【深層分析への扉】SyslogとトラフィックFlowの活用
第3回の今回は、「Syslog」と「SNMP Trap」を比較し、Flowデータで通信の実態を可視化する方法について解説します。
1月14日 6:30
導入:SNMPに残された、もう1つの‘声’
前回では、SNMPの主流である「ポーリング」、すなわち管理者が能動的に機器の状態を問い合わせに行く手法の価値と、その限界について論じました。定期的な健康診断にも似たこの手法では「診断と診断の合間に起きた突発的なイベントを捉えられない」という課題がありました。
しかし、ここで1つ重要な補足があります。実はSNMPの広大な枠組みの中には、この課題に応えようとする仕組みが当初から用意されていました。それが「SNMP Trap」です。これは、機器が自らの判断で「異常事態が発生した」という事実を管理者に自発的に通知する「イベントドリブン(Push型)」のアプローチです。
この思想は、今回私たちが探求するもう1つの重要な水源、Syslogと非常に近い関係にあります。どちらも、機器が自らの‘声’で異常を伝える仕組みです。
では、一体なぜSNMP Trapという仕組みがありながら、私たちはSyslogという別の水源をわざわざ掘り下げる必要があるのでしょうか。この問いこそが、ネットワークの深層を理解するための新たな扉を開く鍵となります。
本稿では、まずこの2つの似て非なる技術を比較することから始め、さらに通信内容そのものを解き明かすトラフィックFlowの世界へと探求を進めていきます。
イベントという‘声’に耳を傾ける:
SNMP TrapとSyslog
導入部で投げかけた「なぜ、SNMP TrapがありながらSyslogも必要なのか」という問いに答えるため、この2つの技術の決定的な違いを、2つの側面から見ていきましょう。
違い①:データの「届け方」(信頼性)ー “はがき”vs“書留郵便”
第1にして最大の相違点は、トランスポートプロトコル、すなわちデータの「届け方」に対する考え方の違いです。
- SNMP Trap(UDP)
伝統的に、SNMP TrapはUDP(User Datagram Protocol)を用いて通知されます(ポート 162/UDP)。これは、通信の世界における「はがき」に例えることができます。住所を書いてポストに投函するだけの手軽さ(低オーバーヘッド)が利点ですが、送りっぱなし(fire-and-forget)であるため、その「はがき」が相手に確実に届いたか、途中で紛失していないかを送り主(ネットワーク機器)は関知しません。 - Syslog(TCP)
一方、Syslogは伝統的にUDP(514/UDP)が使われてきましたが、その後の拡張により、TCP(Transmission Control Protocol)を選択できるようになりました(例:514/TCPや1468/TCP)。これは、さながら「書留郵便」です。まず相手と「これから送ります」という接続を確立し(3ウェイハンドシェイク)、送ったデータが確実に届いたかを逐一確認します。もし途中でデータが失われれば、相手に届くまで再送を試みます。
ここで、ネットワークエンジニアが最もアラートを必要とする瞬間を考えてみましょう。それは、ネットワークが不安定な時、すなわち障害や輻輳(ふくそう)が発生している最中です。
UDP(はがき)という仕組みは、皮肉なことに最も通知が必要なその瞬間に、パケットロスにより最も重要な障害通知が紛失するリスクを内包しています。 対してTCP(書留)を選択できるSyslogは、ネットワークが不安定な状況下でもデータの「到達」と「順序」を保証しようと努めます。
この「信頼性」こそが、私たちがSNMP Trapだけでなく、Syslogという水源を深く探求すべき、第1の理由なのです。
違い②:データの「内容」(詳細度)ー “警告ランプ”vs“詳細な事故報告書”
信頼性に加えて、通知されるデータの「内容」にも決定的な違いがあります。
