はじめに
前回は、データ分析の高度化ステップにおける第2ステップ「定型的な分析」と第3ステップ「非定型な分析」の違いを解説しました。
「非定型な分析」で使用される分析手法である多次元分析を可能にするためには、データウェアハウス(DWH)と呼ばれる大規模データベースの構築が必要です。また、多次元分析で行われる軸の入れ替え、スライス、ドリルダウン&ドリルアップといった操作を可能にするには、スタースキーマと呼ばれる特別なデータベース構造を持たせる必要があります。今回は、このデータウェアハウスとスタースキーマについて解説します。
データウェアハウスのアーキテクチャ
データウェアハウスとは、データ分析システムで利用可能とするデータを一元的に格納するデータベースのことです。データウェアハウスに格納されたデータは、BIツールを通じてさまざまな分析に利用されます(図1)。
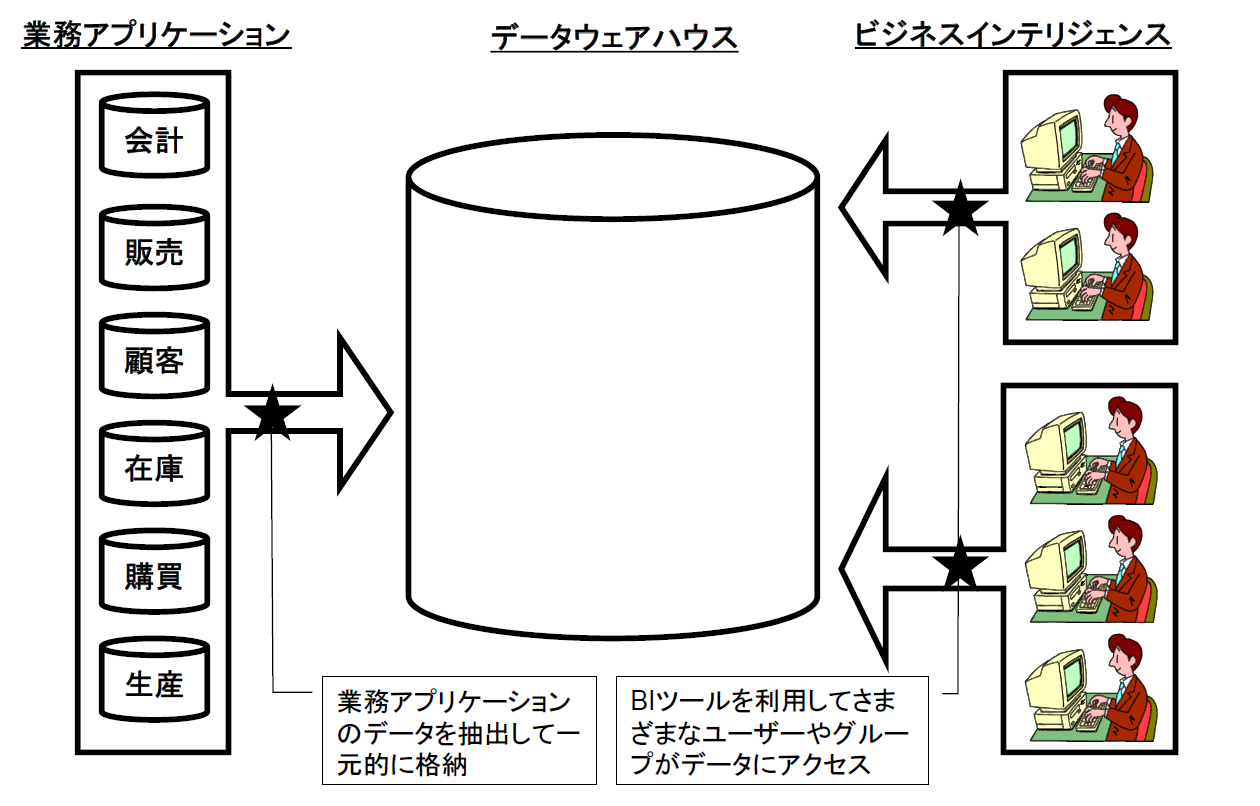
図1:データウェアハウスの位置付け【出典】ITR
しかし、データウェアハウスは、単純に1つのデータベースから構成されるとは限りません。実際には以下の3つから構成されます(図2)。
- セントラル・ウエアハウス
データウェアハウスの本体となるデータベースです。通常、リレーショナル・データベースが使用されます。 - DSA(データステージングエリア)
業務システムのデータをセントラル・ウェアハウスに格納する前に必要となるETL処理を行うための一時的な保存場所となります。通常、OSのファイルシステム上のテキスト・ファイルもしくは、リレーショナル・データベース内のテーブルとして作成されます。 - データマート
