はじめに
前回は、DX時代のデータ活用のトレンドと3大クラウドベンダのデータ活用サービスの概要を説明した。
今回のテーマであるIoTデバイスやWebアプリケーションが生成するストリームデータの処理は、従来型のデータウェアハウス(Data Warehouse)とは大きく異なる特性がある。そこで今回は、各社のクラウド・サービスを理解し、比較するための基礎知識として、以下の項目を説明する。
- データウェアハウスとデータレイク(Data Lake)の違い
- バッチ処理とストリームデータ処理の違い
- データ分析で知っておきたいこと
データウェアハウス、データレイクとは何か
データ活用と聞いてデータウェアハウスやビジネスインテリジェンスツールを思い浮かべる人も多いだろう。また近年はデータレイクという用語も登場している。特に、データウェアハウスとデータレイクは大きく異なるものなので、注意したい。
データウェアハウスとは
データウェアハウスを提唱したのは1990年代のビル・インモン氏だ。以前から、企業では販売管理システムや製造管理システムなどの基幹系システムでデータベースを使用していた。しかし、これら基幹系システムのデータを今後の分析に役立てようとすると以下の問題が発生し、せっかくデータがあっても活用できなかった。
- システムが別でコード体系も異なるため、システムをまたがった分析ができない
- 分析には長期間の過去データが必要になるが、RDBMSが使用するストレージは高価なため、過去のデータがバックアップにあり、簡単にアクセスできない
- 明細データから集計データを算出するのに時間がかかる
そこで、基幹系システムのデータベースとは別に「マネジメント層の意思決定支援のため、目的別に整理統合され、時系列で編成された更新しないデータの集合体」というコンセプトで提唱されたのがデータウェアハウスだ。
このような経緯で誕生したことから「データウェアハウスは目的志向で作られている」と言える。つまり分析担当者が利用しやすい形にデータを加工して格納されている。
既存のデータベースのデータをETLツール「Extract(抽出)」「Transform(変換)」「Load(ロード)」を使い、整理統合して構築する。長期間データを保持することが多いので、データ量削減や分析高速化のため、あらかじめ集計データとして保存することも多い。
以下に、データウェアハウスの概念図を示す。
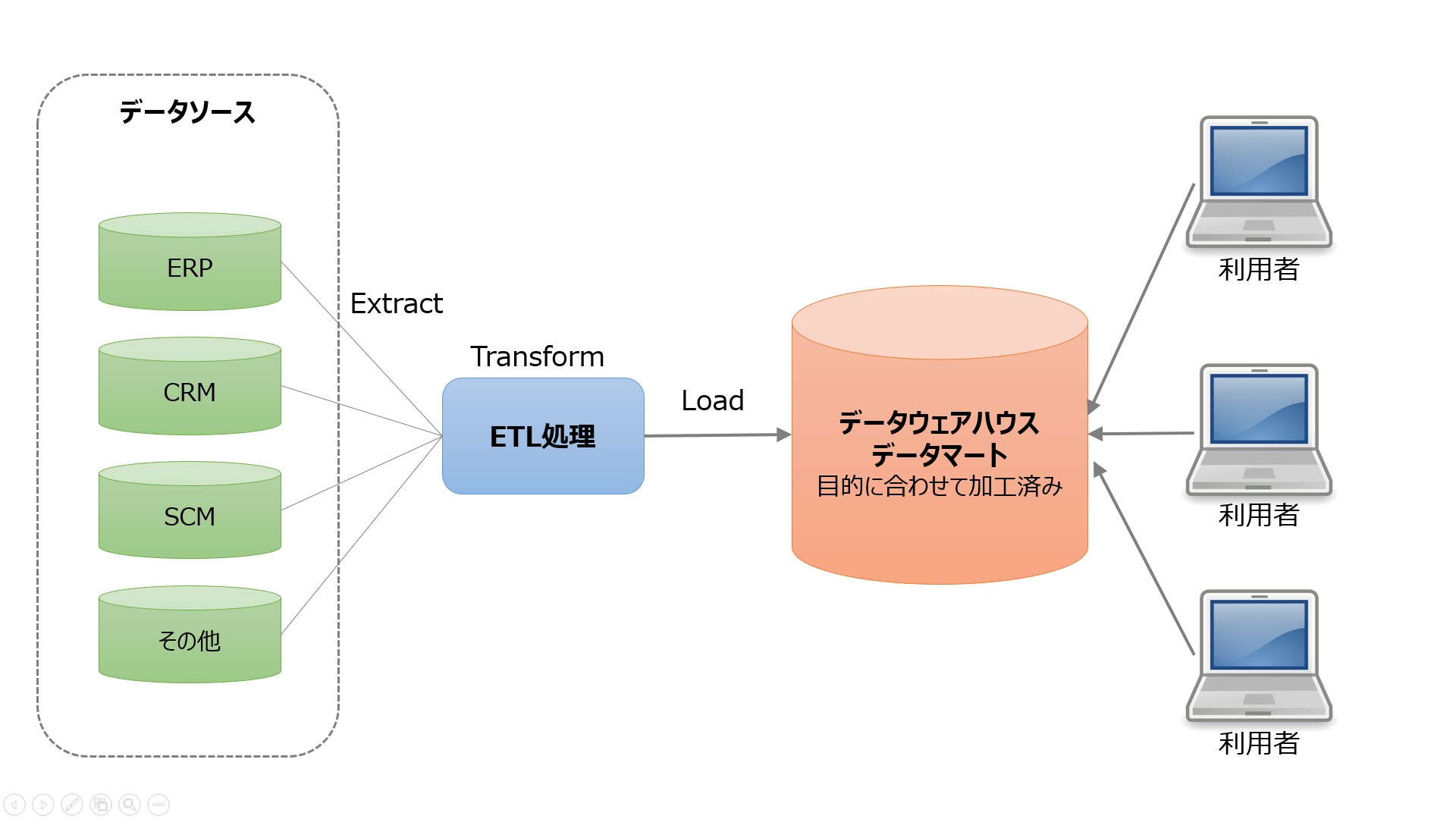
RDBMSなどの一般的なデータベースとの大きな違いは分析に特化していることだ。データウェアハウスの格納先としてRDBMSを使うこともあるが、検索に特化した専用のデータベースシステムを使うことがほとんどだろう。各クラウドサービスでも、データウェアハウスは「Amazon Redshift」や「Azure Synapse Analytics」「Google BigQuery」など専用のサービスが用意されている。