- SNMP Trap:解釈が必要な「警告ランプ」
自動車のダッシュボードに点灯する「警告ランプ」に似ています。「エンジン異常」「油圧低下」といった、あらかじめ定められた種類の異常が発生したこと(OIDで示される)を簡潔に伝えます。
例えば、インターフェースがダウンした際、SNMP Trap(linkDownTrap)が送る情報はVarbind(変数束縛)と呼ばれる、以下のような「識別子」のリストに過ぎません。ifIndex = 10105(ポートの識別番号)ifAdminStatus = up(1)(管理上の状態)- ifOperStatus = down(2)(運用上の状態)
- ここで重要なのは、
ifIndex 10105が一体「どのポート(例:GigabitEthernet0/5)」を指すのか、この情報だけでは人間には即座に判断できないという点です。これは、受け取ったSNMP Manager側がMIBという「辞書(仕様書)」と照合して「翻訳(解釈)」して初めて意味をなす、コンピュータ寄りの情報なのです。 - Syslog:人間が読める「詳細な事故報告書」
ドライブレコーダーの映像や整備士が作成する「詳細な事故報告書」に相当します。
SNMP Trapと同じ「インターフェースがダウンした」という事象でも、Syslogは以下のような人間がそのまま読めるテキスト形式で状況を克明に記録します。%LINK-3-UPDOWN: Interface GigabitEthernet0/5, changed state to down
- ここには「O2センサーが異常値を5回連続で検知後、エンジンが不完全燃焼を開始…」といったイベントに至るまでの文脈や、発生した事象の詳細が記録されます。
この「機械可読だが解釈が必要なTrap」と「人間可読で文脈が豊富なSyslog」という性質の違いこそが、2つ目の決定的な相違点です。
技術(How):Syslogメッセージの構造と設定
Syslogが豊かな物語を語れる秘密は、そのシンプルな構造にあります。メッセージは一般的に以下の3つの要素で構成されています。
- Facility(ファシリティ):メッセージの生成元を示す分類コードです。ネットワーク機器では、例えばインターフェースの状態変化(LINK)、ルーティングプロトコル(OSPF、BGPなど)といった機能単位や、管理者が任意に設定できる「local0」〜「local7」といった汎用的な分類がよく用いられます。
- Severity Level(深刻度レベル):メッセージの緊急度を示す8段階のレベルです。
Emergency(緊急事態)からDebug(デバッグ情報)まであり、管理者はこのレベルを基準に対応すべきメッセージを絞り込めます。 - Message(メッセージ本体):イベントの具体的な内容を記述した自由形式のテキストデータです。ここに、状況を理解するための最も重要な情報が格納されます。
! Syslogサーバー(192.168.1.100)を指定
logging host 192.168.1.100 transport tcp port 514
! 送信するログのレベルを'Informational'(6)以上に設定
logging trap informational/* Syslogサーバー(192.168.1.100)を指定 */
set system syslog host 192.168.1.100 any any
/* 深刻度レベルが'Error'以上のメッセージを送信する設定 */
set system syslog host 192.168.1.100 match "KERN.ERR|PFE.ERR"トラフィックFlow:‘誰が、どこへ、何をしたか’を可視化する
概念(Why):‘道路の交通量’と‘1回の配送伝票’の違い
