KubeCon China 2024、GPUノードのテストツールKWOKを解説するセッションを紹介
KubeCon China 2024、GPUの故障を検知するOSSを解説するセッションを紹介。
2024年12月3日 6:00
KubeCon China 2024はAI_devという生成型AIに特化したカンファレンスも併催されていたために、多くの生成型AI及び機械学習関連のセッションが行われた。その中でも「GPUが障害を起こした時にどう対応するべきか?」という点に特化したセッションが複数行われていた。実際にはGPUが故障した場合には交換するなどの方法しかないわけだが、数十時間もかけて学習したデータセットをそのまま無駄にするのではなく、チェックポイントを取って別のGPUノードで継続するなどの対応が必要だ。
しかし実際にGPUノードの故障を待っているのではなく、Kubernetesのノードを疑似的に起動してそのアノテーションにエラーのステータスを設定して疑似的にエラーを起こし対応を試験するという方法が存在する。この稿ではKWOK(Kubernetes WithOut Kubeletの略)というKubernetesのSIGで開発が進められているツールの解説を、DaoCloudのエンジニアとNVIDIAのエンジニアが行ったセッションを紹介する。このセッションは会期2日目、2024年8月22日のキーノートセッションのひとつとして行われた。

セッションはDaoCloudとNVIDIAのエンジニアによって実施
KWOKの概要を説明
セッションのタイトルは「Supporting Large-Scale and Reliability Testing in Kubernetes using KWOK」、プレゼンターはDaoCloudのShiming Zhang氏とNVIDIAのYuan Chen氏だ。最初にDaoCloudのZhang氏によるKWOKの概要説明からセッションは始まった。
Kubernetesのクラスターはコントロールプレーンとワーカーノードで構成されるが、KWOKはコントロールプレーンに対して疑似的なノードの情報を与えることでコントロールプレーン上は数百台のノードが存在しているようにシミュレートするためのツールとなる。

KWOKの概要。コントロールプレーン上ではノードとして認識される
KWOKのコントローラーがノードやPod、他のオブジェクトをシミュレートし、API経由でのアクセスも可能な構成を生成する。起動、終了などのライフサイクルもそのままシミュレートできるという。

KWOK Controllerが疑似的なクラスターを生成
KWOKは上記のKWOK Controllerとkwokctlというコマンドラインツールから構成されているシンプルなツールのようだ。