データマートとは
データウェアハウスから派生したものとして、データマート(Data Mart)がある。初期のデータウェアハウスは小型であったが、コンピューティングの進化とともに、企業全体のデータを蓄積するセントラル・データウェアハウスへと巨大化していった。
ところが、各部門やグループで利用するには、自分たちに必要のないデータが多すぎて使い勝手が悪い。そこで、データウェアハウスから自分たちが使用する必要なデータだけを切り出して加工したものがデータマートだ。
データマートという用語は、データレイク時代でも使われている。データレイクからデータを切り出し、自分たちが利用しやすいように加工・整形したものを指す。
データレイクとは
ビッグデータ時代になって注目されるようになったのがデータレイクだ。データレイクとは、さまざまなデータソースから集めた多種多様なデータを、未加工もしくは最小限加工して一元管理できるリポジトリである。
データレイクが必要になった背景
データレイクが必要とされるようになったことには理由がある。長らく使われてきたデータウェアハウスだが、現代のようなIoT/ビッグデータ時代になると課題が出てきたからだ。その代表的なものを説明する。
データ量の圧倒的な増加
企業内のデータが爆発的に増加している。従来はシステム開発の見積時に「データ量は年XX%増加」としてストレージを見積もっていたが、DXで使用するようなデータは見積もりが難しく、そのサービスが当たったときには当初想定した数百、数千倍になることも珍しくない。
またデータウェアハウスで使用するハイエンドストレージは高価で、システム的に拡張の限界もある。ペタバイトスケール(テラバイトの1024倍)までいかなくても、その手前で費用的・システム的な限界を迎えることが多い。
データの多様化
従来はリレーショナルデータベースで扱っていた行と列で表せる「構造化データ」だけで間に合っていた。しかし、インターネット経由で多種多様なデータを取得できるようになると、CSVやJSONなどの「半構造化データ」、EメールやSNS、画像データ、ドキュメントファイルなどの「非構造化データ」なども扱える必要がある。
ニーズの多様化
従来のデータウェアハウスが連携する基幹系システムはライフサイクルが長く、システムの変動も少なかった。ところが、近年のビジネス環境は格段に変化が早くなり、特にインターネット関連の分析ニーズはめまぐるしく変化している。
従来のデータウェアハウスは目的志向でデータを蓄積していた。ニーズが変化して別の視点で分析しようとしても、すでにデータは加工済みで対応できないことがあった。