セントラル・ウェアハウスのデータの一部を、BIツールの種類やデータ分析の要件に最適な形で再構成された形態を持つ小規模なデータベースです。通常、リレーショナル・データベースが使用されます。
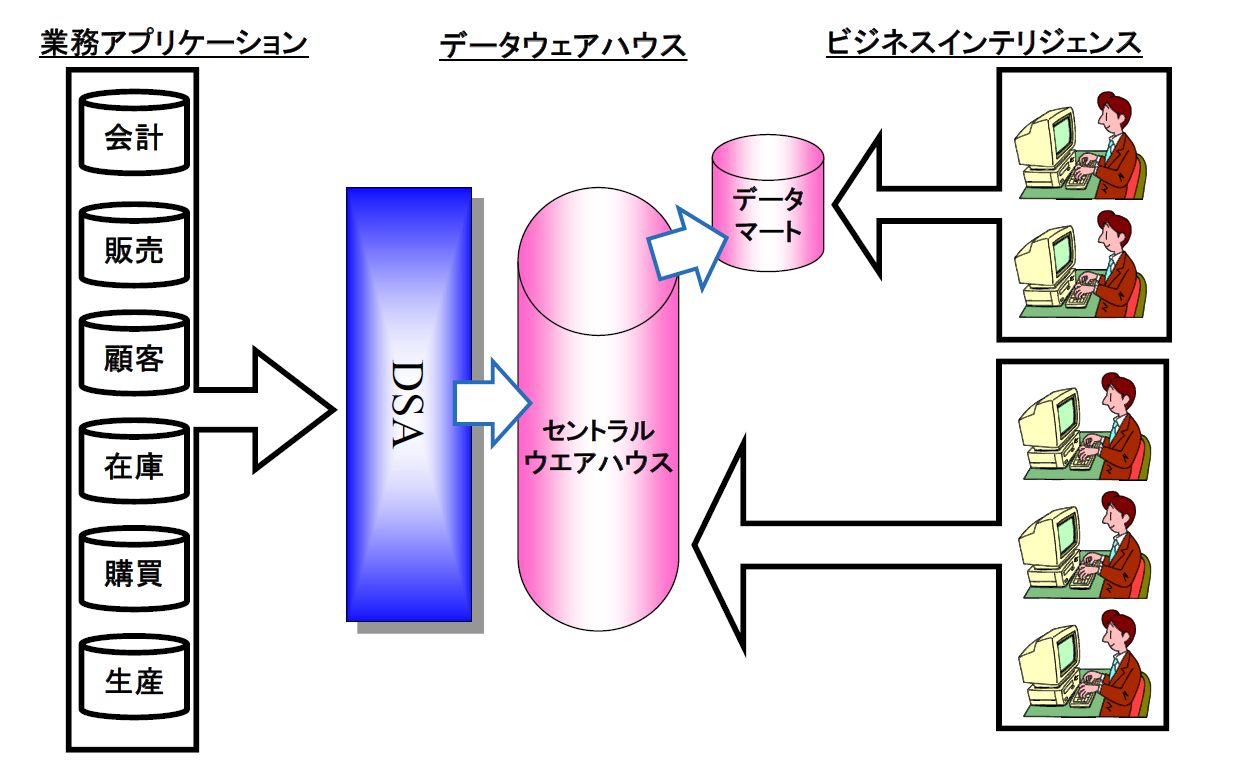
図2:データウェアハウスの構成要素【出典】ITR
DSAとETL処理
DSAとは、業務システムから抽出したデータをセントラル・ウェアハウスにロードするまでの間、一時的にデータを置いておくための領域のことです。物理的には、OSのファイルシステム上のテキスト・ファイル、もしくはリレーショナル・データベース内のテーブルとして作成されます。DSAを作成するのは、ここで業務システムのデータを分析用のデータとして適切な形に変換する必要があるためです。
DSAにおける処理は、①抽出、②一次クリーニング、③変換、④ロードの4段階に分かれます。これらの処理を総称して、抽出(Extract)、変換(Transform)、ロード(Load)の頭文字をとってETL処理と呼びます(図3)。
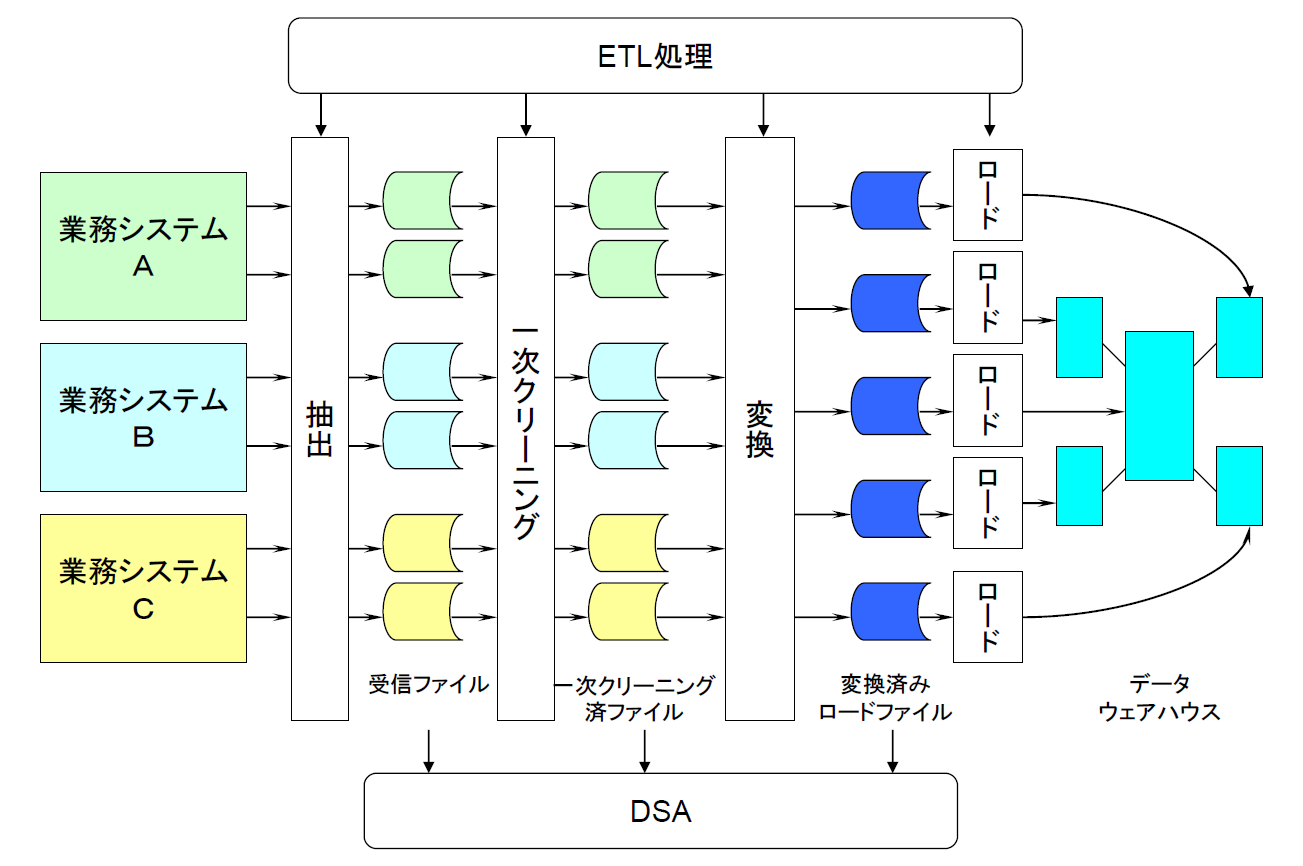
図3:DSAの構成とETL処理フロー【出典】ITR
それでは、ETL処理の4つの段階に沿ってDSAを説明していきます。
①抽出処理
業務システムからデータウェアハウスで必要とされるデータを抽出し、DSAに受信ファイルとして格納する処理です。業務システムの種類や状況により、やり方が異なります。