KWOKの主なツールはコントローラーとコマンドラインツール
生成されるノード数は1,000、Podの数は10,000までとなっており、実際にステータスの画面を見せて説明を行った。
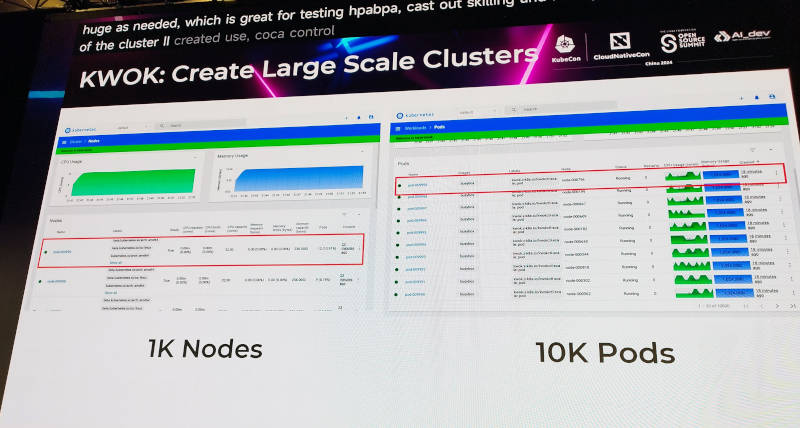
ノードは1,000、Podは10,000まで生成可能
KWOKは同じ機能を実装した他のツールであるkubemarkと比べてKubeletを起動しないことから消費するリソースが少なく、ノードやPodの起動も高速であると公式サイトには解説が記載されている。
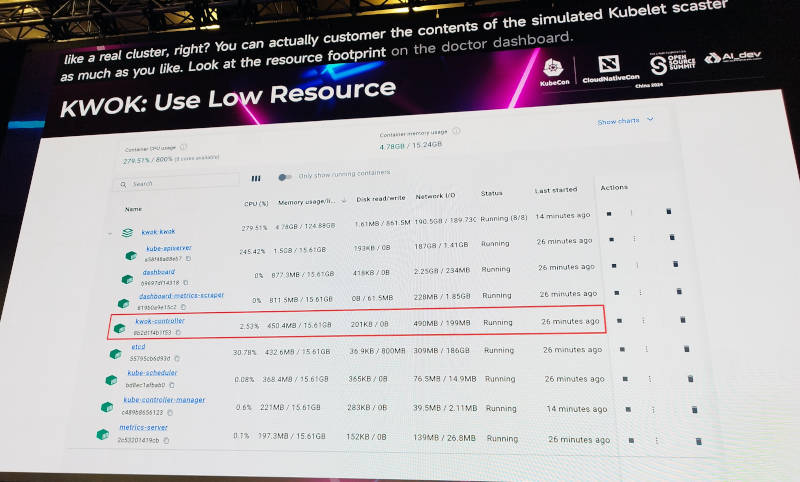
消費するリソースが少なく高速なことが特徴。CPUの使用率は3%以下
実際にkwokctlをターミナルで起動してクラスターのステータスを確認するなどのデモを挟んでサマリーを紹介。ここではKWOK Controllerとkwokctlの概要を説明してNVIDIAのChen氏に交代した。
障害耐久性は大規模GPUクラスターに必須
Chen氏は大規模なGPUクラスターの構成から説明を行い、ハードウェアのトポロジー、接続されるネットワーク構成、使われるコンポーネントなどを紹介。それをKubernetesから制御する際のコンポーネントまでまとめて解説を行った。

GPUクラスターの概要。ソフトウェアはKubernetesを使用するケース
NVIDIAが公式に提供する各種ドライバーやツールなども紹介された。
そしてGPUのクラスターにおいては障害、エラーが起こることはもはや当たり前であり、その前提を受け入れて欲しいと解説した。

GPUクラスターのエラーは前提としてプロセスを構成して欲しいと訴求
障害耐久性をGPUクラスター運用の中に取り入れることが必須であり、そのためには障害が起こることを想定して対処方法を設計するべきと説明。そこで役に立つのがシミュレーションを実施するツールのKWOKであると解説した。