そのため、分析対象のデータは未加工の生データもしくは最低限の加工を施して保存し、実際に利用するときに目的に応じて加工するほうが変化に強い。
技術の変化
ビッグデータやAIなど、DX関連の世界は技術の進化が早い。これらの世界ではOSSを利用することが多く、数年でメジャーバージョンアップが発生し、もしくは淘汰されていく。またAIなど分析自体のテクノロジーの進化も著しい。従来のシステム更改(5年前後)のタイミングでは、最新技術をキャッチアップすることが難しくなってきている。
データレイクの機能
これまで説明してきた課題を克服するため、データレイクには次の機能が求められる。
さまざまなデータを一元的に蓄積
従来の構造化データだけでなく、JSONや画像データなど半構造化/非構造化データを事前のスキーマ定義なしに何でも放り込める。このとき、データウェアハウスの「目的志向で加工済み」の課題を踏まえ、保存するデータは生データもしくは最低限の加工を施したデータであることが望ましい。また、レポーティングや高度な解析、機械学習などで変換されたデータを格納することも多い。
さまざまなデータを格納しているので、格納済みデータに対して、リアルタイムもしくは迅速にアクセスできるような仕組みがあることが望ましい。一般にはRESTやSQL等が用いられることが多い。このような標準的な入出力方法を提供することで処理と蓄積の分離が図れ、変化しやすい「処理」の部分を柔軟に変更できる。
利用者によって見たいものは異なる。蓄積と処理を分離することで、次のようなさまざまなニーズに応えられる。
- ビジネス部門:ExcelやPower BIを使いたい
- 分析部門:TableauなどのBIツールを使いたい
- マネージメント層:GrafanaやRedashのようなWebダッシュボードを見たい
- 分析担当者:Jupyter Notebookを使いたい
安価であること
具体的なストレージとしては、オブジェクトストレージやHadoopなどが使われることが多い。従来のハイエンドストレージと比べて安価であるだけでなく、クラウドサービスによってはイレブンナイン(99.999999999%)の耐久性を持つものもある。企業のセントラルリポジトリとして使用するため耐久性は重要だ。
サイズ制限がないこと
必要なデータ量を見積もるのは極めて困難だ。オブジェクトストレージはサイズ制限がなく、従量制で課金されるので、もっとも適しているといえる。
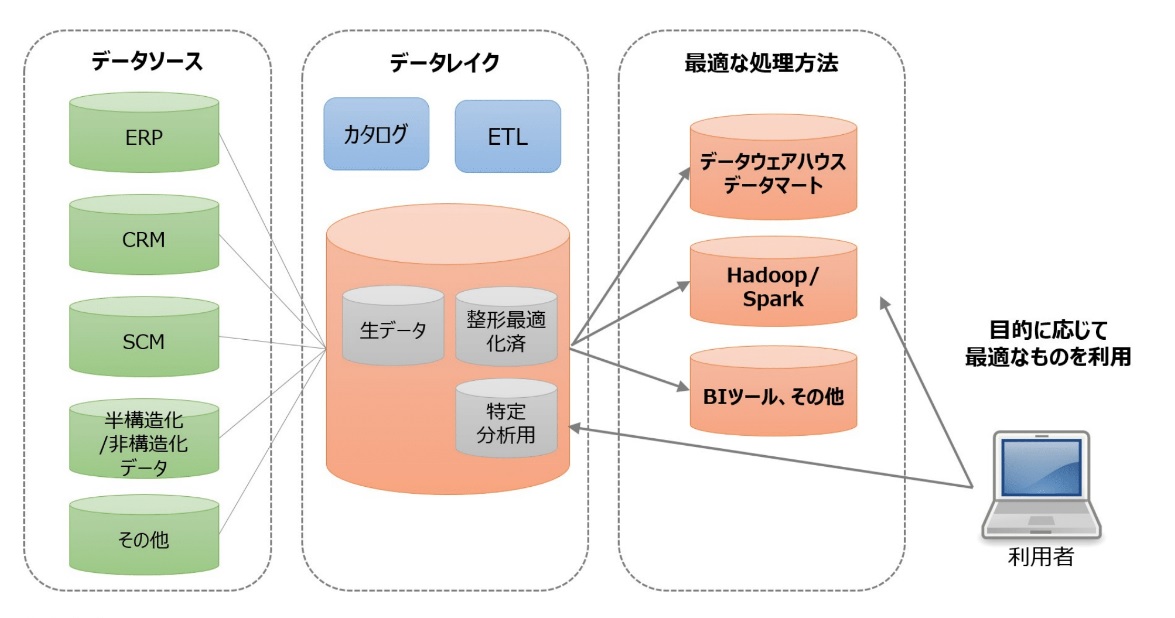
データレイクとデータウェアハウスの違い
データレイクとデータウェアハウスの違いを下表にまとめた。どちらが優れているというものではなく、用途に応じて使い分けることが重要だ。データレイクには加工前の生データを蓄積する。特定の目的に特化していないため、さまざまな用途で利用できる。