業務システムが汎用機の場合や他システムから直接アクセスすることが難しい場合は、業務システム側でプログラムを開発してデータ抽出処理を行い、それをデータウェアハウス側にファイルを転送することになります。業務システムのデータがリレーショナル・データベースに格納されている場合は、このデータベースにデータウェアハウス側からクライアントとしてアクセスしてSQLでデータを直接抽出できます。また、ERPパッケージの場合には専用のインターフェースが用意されているものもあります。
②一次クリーニング処理
次の変換処理の準備として、抽出した業務システムのデータ形式を変換するなどの前処理を行います。データ形式としては、主に文字コードを変換します。業務系で使用されている文字コードとデータウェアハウスで使用する文字コードが異なる場合、この段階で処理します。差分更新の場合は、抽出されたデータが意図した期間内のデータであるかもここで確認します。
③変換処理
一次クリーニングされた抽出データを変換し、データウェアハウスを構成する各テーブルにロード可能なファイルを作成します。ETL処理の中で最も重要で複雑な処理フェーズになります。
ここで行う処理は、主に以下の3つです。
- クレンジング
- 統合化
- 集計
クレンジングは、データウェアハウスで決められた仕様に沿って、データを適切な形式に変換したり、排除したりします。例えば、日付型を文字型に変換したり、Null値を空白や0に置き換えたりといった処理をします。
