文書サイズとインデックスサイズ
文書サイズとインデックスサイズ
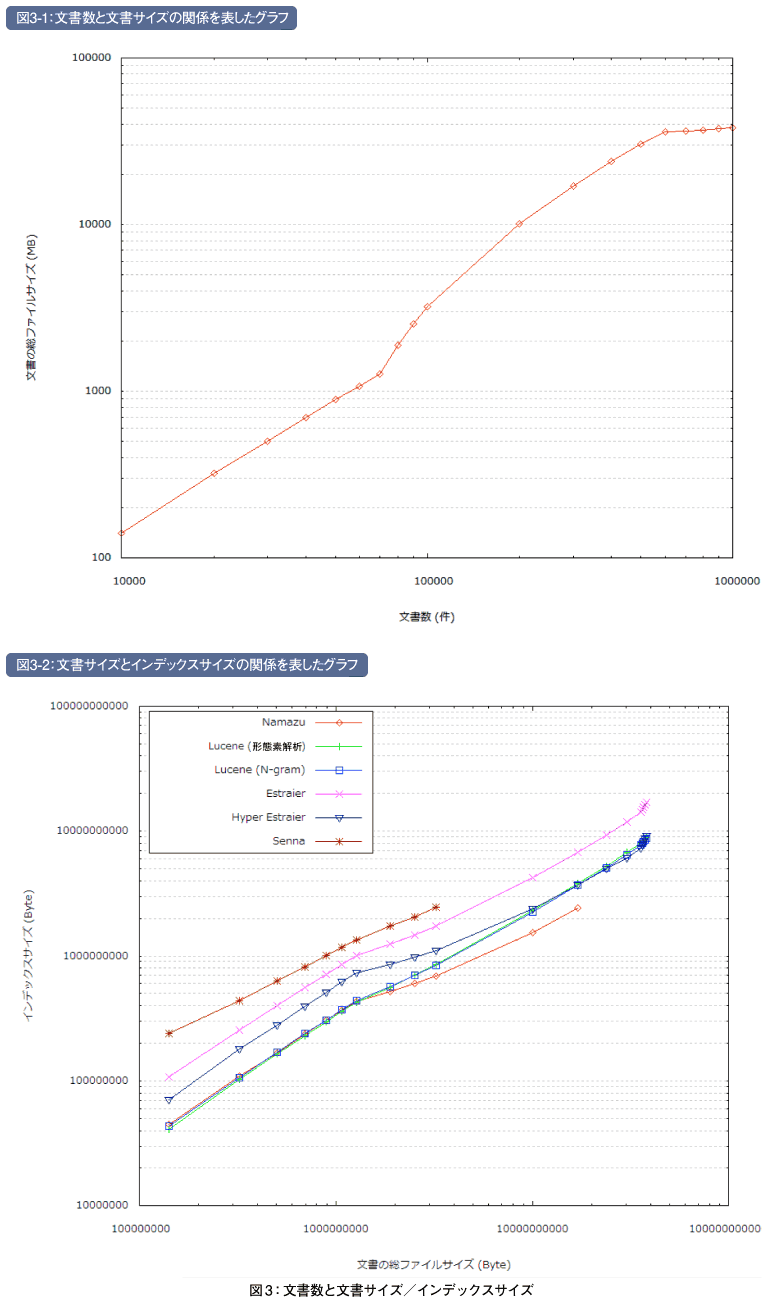
図3は文書数と文書サイズの関係を表したグラフ(図3-1)と、文書サイズと各全文検索システムのインデックスサイズの関係を表したグラフ(図3-2)です。
文書数10万の時点で比較すると、インデックスサイズが最大なのはSennaでした。また、最もインデックスサイズが小さくなるのはNamazuでした。
Sennaではインデックスにバッファファイルを含むため、文書数1万の時点からサイズは大きめになっています。文書数1万では230MBのうち130MBがバッファファイルで、それを差し引くとEstraierとほぼ同じサイズになります。しかし、文書数10万では2.3GBのうち200MBと、バッファファイルの占める割合は少なくなっていきます。
Hyper Estraierは初めはNamazuやLuceneよりサイズが大きくなっていますが、文書数7万(文書サイズ1GB)を超えたあたりから傾きが緩やかになり、文書数20万(文書サイズ10GB)からはLuceneとほぼ同じサイズとなっています。
また、Namazuも文書数7万(文書サイズ1GB)を超えてから傾きが緩やかになっています。文書数7万というのは、図3にもある通り、文書1つあたりのサイズが大きくなっているところです。
文書1つあたりのサイズが大きいというのは、サイズあたりの文書数が少ないということです。そのため、インデックスサイズの増加が緩やかになったのではないかと考えられます。
前回ではインデックスサイズは形態素解析の方が小さくなる傾向になるという図を示しましたが、今回の実験では、Luceneの形態素解析とN-gramを比較すると、文書数10万以上でN-gramの方がサイズが小さくなりました。
形態素解析のインデックスの方が、N-gramのインデックスより小さくなるというのは、登録単語数がその根拠になっています。形態素解析の単語の種類は辞書の語彙(ごい)数(と未知語の分割方法)で決まります。対してN-gramの単語の種類は最大で文字の種類のN乗となります。
今回の実験のまとめ
インデクシング速度の比較では、最も高速なのはN-gramで単語分割したときのLucene、最も低速なのはNamazuでした。NamazuとSennaではそれぞれ一定以上の数の文書をインデクシングすることができませんでした。インデックスサイズの比較では、最もサイズが小さいのはNamazu、最もサイズが大きいのはSennaでした。
次回は各全文検索システムの検索速度の比較実験を行い、解説する予定です。
なお、本記事に関して電気通信大学 尾内理紀夫氏と林貴宏氏からいただいたご支援、ご協力に深謝します。
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
