CloudNative Days Tokyo 2023から、NVIDIA H100を80基使ったKubernetesベースの機械学習プラットフォームを解説
CloudNative Days Tokyo 2023から、サイバーエージェントのエンジニアによるAIプラットフォーム関連のセッションを紹介する。
2024年1月15日 6:00
2023年12月11日、12日にオンラインとリアルの会場のハイブリッド形式で開催されたCloudNative Days Tokyo 2023のキーノートから、株式会社サイバーエージェントの漆田瑞樹氏によるAIプラットフォームに関するセッションを紹介する。

セッションを担当したサイバーエージェントの漆田瑞樹氏
タイトルは「Kubernetesで実現する最先端AIプラットフォームへの挑戦」。サイバーエージェントでは既存の生成AIサービスを使ったり、基盤モデルをファインチューニングしたりするのと同時に、独自のLLM(Large Language Models、大規模言語モデル)であるCybarAgentLM(CALM)をフルスクラッチで開発して公開している。漆田氏はプライベートクラウドを開発するCIU(CyberAgent group Inrfastructure Unit)の中の、MLチームの立場から、CALMを開発するための分散学習プラットフォームについて解説した。

サイバーエージェントが開発中のCyberAgentLM
機械学習に3年弱かかる!? H100と分散学習で解決
生成AIなどの機械学習には、莫大な計算リソースが必要となる。ある論文によると、さまざまな機械学習モデルについて、リリースされた日とそのモデルの学習に必要な計算リソースをグラフにとると、対数グラフで線形に、つまり指数関数的に上昇していることがわかる。

機械学習が必要とする計算リソースは急激に上昇している
米Metaの開発したLlama 2を例にとると、いちばん大きなパラメータ数70B(700億)のモデルで、NVIDIA A100 GPU 1基で172万時間(約200年)かかってしまう。いちばん小さなパラメータ数7B(70億)でも18万時間(約20年)かかる。これではビジネスが求めるスピードには間に合わない。

年単位の時間がかかるのではビジネスのスピードに追い付かない
この問題に対してサイバーエージェントでは、最新のNVIDIA H100 GPUを80基導入した。H100はA100に比べて、単体の性能が約6倍と公式に発表されている。
さらに、インターコネクト(ノード間ネットワーク)を使って1つのモデル作成を複数ノードに分散して学習できるようにした。これにより、約20年かかっていた学習が16日で終わるという計算になる。
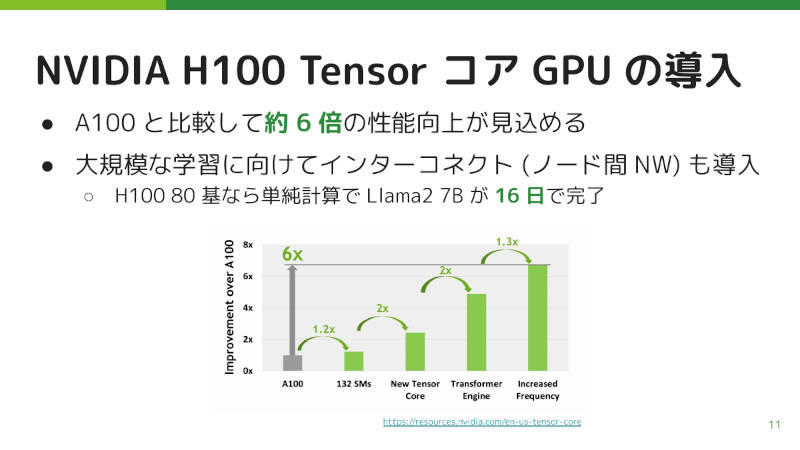
最新のNVIDIA H100 GPUを80基導入
GPUを公平かつ効率よく使うためのジョブ制御をKueue Controllerで
サイバーエージェントのCIUでは、この機械学習基盤を開発。GPUノードを含むKubernetesクラスター上で、Notebook、ジョブ、サーバーレス推論、分散学習ジョブを運用している。
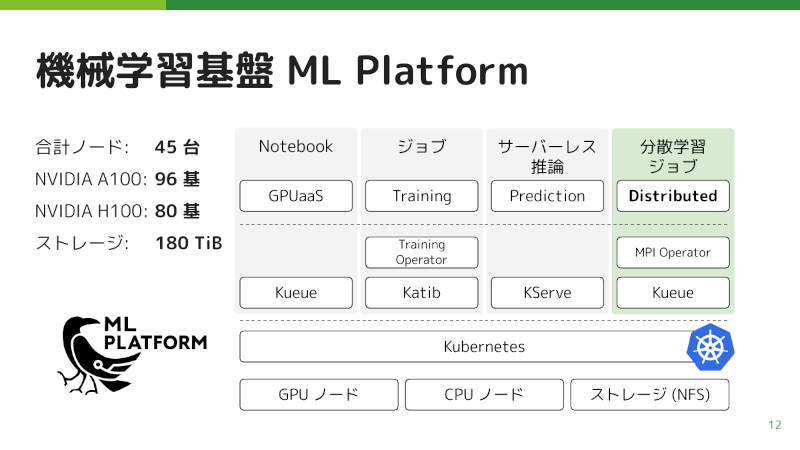
Kubernetes上に構築された機械学習基盤
分散学習では、ユーザーからのジョブの作成リクエストがキューに積まれ、そのキューから取り出されたジョブがKubernetes上にデプロイされて学習が動く。学習部分は、学習スクリプトを起動するLauncherと、実際に学習が動くWorkerから構成される。ログはGrafana Lokiで収集される。