セントラル・ウェアハウスに格納される各テーブルを構成する情報(カラム)は、多くの場合、複数のテーブルもしくは複数の業務システムに分かれて存在しています。このような複数のソースデータから1つのセントラル・ウェアハウスのテーブルを作成するのに必要な処理が統合化です。通常、統合化は1つのテーブルに対して一連の連続した処理、つまり1つのストリームで処理します。図4はストリームの例です。
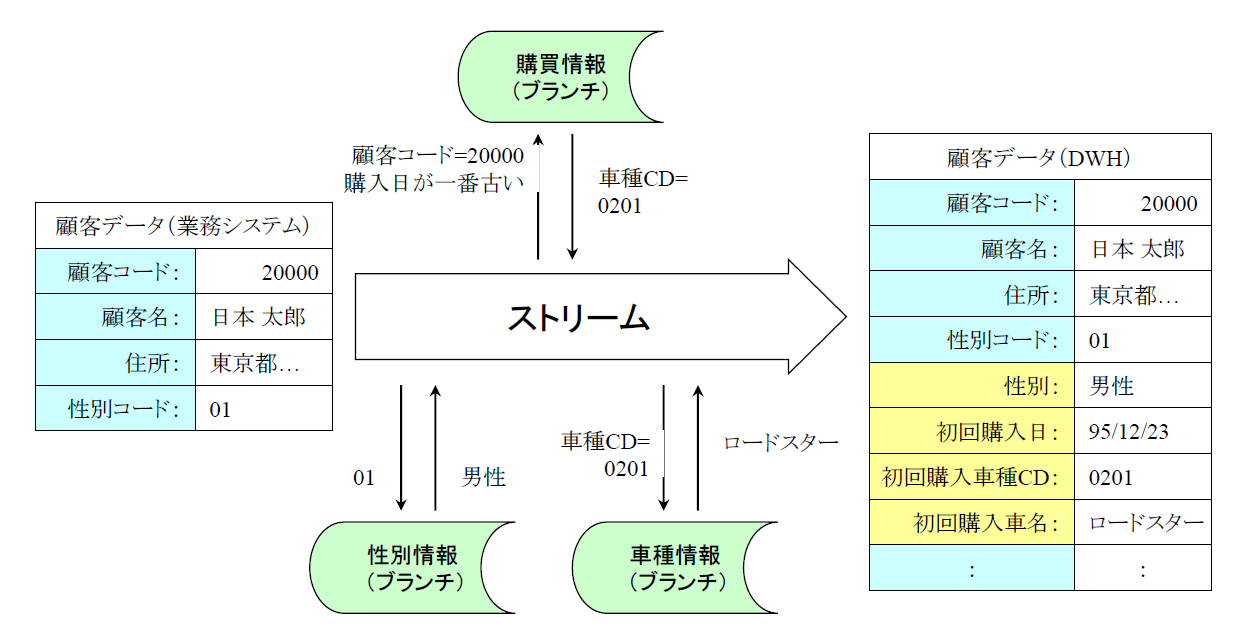
図4:ETL処理での統合化ストリームの例【出典】ITR
この例では、業務システムの顧客情報をストリームに従って他の3つの情報と統合化し、セントラル・ウェアハウスの顧客情報に変換しています。
集計処理は、セントラル・ウェアハウスに格納するデータの粒度(数値データの集計単位)に従って行われます。例として時間の単位で考えると、セントラル・ウェアハウスの最も細かい単位は日が普通です。つまり、業務システムから抽出したデータの中の何時何分何秒という情報は必要ないということです。この場合、年月日を含めて他の属性データが全て同一のレコードは数値データを合計(平均などを計算する場合もある)して、1つのレコードとして集約してしまいます。この処理により、セントラル・ウェアハウスのデータベースの大きさを最適化できます。
④ロード処理
セントラル・ウェアハウスへのデータのロードはデータ量が大量となるため、SQLで1レコードずつインサートするということはありません。通常は使用するリレーショナル・データベース製品の機能に応じた高速ローディング処理を行います。
スタースキーマ
