インデクシング速度の測定結果
インデクシング速度の測定結果
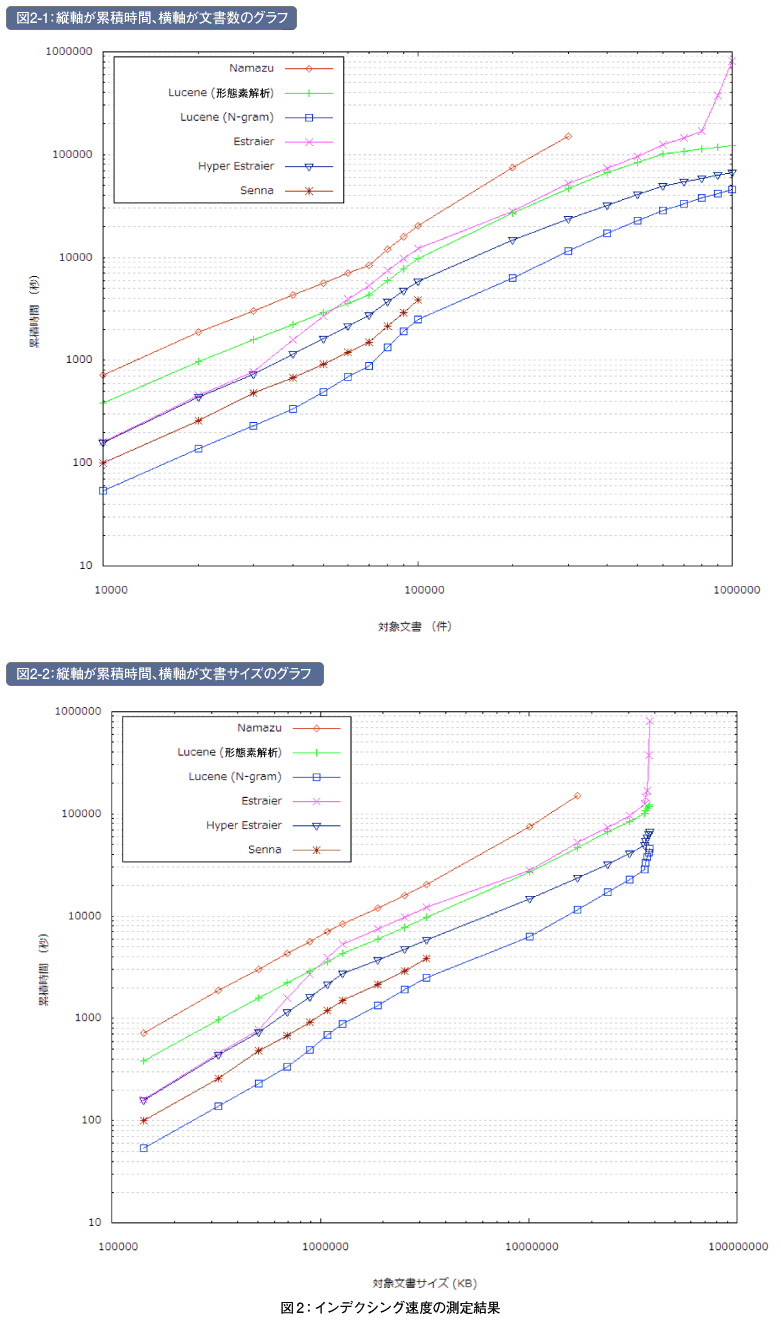
インデクシング速度の測定結果は、図2のようになりました。1つは縦軸が累積時間、横軸が文書数のグラフ(図2-1)で、もう1つは縦軸が累積時間、横軸が文書サイズのグラフ(図2-2)です。どちらのグラフも両対数グラフとなっています。両対数グラフというのは、両方の軸が対数目盛りになっているグラフのことです。今回の実験では、通常のグラフにすると文書数10万までの結果を比較するのが難しくなってしまうため、両対数グラフにしています。
今回の実験の結果、最も高速だったのはN-gramで単語分割したLuceneでした。一方、最も低速だったのはNamazuでした。
Namazuは文書数30万、Sennaは文書数10万でそれぞれ実験を中止しています。これは、どちらもそれ以上の文書を登録できなくなってしまったためです。Namazuの場合には、文書数40万にしようとしたところで未登録文書がどのファイルで何件あるかを正しく認識できなくなりました。
Sennaの場合には、文書数を166,512より多くしようとすると、メモリ確保の失敗が原因のsen_memory_exhaustedというエラーが発生し、インデックスに文書を追加できなくなりました。
インデクシング速度の測定結果の考察
横軸が文書数のグラフ(図2-1)では、いくつかのシステムで文書数7万~10万の傾きが少し大きくなっています。一方で、横軸が文書サイズのグラフ(図2-2)では、該当個所(1~4GBのあたり)に傾きの変化は見られません。
ここで次ページの図3にある文書数・文書サイズの関係のグラフを見ると、文書数7万を境に文書数の増加に対して文書サイズの増加の割合が大きくなっています。つまり、この傾きの変化は文書1つあたりのサイズが大きくなっていることが原因であると考えられます。
なお、文書数60万~では横軸が文書サイズのグラフ(図2-2)の傾きが大きくなっています。文書数60万~では文書数の増加に対して文書サイズの増加の割合が小さくなっていますので、この傾きの変化は記憶容量あたりの文書数が多くなっていることが原因であると考えられます。
Luceneは形態素解析とN-gramのそれぞれの単語分割方式で測定を行いました。1万件ではN-gramが54秒に対して形態素解析は386秒と7倍になっています。単語分割以外は全く同じテストコードを使用していますので、この差が同じ文書群を処理したときのN-gramと形態素解析との速度の差ということになります。
Estraierは文書数90万、100万のときの処理時間がそれまでに比べて大幅に増えていますが、これはインデックスの最適化に時間がかかってしまったためです。インデックスの最適化とは、インデックスサイズの縮小や検索の高速化を目的とし、インデックスのデータを統合したり並べ替えたりする処理です。
今回の実験では、インデックスの最適化処理を実装しているLucene、Estraier、Hyper Estraierについては、インデクシング後に最適化を実行しました。Estraierでは、文書数80万のときはインデクシング2時間に対して最適化3時間半だったのが、文書数100万のときにはインデクシング2時間に対して最適化に119時間もの時間がかかってしまっています。最適化中のCPU使用率を見ると、文書数80万までは10~20%だったのが文書数90万、100万のときには1%以下になっていること、次回で説明するリソース消費量の測定結果などから、原因はI/Oの負荷にあると考えられます。
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