その代わり、実際に分析するには生データのままでは扱いづらい。そこで分析したいデータをデータレイクから抽出・変換し、データウェアハウスやデータマートへ切り出して利用する。
| データレイク | データウェアハウス | |
|---|---|---|
| データソース | さまざま | ビジネスアプリケーションが多い |
| データ種別 | 構造化データと非構造データが混在 | ほとんどが構造化データ |
| データ加工 | 生データもしくは文字コードや日付など最低限の加工 | 使用目的に応じて加工済み |
| データ品質 | クレンジングされているとは限らない | クレンジングされている |
| 格納先 | オブジェクトストレージやHadoop | データベース |
| おもな利用者 | データサイエンティストなどデータ分析に関わるメンバー | 事業部門などデータを活用するメンバー |
バッチ処理とストリームデータ処理
従来のビッグデータ分析では過去データから現在を理解・分析し、将来的に打つべき施策の検討に役立てていた。大量の過去データを分析するため、バッチ処理として実施していた。
ところがIoTデータやWebアプリケーションのログなどはデータが絶えず発生し、止まることなく永遠に発生し続ける特性を持っている。このようなデータを「ストリームデータ」と呼び、ストリームデータをリアルタイムに扱う技術を「ストリームデータ処理」と呼ぶ。
下表はバッチ処理とストリームデータ処理を比較したものだ。
| バッチ処理 | ストリームデータ処理 | |
|---|---|---|
| 入力データの特徴 | 有限 | 無限 |
| 処理の実行時間 | 一時的 | 永続的(短い処理の繰り返し) |
| データ範囲 | データセット内の全部もしくは大部分に対する操作 | 特定時間帯のデータもしくは直近のデータに対する操作 |
| データサイズ | 大きなデータバッチ | 少数のレコード |
| パフォーマンス | レイテンシは数分から数時間 | レイテンシは数ミリ秒から数分 |
| 分析 | 複雑なクエリー | シンプルなクエリーや集計 |
ストリームデータとストリームデータ処理
ストリームデータとストリームデータ処理について、もう少し詳しく説明しよう。ストリームデータは以下の特性を持っている。
- 継続的にデータが発生する
- データが時系列に発生し、永遠に増大し続ける
- ほとんどはキロバイト単位の小さなサイズ
このようなストリームデータの利用例としては以下のようなものがある。応用範囲は広く、数多くのシステムで利用されている。
- 交通情報をモニタリングし、渋滞情報を表示する
- Webアプリケーションのリコメンデーション
- 不正アクセス検知
- 工場や農業のIoTセンサーを使ったモニタリング