多次元分析で行われる軸の入れ替え、スライス、ドリルダウン&ドリルアップといった操作を可能にするには、スタースキーマと呼ばれる特別なデータベース構造を持たせる必要があります。そのため、データウェアハウス(セントラル・ウェアハウス及びデータマート)の中でBIツールから直接アクセスされる部分はスタースキーマで作成されます。
スタースキーマは、中心のファクト・テーブルと呼ばれる索引と数値カラムで構成されるテーブルの周りをディメンション・テーブルと呼ばれる属性データで構成される複数のテーブルが星型に取り囲んだ形で表現されるため、このような名称で呼ばれています(図5)。
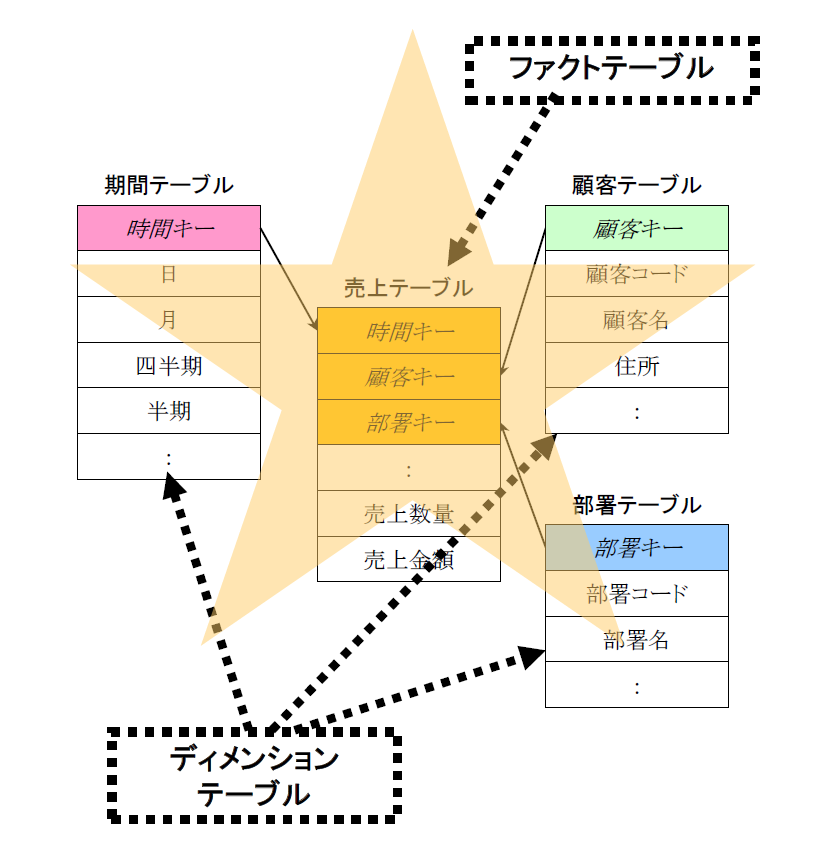
図5:スタースキーマ【出典】ITR
スタースキーマの利点としては、主に以下のようなものがあります。
- 顧客名、部署名といった属性データによる検索は、ディメンション・テーブルのみの全件走査で処理できるため検索スピードが速い。
- ファクト・テーブルと複数のディメンション・テーブルとの間でデータ重複を最小限にできるため、データ量が小さくなる。
- データウェアハウス内固有のキーで結合しているため、業務システムで変更される属性データへの対応が容易である。
このうち、3番目の項目が最も重要なポイントです。
一般的に、業務システムでは今が良ければそれで良いという思想でデータを更新します。例えば、読者の銀行預金の残高が100万円だとして、今日10万円を引き出したとしましょう。業務システムでは、結果としての残高90万だけが重要であり、昨日までの残高100万円や今日引き出した金額、今日の日付、引き出した支店といったデータは無駄なデータとして扱われます。