機械学習基盤の詳細な構成
要件としては「順序をきちんと保証することで公平性を確保したい」「特定のテナントだけがGPUをたくさん使ってしまうことのないようクォータで制限したい」「A100とH100のどちらを使うかを指定できるよう管理したい」があり、さらに「GPUに空きがあればクォータを超えて使えるようにして基盤の稼働率を最大化したい」ということがある。
これらを、キューによるジョブ制御に、OSSのKueue Controllerを使うことで解決した。

要件はKueueを使うことで解決
400GbE NIC×8をフルバイセクションで接続し、RDMAも利用したインターコネクト
さて、マルチノードをインターコネクトで接続して1つの機械学習をする分散学習では、広帯域で低レイテンシーのネットワークが重要だ。
サイバーエージェントの分散学習プラットフォームでは、インターコネクトをFat-tree構成によりフルバイセクションで構築。半数のノードが残り半数のノードと一斉に通信してもボトルネックが生じないようにしている。
ノードには400GbEのNICを8つ入れて、理論値で最大3.2Tbpsの帯域となっている。さらにRDMA(Remote DMA)によって、別ノードのGPU間でCPUを介さずに直接通信する。
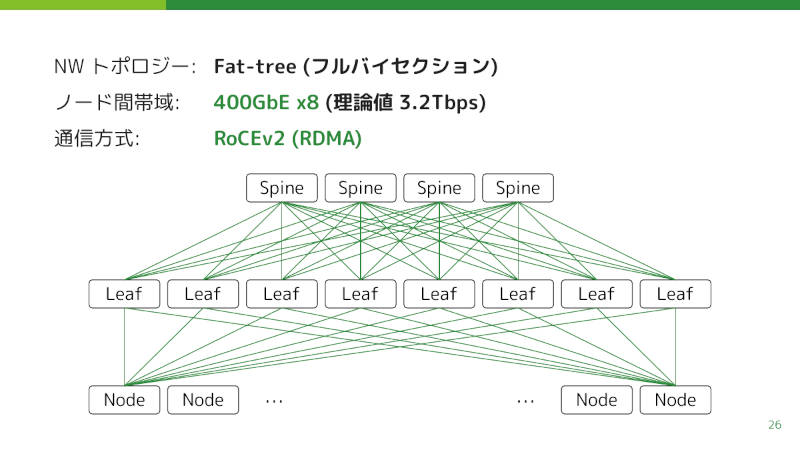
ネットワーク・トポロジー
このネットワークをKubernetesから使うために、Device PluginによってNICをKubernetesのリソースとして認識させている。直接認識させるとコンテナに渡したときにホストから見えなくなるため、NICをSR-IOVで仮想NICに分割して認識させているという。
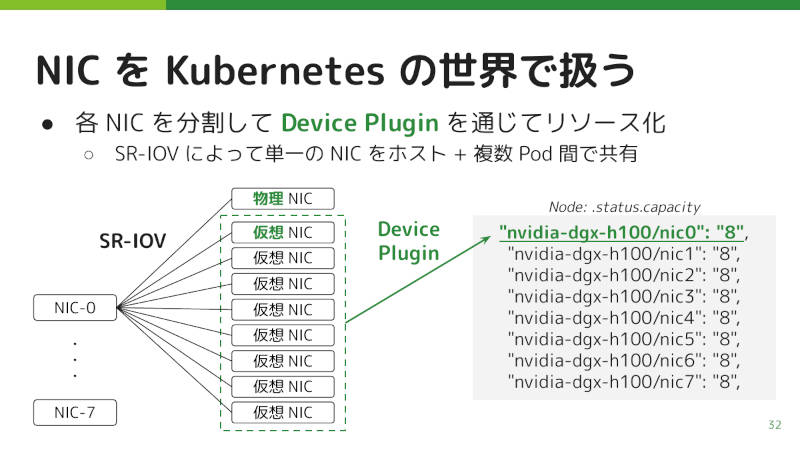
NICを仮想NICに分割してKubernetesから利用
こうしてKubernetesで認識されたNICを、PodのWorkerにアタッチする。サイバーエージェントでは、GPUとNICのローカリティを直接は考慮せず、NVIDIAのNCCL(NVIDIA Collective Communications Library)に経路選択を任せている。これによってシステムがシンプルになったため、結果的に良かったと考えている、と漆田氏はコメントした。
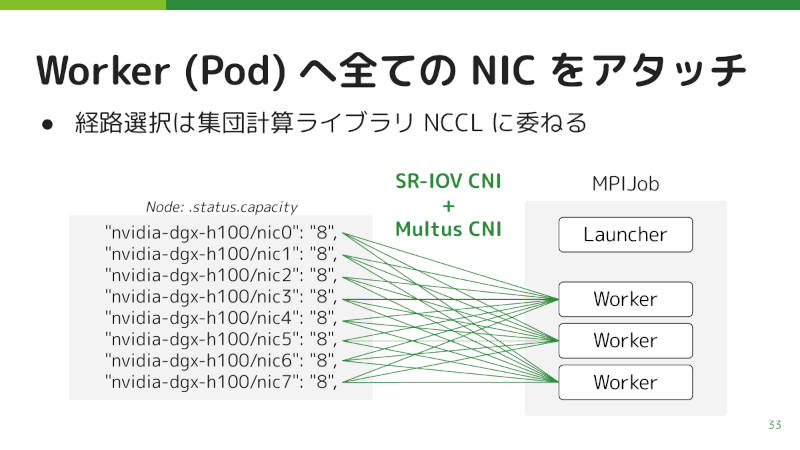
経路選択をNCCLに委ねることでシステムをシンプルに
GPUを増やしたときにスケールすることを検証
ではその性能検証の結果だ。H100はA100に比べて約2.5倍の性能が検証された。なお、これはH100のTransformer Engineを利用していない状態での結果であり、そちらを使うことで6倍の性能差を出すかもしれないということで、今後検証したいとの話だった。
また、計算リソースを増やしたときにちゃんとスケールするかについても検証。8基から80基まで増やしたときに、だいたい線形にスケールすることがわかった。これにより、今後リソースを増やしていった場合にも、学習速度がスケールすることが期待できるということであった。
