| ||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||
| 構造化および非構造化データを仮想統合する IBM DB2 OmniFind | ||||||||||
先に述べた事例のような爆発的に増加する営業情報、顧客情報を仮想的に統合する強力なツールの1つが、イントラネット向けの検索ポータル製品「IBM DB2 Information Integrator OmniFind」(以下、OmniFind)だ。  図2:IBM DB2 Information Integrator OmniFind この製品はファイルサーバやメールサーバ、BI環境に分散している各種の文書ファイルやレコードから、テキストデータを抽出し索引付けを行う。ユーザが検索ポータルからキーワードを指定すると、合致する索引データから情報の格納先(URL)を引き出し検索結果として表示する。 これにより、ユーザは検索ポータルから検索された結果のリンクをクリックするだけで、目的の情報がどこに格納されていて、どのアプリケーションを使ってアクセスすればよいかを意識することなく直接参照することができる。 サポートされるデータ形式は、Word、Excel、PDF、ZIPといった一般文書からIBM Lotus Notesのデータベース、Webサイトやニュースグループ、DB2やOracle、SQL ServerなどのRDBMSのレコードまで幅広く網羅している。よって、企業内に存在するほとんどの情報を検索対象にすることが可能だ。 さらに一部のBI製品との組み合わせにおいて、OmniFindから過去に作成されたパイプラインや売上予測、ディスカウント分析などの営業活動に関するレポートやチャート群を検索し、最新のデータを含む形で公開することもできる。 また静的/動的ランキング機能による検索結果表示の優先度の制御や、「UIMA(※注1)」フレームワークのテキスト分析機能によって高度な言語識別・文脈判断が可能なため、重要なデータを効果的にユーザに提供することができる。しかも、1,000万件にも上る大容量データソースであってもテキスト情報を高速に収集するために拡張性の高いアーキテクチャを採用している。 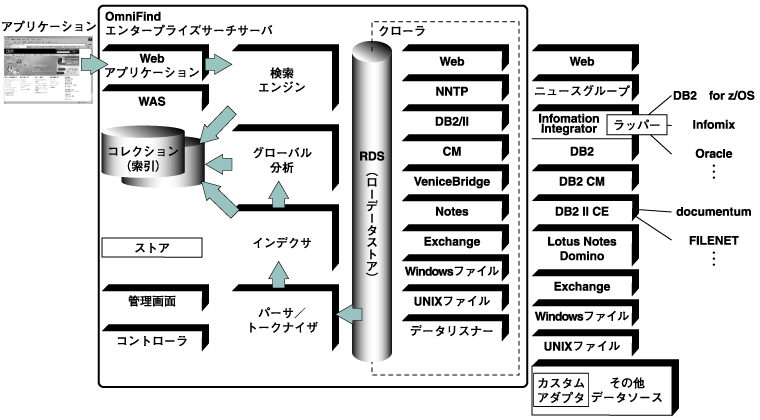 図3:OmniFind アーキテクチャ概念図 (画像をクリックすると別ウィンドウに拡大図を表示します) ※注1:Unstructured Information Management Architecture(非構造化データ検索技術))。IBMが開発した非構造化データを検索するためのアーキテクチャ。 | ||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||
| ||||||||||
| ||||||||||
-
-
連載


新着記事
焦りは禁物?「特化」の前に「汎用」を。エクサウィザーズが語る東海製造業における生成AI成功の秘訣 7月16日 6:30 SUSE、インフラのレジリエンスとオープンソースAIで日本のDXを加速——ベンダーロックインからの脱却を支援 7月16日 6:20 「HAMi」でKubernetes上のGPUメモリ分離の仕組みを理解し、共有を試してみよう 7月15日 6:30 「C/C++」の「RayLib」でコンソールゲーム「Color」を開発してみよう 7月15日 6:30 Gartner、エージェント型AIによってエンタープライズ・アプリケーション向け支出の2,340億ドルがリスクにさらされるとの見解を発表 7月14日 6:30