一方、データウェアハウスでは、今だけでなく、過去の履歴のデータや場合によっては将来予測される(計画されている)データまでもが重要になります。
業務システムは、このような思想で開発されているため、組織や顧客といった検索キーになりうるコードを平気で上書き更新してしまいます。ですから、データウェアハウスで業務システムから得られるコードだけをキーとして使用すると、時系列なデータの集計が正しく処理されなくなってしまいます。
これを防ぐために、データウェアハウスではサロゲートキーとナビゲーション・ブリッジ・テーブル(NBT)という2つのテクニックを使用します。
サロゲートとは「代わりのもの」「代理人」という意味のことばで、データウェアハウス内部で使用する専用キーのことをサロゲートキーと呼びます。スタースキーマのディメンション・テーブルとファクト・テーブルとの結合にはサロゲートキーを使用します。図5の例では、顧客コードとは別に顧客キーが、部署コードとは別に部署キーが、それぞれサロゲートキーとして定義されています。一般にサロゲートキーの値には、意味のない通番を使用します。
データウェアハウスでサロゲートキーを使用するのは、業務系システムで勝手に変更されてしまうディメンションのデータを時系列に正しく復元するのが主な目的です。
わかりやすい例として、組織ディメンション・テーブルで考えてみましょう。2020年の3月までは組織コード5600番は営業部を意味していました。ところが、2020年の4月1日に組織変更があり、営業部は営業1部と営業2部に分割されました。