なお、言葉は似ているが、映像や音楽などを配信するストリーミングとは異なることに注意したい。
テレメトリデータとは
ストリームデータ処理の話でよく出てく言葉が「テレメトリデータ」だ。もともとは遠隔地のセンサーや計測機器から送られてくるデータのことを指すが、現在は意味が拡大され、各種デバイスやアプリケーションから継続的に送られてくる稼働データも含まれる。
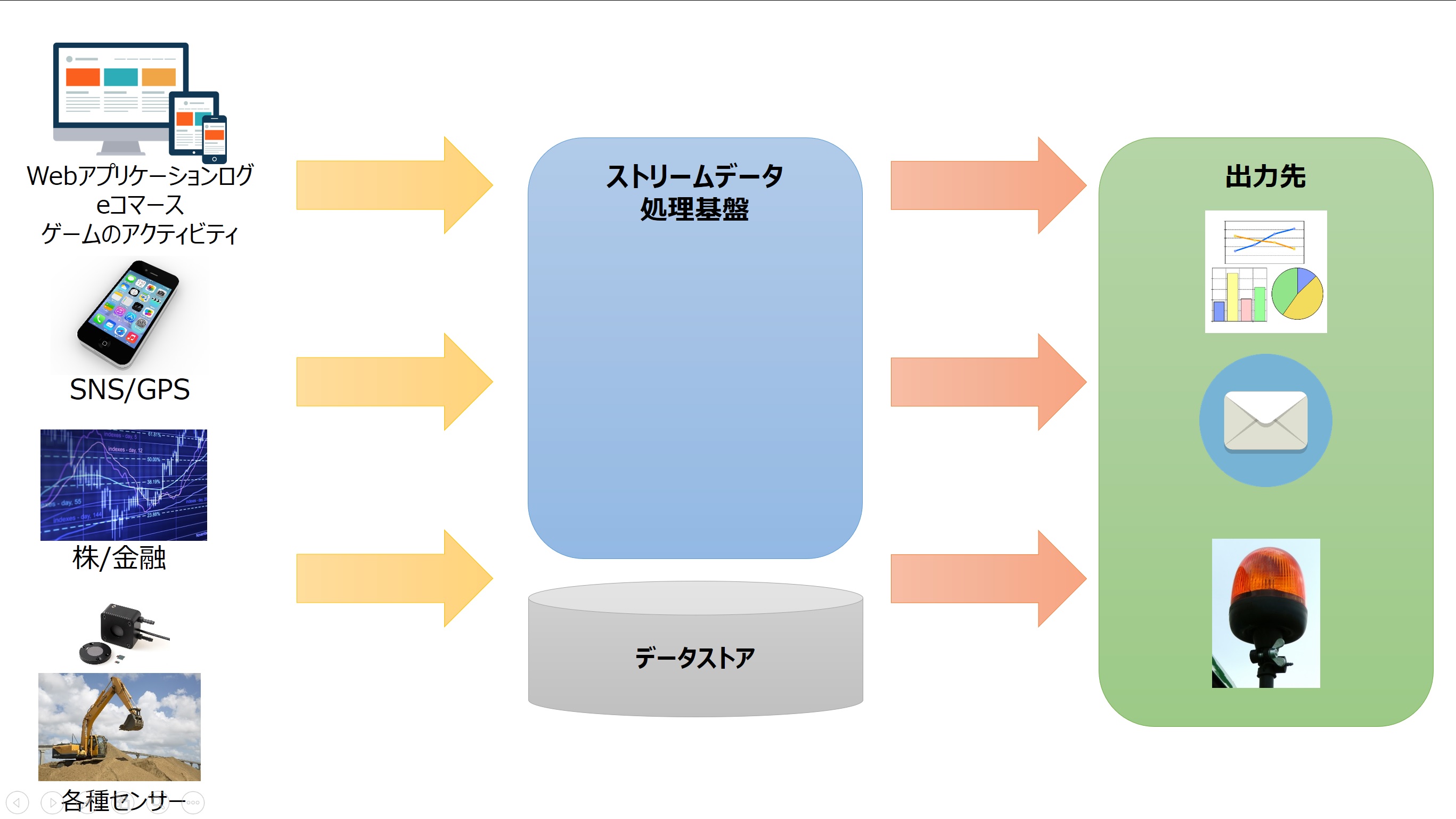
これまで説明してきた性質を持つことから、ストリームデータ処理では次のような特性が求められる。
- 無限に発生し続けるデータを処理
- 処理が永続的に継続
- 低遅延、狭いタイムウィンドウに対する処理
しかし、大量データをリアルタイムもしくはリアルタイムに近い時間で処理することは簡単ではない。そのため、従来は短いバッチで処理することが多かった。だが近年は技術の進歩によって多くのことが可能になってきた。
ここで強調したいのは、冒頭で説明したとおり、バッチ処理とストリームデータ処理に求められる技術は違うということだ。実際にシステムを構築するときは、必要な技術や特性を理解してサービスを選択し、組み合わせて利用する必要がある。
ビッグデータ処理パターンと
ラムダアーキテクチャ
先ほどは典型的な処理方式として、バッチ処理とストリームデータ処理を説明した。実際のビッグデータ処理では、あと一段細分化され、以下の3つの処理パターンがある。データの種類や用途に応じた使い分けが必要だ。
| バッチ処理 | インタラクティブクエリ (アドホック) | ストリームデータ処理 | |
|---|---|---|---|
| 実行タイミング | 定期的な実行や利用者の任意実行 | 定期的な実行や利用者の任意実行 | 常時連続実行 |
| 処理対象 | 保存済みデータ | 保存済みデータ | 無限に発生するストリームデータ |
| 実行時間 | 分~時間 | 秒~分 | ミリ秒~数秒 |
| 適用事例 | ETL、レポーティング、機械学習モデル構築 | BI、データ分析、データ探索 | 異常検知、レコメンド、ダッシュボード表示 |
そして今回は説明しないが、ストリームデータ処理の話になると、よく登場する用語として「ラムダアーキテクチャ(Lambda Architecture)」や「カッパアーキテクチャ(Kappa Architecture)」がある。これらはストリームデータ処理基盤を構築するときのアーキテクチャパターン(デザインパターン)として提唱されたものだ。現時点で、どれが優れているとは言えず、1つの考え方として捉えてほしい。またAWS Lambdaとは、まったく関係ないので注意したい。
データ分析で知っておきたいこと
