全文検索機能を試すサンプルを作成しよう!
Hibernate Searchのサンプルプログラム今回は早速、Hibernate Searchを使ったプログラムを作成してみよう。
2007年11月20日 20:00
Hibernate Searchのサンプルプログラム
今回は早速、Hibernate Searchを使ったプログラムを作成してみよう。
作成するプログラムはある会社で使われる社員検索システムとする。このシステムでは、社員が相互に趣味や得意分野などの「タグ」をつけられるように なっており、検索時は「タグ」で社員を検索できるようにする、というものである。また今回のサンプルアプリケーションでは、アプリケーションサーバを利用 せずにスタンドアロンのJavaアプリケーションとして実装している。
このシステムでは図1のようなEmployeeクラスを用いることとし、永続化はJBoss Hibernateを通じてEMPLOYEEテーブルに行うものとする。
以降では、プログラムコードの一部を掲載しながら説明してく。プログラムの全体および必要なライブラリは下記のWebサイトにある「Think IT記事」の「Hibernate Searchで全文検索システム構築」からダウンロードしていただきたい。
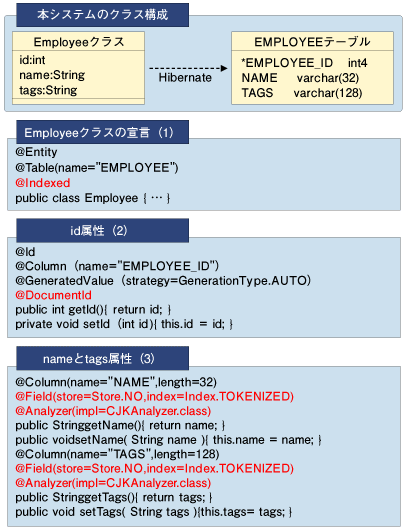
図1:本システムのクラス構成とソースコードサンプル
Employeeクラス
まずはビジネスオブジェクトとなるEmployeeクラスを実装する。Employeeクラスの宣言部分はアノテーションを用いて図1の(1)のようになる。黒字部分がJBoss Hibernate、赤字部分がHibernate Searchのアノテーションとなる。
@Indexedは、このクラスがLuceneのDocumentとして検索インデックスに登録される対象であることを示す。
次にid、nameおよびtagsの各属性のソースコードをみてみる。まず、id属性は図1の(2)のようになる。Employeeのプライマリキーとなるidには、検索インデックスに対して@DocumentIdを指定するだけでよい。この指定により、RDBのレコードとLuceneの Documentの正確なマッピングが行われるようになる。
nameとtags属性は図1の(3)ようになる。@Fieldでその属性がLuceneのFieldとなることを示している。
@Fieldでは、storeでそのFieldを文字列情報として登録する(Store.YES)か、しない(Store.NO)かを指定している。また、indexで索引付け時にAnalyzerを使用する(Index.TOKENIZED)か、しない(Index.UN_TOKENIZED) かも指定する。
なお、索引付けしないという選択も可能で、その場合は「index=Index.NO」と指定すればよい(索引付けしないとそのFieldでは検索 できなくなる)。さらに、Index.TOKENIZEDを選択したときは@Analyzerで使用するAnalyzerクラスを指定する。
次に、HibernateUtilクラスについて解説する。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