ここで、業務システムの組織コードとして5600番は営業1部が引き継ぎ、営業2部には新たに5601番が振られたとします。データウェアハウスで単純に業務システムの組織コードをディメンション・テーブルとファクト・テーブルの結合キーとして使用していたとすると、2003年を通しての売上金額を集計した場合、営業部と営業1部の値の区別がつかなくなってしまいます。
そこで、データウェアハウスではサロゲートキーとして営業部は0001番、営業1部は0002番、営業2部は0003番というように通番を振ります。これにより、集計した結果がきちんと営業部、営業1部、営業2部に分かれて出てくるようになります(図6)。
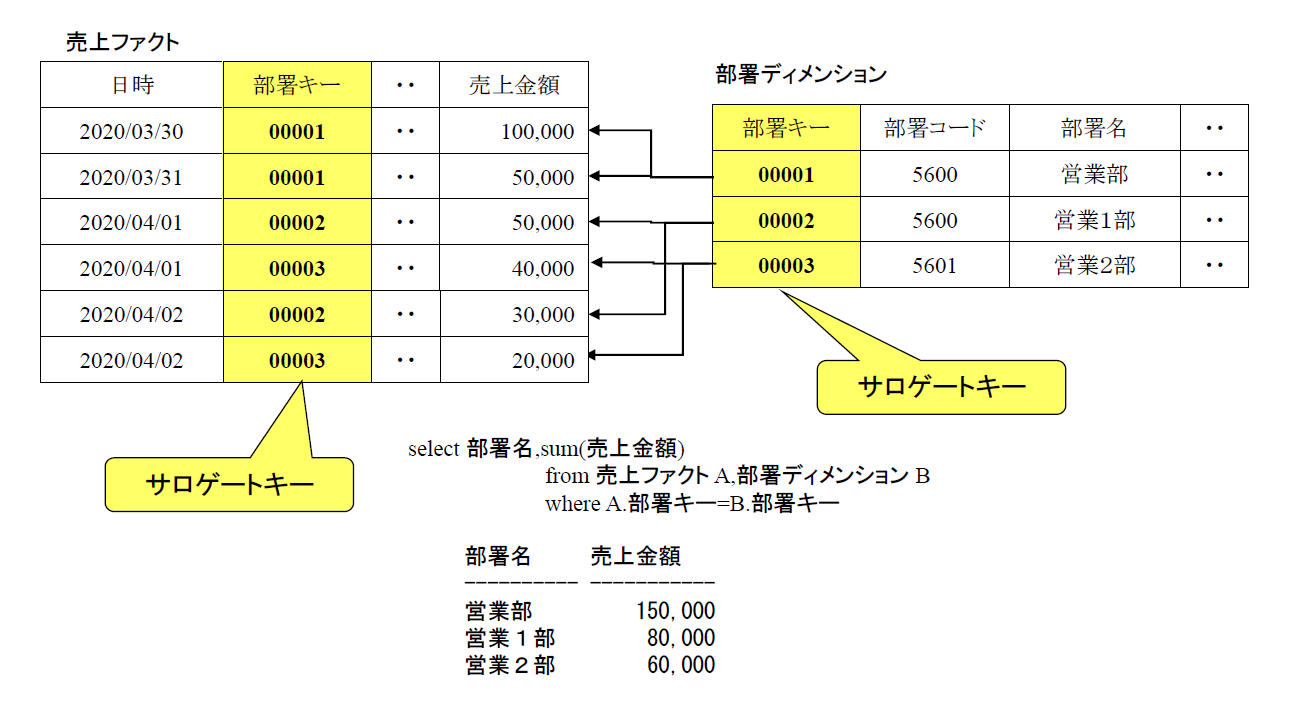
図6:サロゲートキーによる時系列の復元【出典】ITR
さて、業務システムで変更されてしまったディメンションのデータをサロゲートキーにより正しく区別(復元)できることはわかりました。しかし、区別できるだけではデータウェアの仕様として充分ではないケースがあります。それは、サロゲートキーの例で言うと営業部の売上金額を引き継いだ部署が営業2部であるとして、営業2部の売上金額に営業部の売上金額を合計したものを2003年の通年データとして集計したいというケースです。
このような処理を時系列での遡及と呼びます。これを実現するためのテクニックがナビゲーション・ブリッジ・テーブル(NBT)です。図7はナビゲーション・ブリッジ・テーブルの使用例です。
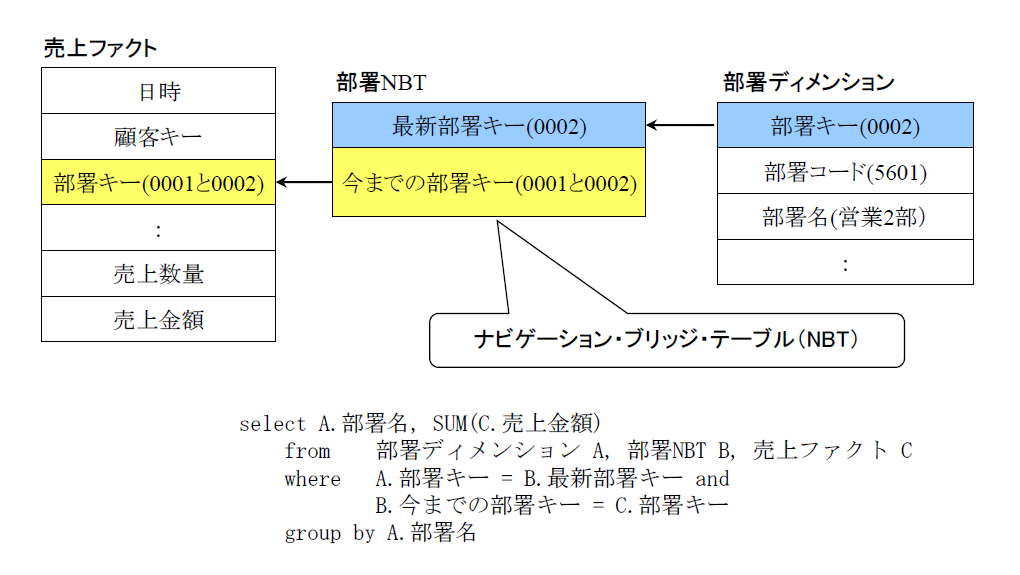
図7:ナビゲーション・ブリッジ・テーブル(NBT)による時系列の遡及【出典】ITR