これまでインフラにフォーカスして書いてきたが、実際に成果を出すにはデータサイエンスやデータアナリティクスといった分析が欠かせない。さらにはビジネスを理解した事業部門との協調も必要だ。いずれも専門性が高いので説明しないが、DXに関わるインフラエンジニアならば理解しておきたいキーワードを説明する。
データ利活用のステップ
次図はさまざまな企業でデータサイエンス・アドバイザーをしているMonica Rogati氏がブログに投稿したものだ。AIやディープラーニングを頂点に、そこに至るまでに必要なステップが記載されている。
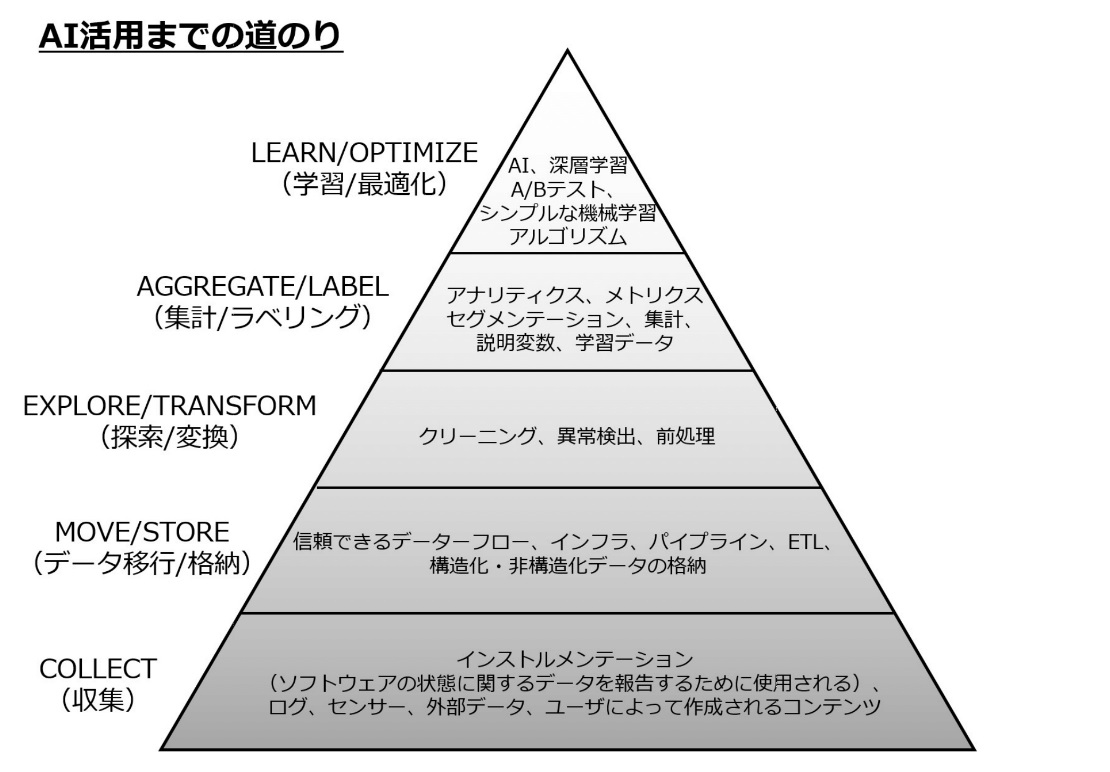
これまで説明してきた部分に相当するのは「収集」「データ移動/格納」であり、実際には上位の「探索/変換」「集計/ラベリング」「学習/最適化」という作業が必要になる。
すべての企業がAIやディープラーニングを活用した学習/最適化を目指す必要はないが、探索/変換レベルまで達していないと、その後の分析が困難になることがわかる。
質の良いデータから
昨今はAIや機械学習など華々しい言葉が目につくが、基本として大切なのは「分析対象のデータがしっかり取れているか」という点だ。
データ分析の世界には「Garbage in garbage out(ゴミを入れればゴミが出てくる)」という言葉がある。いくら高度なAIや機械学習を使ったとしても、使用するデータの品質が低ければ分析結果の精度は低くなる。最悪の場合には、分析自体が不可能なこともある。
逆に質の良いデータであれば、データ量がそれほど多くなくても、もしくはシンプルな解析モデルでも十分な結果を出せることがある。
質の良いデータとは何か。いくつか観点はあるが、わかりやすいところでは、分析に使用できる必要十分なデータがあるか、それらは十分にクレンジングされ異常データの除去や欠損値が補正されているかなどだ。
またデータ生成元の問題もある。Webの行動分析では、従来はWebログを使うことが多かった。しかし、現在のフロントエンドアプリケーションは複雑化しているため、サーバーリクエストのWebログとユーザー行動が一致しなくなってきた。そのためビーコン型計測ツールの導入など、アプリケーション側でも分析に必要なデータを出力する仕組みが必要になる。
データ探索とは
探索/変換に出てきたデータ探索は、データ分析の専門家以外にはわかりづらい概念だが、重要なことなので覚えてほしい。次図は、データ分析における全体感を表している。
データ分析で最も重要なのは「企画フェーズ」だ。現状の課題や分析の目的を明らかにし、目標を決定する。登山に例えれば、スタート地点を把握し(現状把握)、最終到着地点となる場所を決める(目標設定)。さらに、そこに至る中間ゴールの設定も必要だろう。
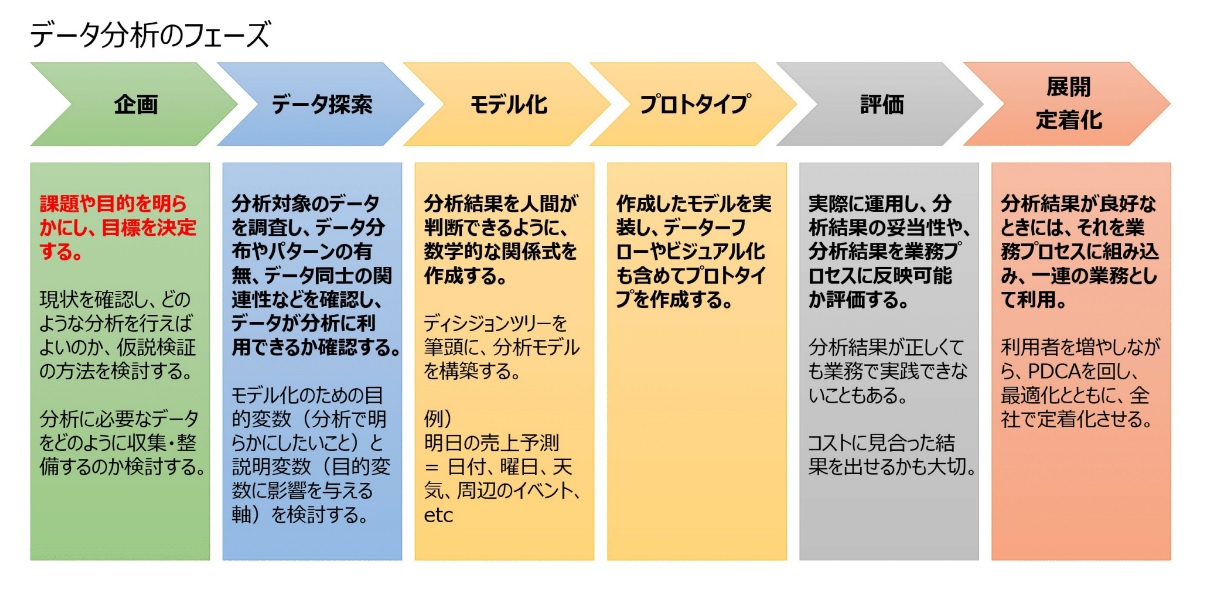
