はじめに
前回は、データマネジメントを体系化したDMBOKの概要と、その中でも特に重要性が高まっているデータ統合が解決すべき課題について説明しました。今回は、データ統合の実現プロセスやパターン、さらには利用されるツールなどについて説明します。
データ統合の実現プロセス
データ統合の実現プロセスは、計画と分析、設計から開発へと至る一般的なシステム開発プロセスに従いますが、各フェーズでの作業項目のなかで、データリネージ(組織内でのデータの流れ)の文書化、およびデータオーケストレーション設計からデータフローの開発に至る一連の作業は特に重要であり、特徴的なものと言えます。

図1:データ統合の実現プロセス【出典】ITR
計画と分析フェーズでデータリネージの文書化を行うことで、組織内でのデータの動的な流れが把握できます。文書化の内容には、組織内でのデータの取得、作成、移動、変更から最終的なデータの利用方法が含まれます。また、データリネージの文書化により、データフローが変更された際の、既存のデータ収集および加工処理に与える影響を分析できるようになります。さらに、現在のデータフローに存在する不要な処理や同じ機能を持つ処理の重複を発見し、データフローの効率化や改善を行うこともできます。
文書化されたデータリネージの情報を基に、設計フェーズではデータオーケストレーション設計が行われます。データオーケストレーションとは、データ統合を行う一連の処理の開始から終了までの流れのことですが、その処理方式はバッチ型、イベント駆動型、リアルタイム型の3種類に分けられます。バッチ型は一定の周期や予定された時間に起動され、イベント駆動型は新規データの発生やデータの更新をきっかけに起動されます。リアルタイム型では発生したデータはすぐに処理されます。
データオーケストレーション設計の結果を基に、開発フェーズではデータフローが実装されます。データフローの実装に利用されるツールについては後述します。
データ統合の実現パターン
従来のシステム間連携の実現手法としては「ポイント・ツー・ポイント」モデルが一般的です。このモデルでは、データソースとなるシステムの数が増加したり、さらに1つのデータソースから多数のターゲットシステムにデータを提供するようになると、インタフェースの数が爆発的に増えることになります。インタフェースの増加は、移動するデータ量を増大させるだけでなく、論理レベルでのデータオーケストレーションおよび物理レベルでのデータフローを複雑にします。したがって、「ポイント・ツー・ポイント」モデルではデータの移動と統合プロセスを確立し、データソースの追加に要するコストを最小限にすることは難しいと言えます。
そのため、多数のソースシステムとターゲットシステムの連携には「ハブ&スポーク」モデルが適しています。「ハブ&スポーク」モデルでは、ソースシステムとターゲットシステムは直接ではなく、中央のデータハブとなるシステムを介して連携するため、インタフェースの数を最少にできます。
例えば、データソースを1つ追加する場合、「ポイント・ツー・ポイント」モデルではデータを提供する必要のある全ターゲットシステムの数のインタフェースを開発する必要があります。しかし「ハブ&スポーク」モデルでは、データハブを対象としたインタフェースを1つ追加するだけで良く、ターゲットシステムとデータハブ間のインタフェースには変更が発生しません。結果として、既存のデータオーケストレーションおよびデータフローへの影響と発生するコストを最小限にとどめることができます。
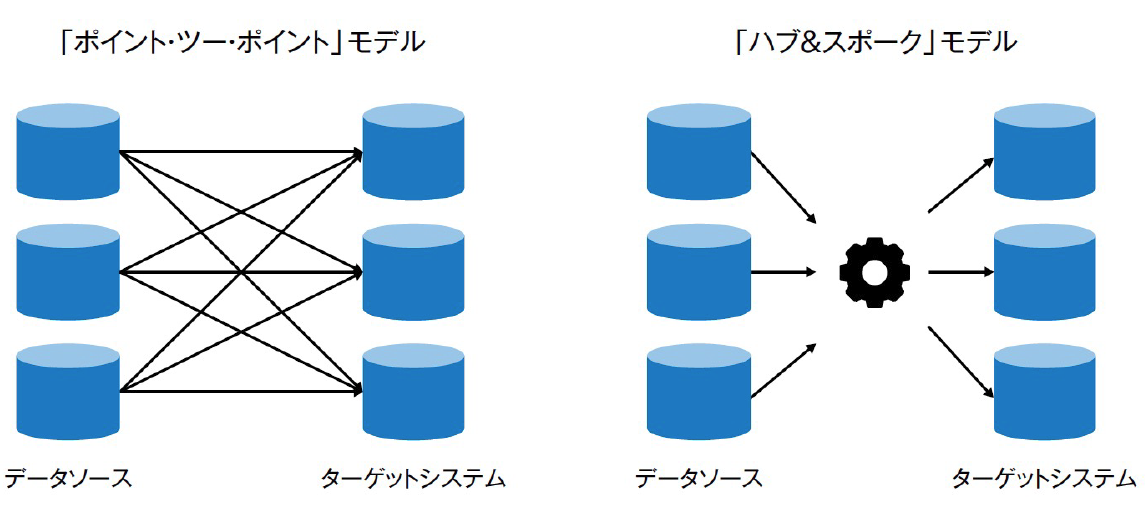
図2:データ統合の実現パターン【出典】ITR