ナビゲーション・ブリッジ・テーブルには最新のキーと過去のキーの双方が格納されています。これをディメンション・テーブルとファクト・テーブルの間にブリッジとして挟むことにより、時系列の遡及を実現できます。
サロゲートキーとナビゲーション・ブリッジ・テーブルは、データウェアハウスで使われる標準的な方法ですが、物理的な実装は難易度が高く、常に使えるとは限りません。重要なことは、時系列の復元と遡及を実現することであり、実際の実現方法はユーザー要件や復元、遡及を行うディメンションの性質に応じた現実的なものを採用すれば良いでしょう。
例えば、ECサイトの売上分析におけるユーザー要件として、顧客の居住エリア別の売上集計が必要とされる場合、時系列の復元と遡及を実現し、現在の居住エリアと商品購入時の居住エリアの双方で集計を可能にしなければなりません。このような場合は、顧客ディメンション・テーブルには現在の居住エリアのみを格納しておき、商品購入時の居住エリアはETL処理の統合化ストリームの過程でファクト・テーブルの列として格納するという比較的簡単な方法で実現できます。
おわりに
今回は、「非定型な分析」で使用される分析手法である多次元分析を可能にするための、データウェアハウス(DWH)とスタースキーマについて解説しました。
次回は、「定型的な分析」と「非定型な分析」で使用される分析ツールであるレポーティングツールとセルフサービスBIツールについて解説します。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
