセンターを舞台にした実例が解説された。サーバー、ネットワーク、ストレージといった技術的な側面を網羅し、最新の機械学習クラスターを効率的に構築するための実践的な手法が紹介された。
生成AI向け機械学習クラスターとは?
生成AI(Generative AI)は、大規模な言語モデル(LLM)やマルチモーダルモデルを使って、テキスト、画像、音声を生成するAI技術である。これらのモデルを学習させるには、膨大な計算資源が必要だ。PFNの清水 翔氏と上野 裕一郎氏は、石狩データセンターでの取り組みを実例として、生成AI向けの機械学習クラスターの構築について説明した。
上野氏は「私たちは大規模言語モデルを開発していますが、生成AIの学習には膨大なメモリと計算力が必要です。例えば、10ビリオン(100億)のパラメータを扱う場合、単純なメモリ使用量だけでも120GBに達します。これを1台のGPUで処理するのは不可能ですので、複数のGPUに分散します」と語る。
生成AIのクラスターには、学習をできるだけ早く開始し、迅速に結果を得たいという要望が強い。そのためには最新の高性能なGPUを大量に利用する必要があるし、またGPU間の高速通信や、モデルデータのスナップショット用の高速ストレージも不可欠である。
これらの要件を満たすためにPFNが採用したのが、さくらインターネットの「高火力PHY」サービスだ。高性能な高火力PHYサービスでNVIDIA H100 GPUを8基搭載したベアメタルサーバーを使用して、クラスターを構築した。
機械学習クラスター構築のレシピ
PFNは、さくらインターネットが提供する「高火力PHY」と「専用サーバーPHY」の2つのベアメタルサーバーサービスを活用した。高火力PHYは、生成AIの学習に必要な計算リソースを効率的に活用できる高性能なサーバーである。物理リソースを直接利用できるため、仮想化によるオーバーヘッドを最小限に抑え、最大の計算性能を引き出すことが可能だ。

さくらインターネットの高火力PHY
一方、専用サーバーPHYもベアメタルサービスで、管理ノードやコントロールプレーンの構築に活用された。このサービスは「さくらのクラウド」と併用され、クラスターの検証やスケーリングの際には柔軟に対応できる構成を実現している。コントロールプレーンのスケーラビリティを確保するために、この構成が選ばれたという。
「さくらインターネットのサービスは、高性能かつ柔軟なクラスターを実現するために理想的でした」と清水氏は語っている。
サーバーとネットワーク構成
クラスター設計では、トレーニング用のGPUノードとして「高火力PHY」が使用され、最大限の計算パフォーマンスが発揮された。各GPUノードはNVIDIA H100 GPUを搭載し、200Gbpsのインターフェースを通じて効率的なトレーニングデータの処理を行う。これにより膨大なデータを短時間で学習できる環境を整えた。
ネットワーク構成は、通常の通信ネットワークに加えてGPU間の高速通信を可能にするインターコネクトネットワークが併用されている。スタティックルートの設定により、トラフィックをインターコネクトへと優先的に流すことで通常のネットワークへの負荷を軽減し、全体的な通信速度を向上させる工夫を行っている。
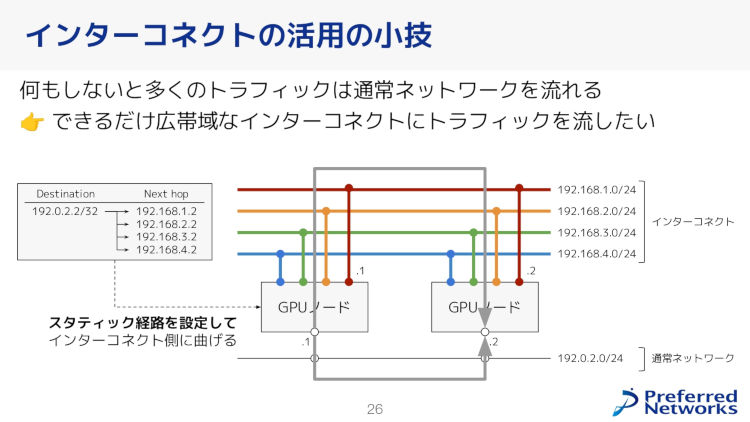
インターコネクトの活用の小技
PodネットワークとCNI pluginの役割
高性能なトレーニングには、効率的なネットワーク構成が不可欠だ。PFNは、RDMA(Remote Direct Memory Access)を利用するため、Pod間通信に特化したCNI pluginを活用した。KubernetesクラスターにおけるCNI pluginは、コンテナのネットワーク設定を自動化し、効率的な通信を実現するためのツールだ。
今回のクラスター構築では、2種類のCNI pluginが使われており、1つは通常のネットワーク通信用、もう1つはRDMAを使用した高速通信用である。PFNは、SR-IOV(Single Root I/O Virtualization)を活用し、各Podに複数のネットワークインターフェースを割り当てる構成を採用している。またWhereaboutsというIPアドレス管理ツールを使い、動的なIPアドレス割り当てが行われた。