Syslogが「何が起きたか」を教えてくれるとしても、ネットワークの主役である「通信」そのものの内容は分かりません。SNMPで分かるのはインターフェースを通過した総バイト数、いわば「高速道路全体の交通量」だけです。これでは、どの車線が、なぜ混雑しているのかを知ることはできません。
この課題を解決するのがトラフィックFlowデータです。これは、ネットワークを流れる通信を、ある種の「セッション」単位で集計したメタデータです。先ほどの高速道路の例えを続けるなら、Flowデータは個々の輸送業務を記録した「配送伝票」のようなものです。
- SNMP:「この1時間に、このゲートを1000台の車が通過した」という総量しか分からない
- Flowデータ:「品川ナンバーの配送車(送信元IP)が横浜の物流センター(宛先IP)にある『80番』という指定ゲート(宛先ポート番号)を使い、午後3時5分から15分間、段ボール50箱分の荷物(通信量)を搬入した」という、個別の活動記録が分かる
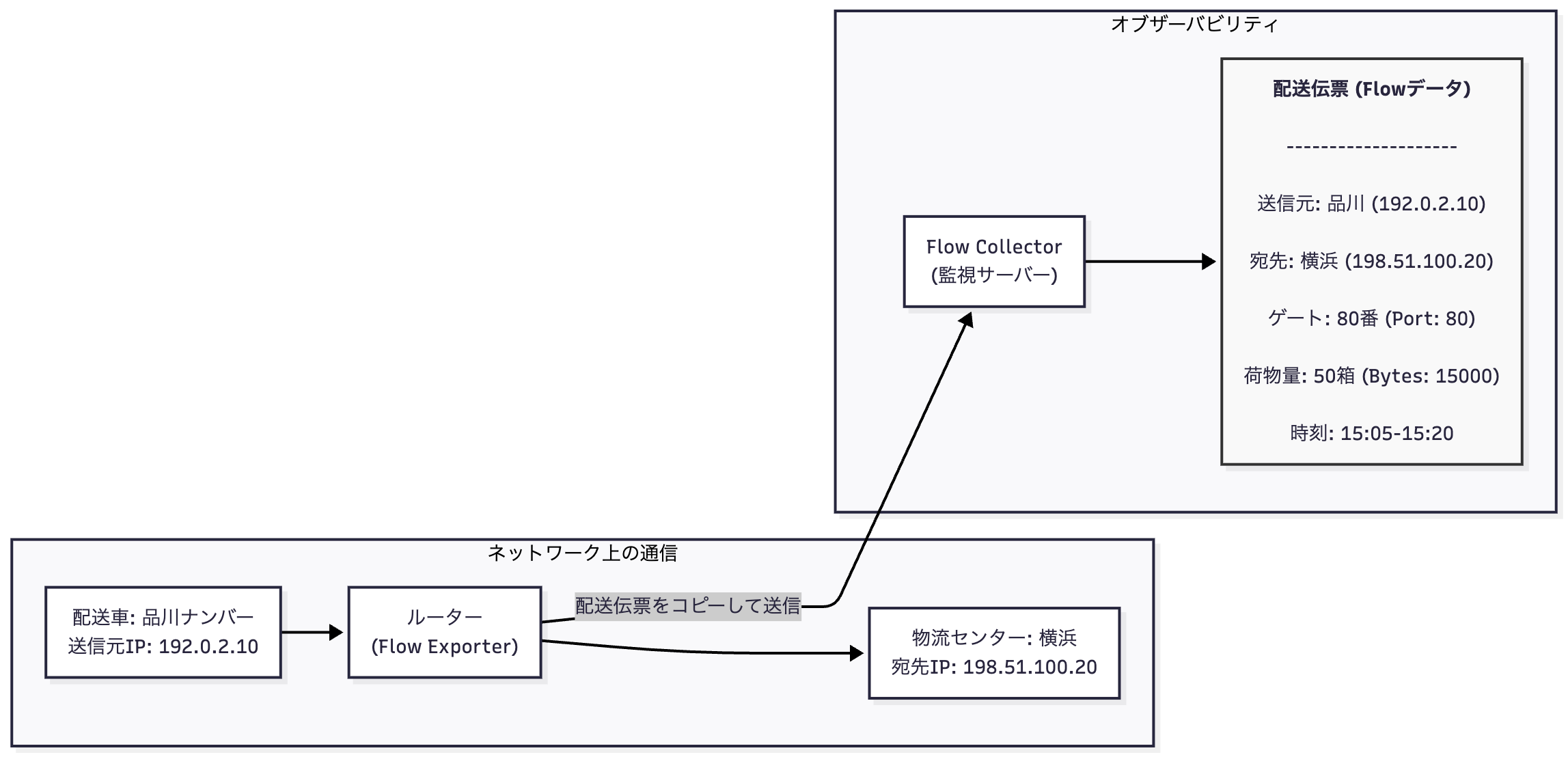
このように、Flowデータは「誰が」(送信元IP)、「どこへ」(宛先IP)、「どのサービス窓口を使い」(ポート番号)、 「どれくらいの量」(バイト数) 通信したのかを克明に記録します。ネットワーク利用の実態を明らかにする上で、不可欠な情報源なのです。
技術(How):Flowデータの主要な実装(NetFlow、IPFIX、sFlow)
トラフィックFlow技術には、主に3つの標準が存在します。それぞれが異なる思想と歴史的背景を持っています。
- NetFlow:Ciscoが開発したFlow技術の草分け的存在です。ステートフルな方式で通信の開始から終了までを1つの「フロー」として追跡し、通信終了時に集計情報を送信します。詳細で正確なデータが強みですが、機器への負荷は比較的高くなります。
- IPFIX(IP Flow Information Export):NetFlow v9を基にIETFが正式に標準化したプロトコルです。NetFlowの思想を引き継ぎつつ、テンプレートベースの柔軟なデータ形式を採用したことで、ベンダー独自の項目や新しい情報を追加しやすくなりました。NetFlowの正統進化であり、現代のFlow技術の主流と言えます。
- sFlow(Sampled Flow):ステートレスな方式で流れるパケットを一定の割合でランダムにサンプリングし、そのヘッダ情報をコレクターへ送信します。機器への負荷は非常に低いですが、データの精度はサンプリングレートに依存し、短時間の小さな通信は取りこぼす可能性があります。
設定例1:Cisco IOS-XE(Flexible NetFlow/IPFIX)
現代のCisco機器では、IPFIXに準拠したFlexible NetFlowが主流です。
! フロー情報の出力先を指定
flow exporter IPFIX-EXPORTER
destination 192.168.1.200
transport udp 9996
export-protocol ipfix
! 監視対象のインターフェースに適用
interface GigabitEthernet0/0
ip flow monitor IPFIX-MONITOR inputIPFIXの登場により、Flowデータはベンダーが独自の情報を付与できる拡張性を手に入れました。これにより、単なるIPアドレスやポート番号の記録だけではない、より深い洞察を得る道が拓かれました。その代表例がCiscoが開発したNBARとNSELです。
- NBAR(Network Based Application Recognition)