次に必要となるのが「データ探索」である。対象となるデータを調査し、データ分布やパターンの有無などを調べ、データ分析に利用できるか確認するとともに、データの加工方法(集計軸など)を決定するフェーズである。
もう少し具体的に説明しよう。分析とは、分析対象のデータを何らかの基準で分類することに他ならない。例えば、顧客ごとの販売データがあったとする。分類するには、誰が(性別、年齢、地域)、いつ(平日・休日、時間帯)、販売経路(Web、DM、店舗)など、さまざまな軸(パラメータ)で分類する必要がある。
結果に影響を与える軸(パラメータ)を説明変数という。そして効果的な説明変数を見つけ、次のモデル化につなげる必要がある。優位な差異がない説明変数は分析に使えないのだ。
これらの準備作業がデータ探索である。少なくとも現在のテクノロジーにおいて、データレイクのデータをAIに投入すれば勝手に分析してくれることはあり得ないのだ。
目的変数と説明変数は回帰分析で使用する用語だが、ほかのデータ分析手法にも転用され使われている。実際のデータ分析はもっと複雑だが、目的変数と説明変数のイメージが何となくわかっていただけるだろうか。

インサイト(洞察)とは
データ分析でよく使われる「インサイト」という用語を辞書で調べると、洞察や洞察力、見抜く力とある。そしてマーケティング用語では「消費者の行動や思惑を見抜き、消費者自身も認識していない潜在的ニーズを引き出し、購買につながるスイッチとなるようなツボ」のことを指す。
これが転じて、データ分析ではフィールドワークやデータ探索などで得られた知見から「説明変数やモデル化手法の決定」につながる気づきを得られることをインサイト(洞察)と言う。
つまり、データ探索はインサイト(洞察)を得るために重要な行程である。また、そこで重要なのはデータのビジュアル化だ。例えば、何十万行もあるExcelの数値データを見て、何かインサイトを得られるだろうか。それよりはデータを何らかの軸で集計し、グラフ化することでデータを俯瞰し、簡単に理解できるようになる。
データ分析は、企業などが取得したデータ、あるいは適切な手順を経て購入したデータをさまざまな角度から観察し価値を見出すことである。
データ分析 ≒ (ニアリーイコール)機械学習という印象もあるが、ディープラーニング(深層学習)にしろ統計的手法にしろ、データ分析にはデータに対する正しい理解や良質なデータが必要であることは言うまでもない。
筆者の知っているデータサイエンティストに聞いた話を紹介する。「自社でデータ分析をやり始めた企業が、収集したデータを機械学習ツールに投入して課題を解決しようとしたが、うまく行かず断念した。課題定義や達成目標が生煮えのまま見切り発車をしてしまった要因もあるが、解きたい課題に対して適切なデータかどうかの判断ができていない。抽象的な表現になってしまうが、"データとのコミュニケーション"が足りていない」と彼は語っていた。