KWOKでクラスターにエラーを意図的に注入する
ノードやPodに対してエラーや終了条件をアノテーションとして追加することで、コントロールプレーンからはエラーと認識され、ジョブのリスケジューリングなどのシミュレーションを行えると説明した。
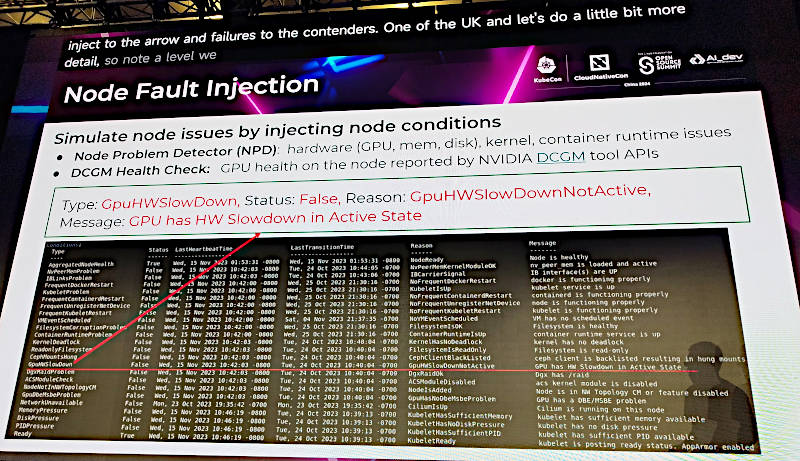
ノードにエラーを注入
注入されたエラーはKubernetesのNode Problem DetectorやNVIDIA製ヘルスチェックで検知することを解説。
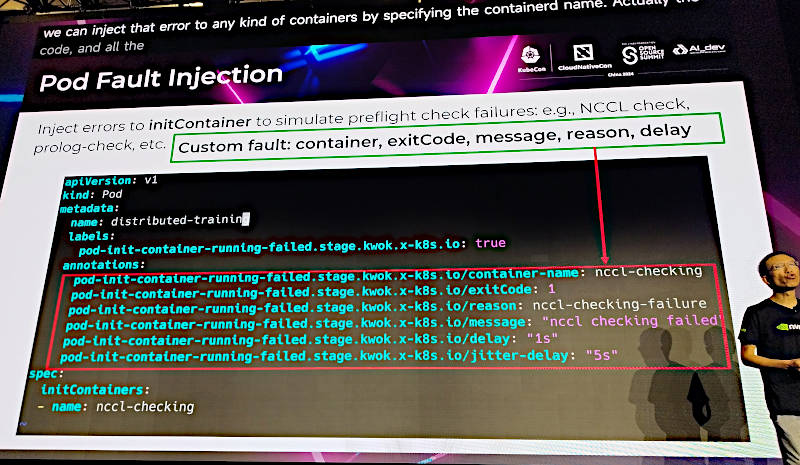
Podにエラーを注入
NCCL checkなどのツールで検知可能となり、Podの再実行などの対処方法を検証できる。
実際にKWOKを使ってエラーを起こす方法を2つのパターンで説明。ここではNVIDIA推奨のパターンとしてジョブがスケジューリングされる前のチェックの際にエラーを起こすパターンと、ノードにエラーのステータスを注入して対処を行うパターンが紹介された。
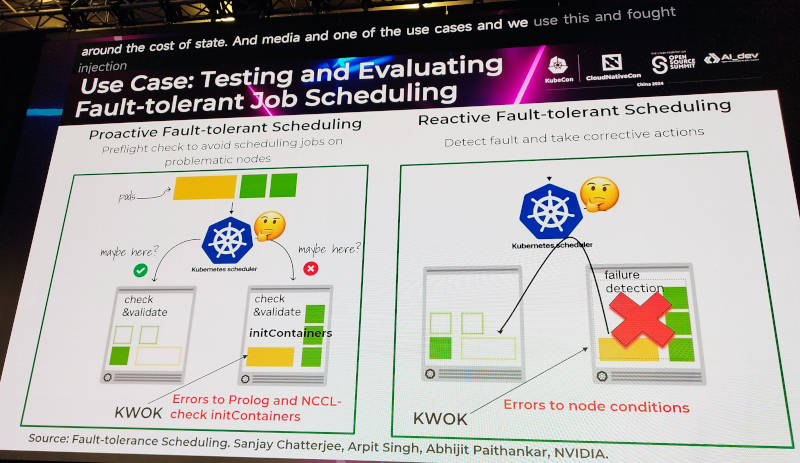
DaoCloudとNVIDIAのユースケースを紹介
DaoCloudとNVIDIAのエンジニアがそれぞれ自社内でKWOKを使っていることを紹介。その他にも関連するツールを簡単に紹介した。

DaoCloudとNVIDIAのユースケース
DaoCloudはd.runというNVIDIAのGPUクラスターを提供するサービスを持っているくらいにはGPUの経験に長けており、GPU関連のエラーが多いことをリアルに体験しているのは確実だ。そのDaoCloudのエンジニアとNVIDIAのエンジニアが揃ってKWOKを紹介したことが、このセッションのポイントだろう。
最後に今後の開発計画を簡単に紹介してセッションを終えた。

今後の計画には疑似GPU Operator、複数のKWOKの連携などが紹介された
KWOKの公式ページは以下のサイトを参照して欲しい。貴重なGPUを無駄にせずに、だからと言ってペットのように扱うのではなく、エラーを起こしても対応できるクラウドネイティブなクラスター運用を目指すエンジニアは知っておいた方が良いツールだろう。
●公式ドキュメント:https://kwok.sigs.k8s.io/
このセッションは動画が公開されていないが、スライドは以下のリンクから参照可能だ。
●セッションのスライド(PDF):Large Scale and Reliability Testing in Kubernetes using KWOK
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