「配送伝票」だけでは、運ばれている荷物の「中身」までは分かりません。例えば、同じ「80番ゲート」(HTTPS/443) を使っていても、それがMicrosoft 365の通信なのか、YouTubeの動画視聴なのかを区別することは困難です。NBARは通信のデータパターンを解析し、この「中身」、すなわち何のアプリケーションであるかを識別するエンジンです。この識別結果をFlowデータに含めることで「Microsoft 365の通信が帯域を圧迫している」といった、より具体的な分析が可能になります。 - NSEL(NetFlow Secure Event Logging)
これは、Ciscoのファイアウォール(ASAシリーズ)に搭載されている機能で、Flowデータをセキュリティの文脈で活用するものです。通常のFlowが「通信量」を記録するのに対し、NSELは「通信が許可された」「通信が拒否された」「NAT変換が行われた」といった、ファイアウォールならではのセキュリティイベントを記録します。これは、もはや「配送伝票」ではなく、ゲートの警備員が記録する「セキュリティチェックの報告書」に他なりません。
このように、NBARやNSELといった拡張技術は、標準化されたFlowデータをさらにリッチな情報源へと昇華させます。これは、業界全体が「より深い可視性を求めている」ことの何よりの証左と言えるでしょう。
結論:多様な水源を組み合わせ、ネットワークを多角的に捉える
今回は、SNMPだけでは見ることのできなかったネットワークの深層を明らかにするための2つの重要な「水源」、SyslogとトラフィックFlowデータを掘り下げました。
- SNMP(Polling):ネットワーク機器の状態(State)を把握する定期的な健康診断
- Syslog(Event):機器で発生したイベント(Event)を記録する詳細な報告書
- Flowデータ(Flow):ネットワーク上の通信(Flow)を記録する配送伝票
これらを組み合わせて、さらにNBARのような拡張情報を加えることで、私たちはネットワークで起きている事象を多角的かつ立体的に理解し、真の「オブザーバビリティ(可観測性)」への道を歩み始めることができるのです。
ここで、読者の皆様の視座を「ネットワーク監視」から、より広範な「オブザーバビリティ」へと引き上げてみましょう。
近年、アプリケーションやクラウドネイティブの世界では、システムの振る舞いを理解するための主要なデータ型として「MELT」という4つの分類が広く知られています。
- Metrics(メトリクス/計測値)
- Events(イベント/事象)
- Logs(ログ/記録)
- Traces(トレース/追跡)
私たちが今回探求してきた3つの「水源」は、奇しくもこの分類に美しく当てはめることができます。
- M(Metrics):まさにSNMPポーリングによる定期的な「状態(State)」の計測(CPU使用率、通信量など)がこれに該当します。
- E(Events) & L (Logs):SyslogやSNMP Trapが記録する詳細な「イベント(Event)」や、その文脈を示す人間が読めるテキストデータがこれらに相当します。
- T(Traces):そして、Flowデータが記録する一連の通信(「誰が、誰と、何をしたか」)はネットワークの世界における「トレース(Traces)」、すなわち活動の追跡記録に他なりません。
このように、私たちがネットワーク機器から得られるデータソースは、それぞれがオブザーバビリティを構成する独立した重要なピースなのです。従来のSNMP(Metrics)だけを見ていてはシステムの全体像は決して掴めない。この事実こそが、本連載が「多様な水源」の探求を続ける理由です。
しかし、これまでの議論は、主にオンプレミスの世界が中心でした。次回は、その舞台をクラウドへと移します。AWS、GCP、Azureといったプラットフォームがネイティブで提供する、新たなテレメトリデータの世界を探求していきましょう。
※記載されている商標について
本記事に記載されている会社名、製品名、サービス名は、一般に各社の登録商標または商標です。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