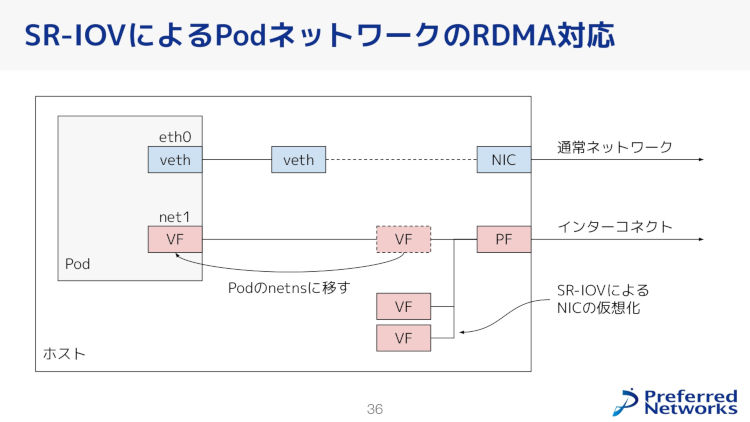
SR-IOVによるPodネットワークのRDMA対応
Cluster APIによる自動化
生成AI向けのクラスターを大規模に運用するうえで、ノードのセットアップや管理を手作業で行うのは非常に手間がかかってしまう。そこでPFNは、Kubernetesの「Cluster API」を導入し、クラスターの構築や運用を自動化している。Cluster APIは、Kubernetesクラスターそのものをリソースとして管理できるオープンソースで、ノードの作成、削除、セットアップを自動化する。
「手作業で数十台のサーバーをセットアップするのは非常に大変ですが、Cluster APIを導入することで、プロセスが大幅に効率化されます」と清水氏は説明している。
Cluster APIを使うことで、15分以内に新しいVMをセットアップすることが可能になった。一方、ベアメタルサーバーである「高火力PHY」の構築にはより多くの手順が必要であり、1時間程度かかるが、Cluster APIによってベアメタル特有のネットワーク切り替えやOS再インストールの自動化が実現された。
実装における課題と工夫
PFNが構築した生成AI向けクラスターの実装において、ワーカーノードのセットアップやストレージの構成は重要な要素であった。ワーカーノードは、トレーニングを実行するための重要なリソースであり、各ノードにはGPUドライバやNICドライバがインストールされる。
PFNはCluster APIを活用し、ワーカーノードのセットアップを自動化し、手動作業の負荷を大幅に軽減した。とくにAnsibleなどを使ったセットアッププロセスでは、サーバー間の不整合やバージョンの違いが生じることがあるが、自動化によってこれらの問題が解消された。
ストレージも課題だ。「生成AI向けにもっとも適したストレージは現状見つかっていない」としながらも、PFNは「現時点での最適解として」、Rook/Cephを使用し信頼性を確保しながら、内製の分散キャッシュシステムを併用してパフォーマンスを向上させる方法を選択している。
「Rook/Cephはパフォーマンス面での課題がありますが、信頼性は高いです。そのため信頼性に課題はあるが性能の高い分散キャッシュシステムを併用して、性能と信頼性のバランスを取りました」と上野氏は語る。
セッションの最後に上野氏は「さくらインターネットの石狩データセンターを利用し、生成AI向けのKubernetesクラスターを構築しました。クラスター構築のデザイン空間は広く、考えることはたくさんあります。今回紹介したレシピは現時点でのベストプラクティスです」と語り、今回のクラスター構築を総括してセッションを締めた。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
【CNDS2025】国産クラウドが目指すCloudNativeの未来 さくらのクラウドの進化と展望
2025年6月13日 6:01
NoSQLとNewSQLの技術革新、マルチテナンシーの実現と高いスケーラビリティを提供
2024年8月19日 6:00
アプリケーションをモジュラーモノリスとして記述し、容易にマイクロサービスとしてデプロイできるフレームワーク「Service Weaver」
2024年7月23日 6:30
【CNDW2025】日本初のクラウド勘定系を実現した次世代バンキングシステムの設計と運用
2025年12月19日 6:00
次世代クラウド基盤「Wasm」の可能性と課題を探る
2024年11月5日 9:06
【CNDW2024】東京ガスの内製開発チームが挑むKubernetesの未来
2025年3月10日 6:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