データ統合で利用されるツール
「ハブ&スポーク」モデルでのデータフローの実装に利用されるツールにはETL(Extract/Transform/Load)ツール、データフェデレーション・ツール、EAI(Enterprise Application Integration)ツールがあります。
ETLツールは、ソースシステムからデータを抽出し、データ統合に必要な変換を行い、ターゲットシステムにデータをロードする一連のETL処理を実行します。同ツールはDWH構築に使用されることが多いですが、これは複数のソースシステムと単独のターゲットシステムから構成される「ハブ&スポーク」モデルと言えます。
ETLツールによるETL処理が物理的に実行されるのに対して、データフェデレーション・ツールは仮想的にETL処理を実行します。ターゲットシステムへの物理的なデータの格納は行われず、データへのアクセスが発生したときに対象となるデータが、その都度ソースシステムから抽出されます。そのため、アクセス頻度の少ないデータに限定して使用される場合が多いです。
EAIツールは「ハブ&スポーク」 モデルでのAPIを介したアプリケーション間連携を可能にします。ETLツールによるETL処理がバッチ型で実行されるのに対して、EAIツールを使って実装されたETL処理はソースシステムでのデータの追加や更新をきっかけに起動するイベント駆動型で実行できます。
データフローの実装においてリアルタイム性が要求される部分には、メッセージ交換による非同期な連携を可能にするESB(Enterprise Service Bus)やルールベースでリアルタイム処理を行うCEP(Complex Event Processing:複合イベント処理)が利用される場合もあります。
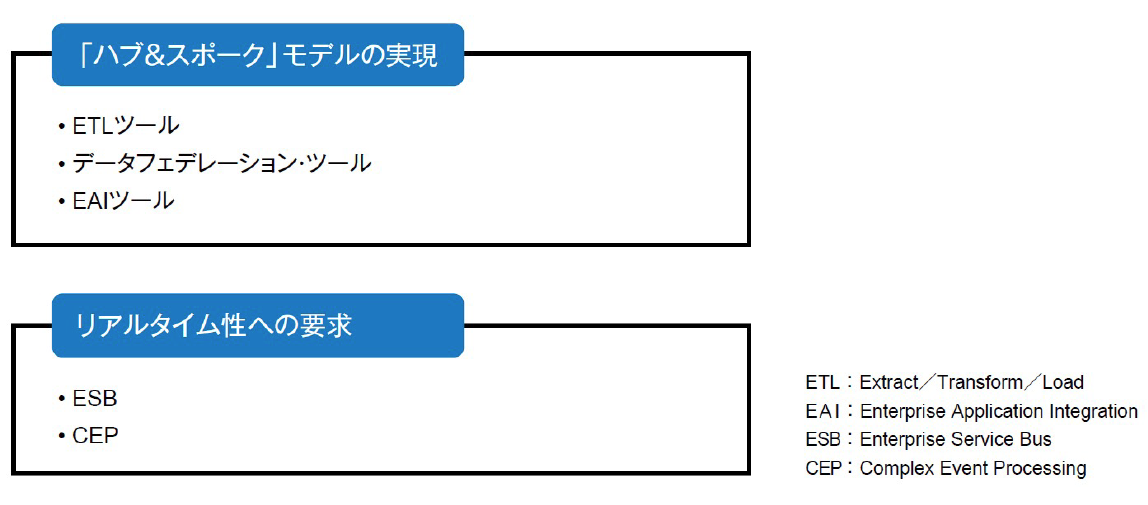
図3:データ統合で利用されるツール【出典】ITR
データ統合の評価基準
データ統合の運用段階では、データ統合の実現度合いを評価する必要があります。その際の基準となるのがデータ可用性、データの量と速度、開発・管理コストの3項目です。
データ可用性は、必要なデータが必要なときに利用可能であるかの評価基準であり、基本的にはシステムの稼働率が評価基準となります。ただし、データ統合の実現パターンや利用するツールによっては、システムの稼働率の算出方法が異なる場合があるので注意が必要です。
データの量と速度も重要な評価基準です。データ量にはソースシステムからターゲットシステムに移動されたデータ量、ETL処理で変換された量、利用者からアクセスされたデータ量などの複数の評価基準が存在します。速度の評価基準には、レイテンシが使用されます。レイテンシとは、ソースシステムでデータが生成されてからターゲットシステムでデータが利用可能になるまでの時間です。バッチ型データフローとイベント駆動型データフロー、あるいはリアルタイム処理が実装された部分などでレイテンシの値は大きく異なるため、データフローの実装形態に合わせて異なる評価基準を設定する必要があります。
データ統合の開発・管理コストで最も重要な評価基準は、データソースの追加コストです。一般的な開発・運用コストも評価基準として設定すべきですが、これらはシステムの機能や性能とトレードオフの関係にあります。

図4:データ統合の評価基準【出典】ITR
おわりに
今回は、データ統合の実現プロセスやパターン、さらには利用されるツールなどについて説明しました。次回は、データマネジメント高度化ステップについて説明します。
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