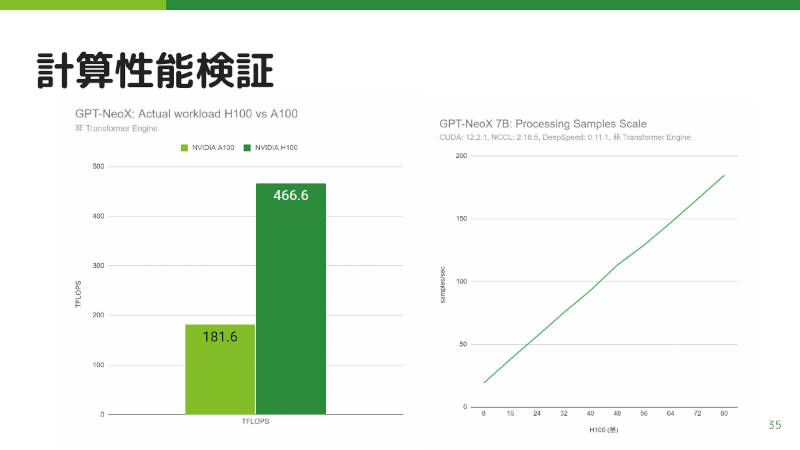
学習速度はスケールすると期待できる
NVIDIA H100を80基使い、それを活かすためのインターコネクトを構成するという、ハイエンドな機械学習プラットフォームのアーキテクチャが紹介されたセッションだった。
これをいかにKubernetesで実現し、ジョブ制御やインターコネクトを実装するかが解説された。Kubernetesをベースとしたプラットフォームで、何日にもわたるバッチジョブを制御し、400GbE NICのフルバイセクション接続に対応できるというのが興味深い。
現時点で直接の参考にできるユーザーや企業はそれほど多くはないだろうが、Kubernetesの可能性を感じさせるセッションだったと言える。
この記事をシェアしてください
関連記事
CloudNative Days Tokyo 2023から、クラウドネイティブセキュリティの脅威や論点を紹介
2024年2月19日 6:00
KubeCon China 2024、Kubernetes上でMLジョブのフォルトリカバリーを実装したKcoverのセッションを紹介
2024年11月12日 9:16
KubeCon China 2024、GPUの故障を検知するOSSを解説するセッションを紹介
2024年11月27日 8:06
【CNDW2025】containerlab×kindでひもとくBGP+Kubernetes検証環境の作り方とサイボウズでの実践
4月23日 6:00
de:code 2017セッションレポート:CNTKでディープラーニングを始めるには
2017年6月15日 19:00
Community Over Code Asia 2025から異機種GPU対応のスケジューラーHAMiのセッションを紹介
2025年11月12日 5:59
バックナンバー
この記事の筆者

筆者の人気記事
使って分かった国産クラウド「K5」のメリットとは
2018年1月31日 6:30
初めてでも安心! OCIチュートリアルを活用して、MySQLのマネージド・データベース・サービスを体験してみよう
2021年4月21日 12:39
Dockerを理解するための8つの軸
2015年7月29日 22:00
Dockerの誤解と神話。識者が語るDockerの使いどころとは? Docker座談会(前編)
2016年2月22日 0:00
【イベントリポート:Red Hat Summit: Connect | Japan 2022】クラウドネイティブ開発の進展を追い風に存在感を増すRed Hatの「オープンハイブリッドクラウド」とは
2022年11月10日 8:45
Kubernetes、PaaS、Serverlessのどれを選ぶのか? 機能比較と使い分けのポイント
2018年5月23日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