データ分析では「前処理が8割」といった言葉がある。ここで言う前処理とは、データ収集から始まり、データの選別、特徴量加工のタスクである。データ選別し、特徴量をどのような形に加工するか。そもそもデータは良質なのか。この分析者の課題を満たす分析方法を「Explanatory Data Analysis(EDA:探索的データ分析)」と呼ぶ。ひと言でいうと、データ考察の手法である。
繰り返しになるが、データ分析には良質なデータが必要なのは当然として、このデータから何が得られるのか大量に仮説を立てて、仮説立証を試行する必要がある。
EDAで確認するポイントは、以下の通りだ。
- データにパターン有無を確認する
- データ同士で関係性の有無を確認する
- データ分布を確認する
- データ信ぴょう性の有無を確認する
上記の確認ポイントを、平均値や中央値といった基礎統計学的な要約だけでなく、視認性に富んだグラフィカルなグラフを作図し、データの性質や特徴をしっかりと理解することが大事である。このステップを飛ばしてしまうと、データに対する理解が足りていないため、よい分析ステップに進めない。
続いては、EDAのアプローチの考え方である。大きく分けて2種類ある。
- 仮説検証型:仮説を事前に設定しデータで検証する
- 探索型:データから傾向を考え仮説を立てる
実際のEDA作業は、この1、2を何度も往復してデータに対する知見を出しながら、機械学習ツールなどに投入する情報を選択したり、加工したりすることで、より説明力が増した「AIモデル」が作れるようになる。
データ分析基盤を整備するうえで大切なこと
最後に、データ分析基盤で利用するテクノロジーを選定するうえで大切なことを説明しよう。
DXなどの技術を利用したシステムは、既存のシステムがない、もしくはあっても現在の技術水準とは著しく異なることがある。そのため新たに構築しても、実際のニーズにマッチせず使われない可能性がある。
使われないとまで言わなくても、日々変わる状況やニーズに応えて、常に改良し最適化する努力が必要だ。サービスやテクノロジーを選択する際は、次の点に注意すると良い。
- 初期投資は少ないことが望ましい
- ランニングコストも、従量制などリーズナブルであることが望ましい
- 周辺技術は常に変化するので、追従できるように変更が容易であること
おわりに
次回は具体的なサービスとしてAzure Data Explorerを取り上げ、どのように活用できるのか説明する。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者


筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
