2 台で非同期 HA を構築
2 台で非同期 HA を構築
まず最初に、2 台のホストを設定し、非同期レプリケーションを用いた構成をしてみましょう。
|
|
| 図2:非同期 2 台の構成例(クリックで拡大) |
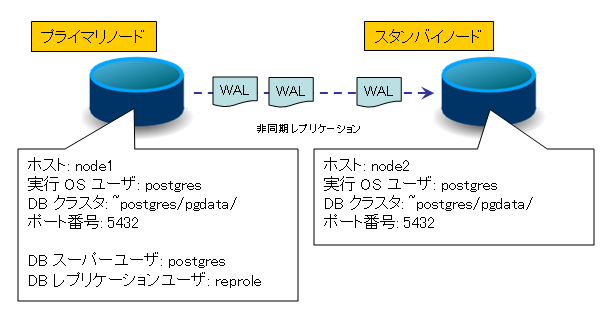
構成は上記のようになります。今回は説明を分かりやすくするためにホスト名で記述していますが、実環境では、DNS が不調になることも考えられますので、IP アドレスで指定した方が良いでしょう。
まずは動作するところまで一気に構築をしてから、個々の設定については後で説明して行こうと思います。最初に、各ホストで共通の設定を行います。
/etc/keepalived/keepalived.conf を以下のように設定します。
vrrp_instance pgsql {
garp_master_delay 5
virtual_router_id 200
advert_int 1
state BACKUP
priority 100
nopreempt
interface eth0
authentication {
auth_type PASS
auth_pass foobar
}
virtual_ipaddress {
192.168.12.23/24 dev eth0
}
notify "/var/lib/pgsql/pgdata/notify"
}
前回までの環境を流用するならば、使用するポートがかぶってしまうので、前回動かしていたインスタンスを止めておきます。
[root@node1 ~]# su - postgres
-bash-4.1$ export PATH=/usr/pgsql-9.1/bin/:$PATH
-bash-4.1$ pg_ctl -D ~/pgdata-prim/ status && pg_ctl -D ~/pgdata-prim/ stop -m fast
pg_ctl: サーバが動作していません
-bash-4.1$ pg_ctl -D ~/pgdata-stby/ status && pg_ctl -D ~/pgdata-stby/ stop -m fast
pg_ctl: サーバが動作していません
-bash-4.1$
他ホストから RSH でログインするための ~/.rhost と、psql クライアントで VIP に対してデータベース接続をするための ~/.pgpass を設定します。
-bash-4.1$ echo node1 postgres > ~/.rhosts
-bash-4.1$ echo node2 postgres >> ~/.rhosts
-bash-4.1$ echo spare postgres >> ~/.rhosts
-bash-4.1$ chmod 0600 ~/.rhosts
-bash-4.1$ echo vip:5432:*:reprole:reppass > ~/.pgpass
-bash-4.1$ echo vip:5432:postgres:postgres:postgres >> ~/.pgpass
-bash-4.1$ chmod 0600 ~/.pgpass
-bash-4.1$
以上が各ホストに共通の設定となり、ここから先がプライマリの設定となります。データディレクトリ下のファイルは pg_basebackup でレプリケーション・ベースをコピーする際に同時にコピーされますので、可能な限りプライマリ上で前もって設定をし、後でそれらをスタンバイ側へコピーするようにします。
プライマリ上にデータ領域を作成して仮起動し、レプリケーション用のユーザを作成します。
-bash-4.1$ initdb -D ~/pgdata/ --encoding=UTF-8 --no-locale --pwprompt --auth=md5
(中略)
新しいスーパーユーザのパスワードを入力してください: postgres
再入力してください: postgres
(中略)
成功しました。以下を使用してデータベースサーバを起動することができます。
postmaster -D /var/lib/pgsql/pgdata
または
pg_ctl -D /var/lib/pgsql/pgdata -l logfile start
-bash-4.1$ pg_ctl -D ~/pgdata/ start
サーバは起動中です。
-bash-4.1$ psql -c "CREATE ROLE reprole REPLICATION LOGIN PASSWORD 'reppass'"
CREATE ROLE
-bash-4.1$
~postgres/pgdata/postgresql.conf を設定します。内容は前回と同じですので、変更箇所のみ記載します。
## '*' を指定することで PostgreSQL はアドレス 0.0.0.0 に対して listen を
## します。すると、後で付与された VIP 上でも listen することができます。
listen_addresses = '*'
port = 5432
wal_level = hot_standby
max_wal_senders = 10
wal_keep_segments = 1000
synchronous_standby_names = ''
hot_standby = on
~postgres/pgdata/pg_hba.conf に以下を追加します。今回はネットワークごしでのアクセスが必要ですので、ネットワークアドレス (ここでは 192.168.0.0/16) を指定します。
host replication reprole 192.168.0.0/16 md5
host postgres reprole 192.168.0.0/16 md5
host postgres postgres 192.168.0.0/16 md5
スタンバイに降格した際に用いる recovery.conf のひな形として、~postgres/pgdata/recovery.conf.in を作成しておきます。実際には、"application_name" の値をホスト名 ("node1" や "node2" といった名前) に置換して使用されます。
standby_mode = 'on'
primary_conninfo = 'host=vip user=reprole password=reppass application_name=@hostname@'
recovery_target_timeline = 'latest'
restore_command = 'rcp vip:/var/lib/pgsql/pgdata/pg_xlog/%f "%p" 2> /dev/null'
次に、Keepalived がマスターやバックアップに遷移する際に呼ばれるスクリプトファイルである ~postgres/pgdata/notify を設置します。
#!/bin/sh
vhost=vip
dbuser=postgres
pgdata=/var/lib/pgsql/pgdata/
reprole=reprole
repdb=postgres
export PATH=$PATH:/usr/pgsql-9.1/bin/
# --------------------------------------------------------------------
# root で実行されていたら、DB ユーザに切り替えて再実行します
if test $UID = 0
then
abspath=$(cd $(dirname $0); pwd)/$(basename $0)
exec su - $dbuser $abspath "$@"
false
fi
type=$1
name=$2
stat=$3
prio=$4
case $stat in
MASTER)
# PostgreSQL が起動していなければ起動します
pg_ctl -D $pgdata status || pg_ctl -D $pgdata start
# スタンバイであれば、プライマリに昇格させます
if test -e $pgdata/recovery.conf
then
pg_ctl -D $pgdata promote
while ! psql -h $vhost -U $reprole $repdb -c "SELECT pg_switch_xlog()"
do
sleep 1
done
psql -h $vhost -U $reprole $repdb -c "CHECKPOINT"
fi
;;
BACKUP)
# PostgreSQL を停止し、プライマリであればスタンバイに降格させます
if ! test -e $pgdata/recovery.conf && \
psql -h $vhost -U $reprole $repdb -l
then
pg_ctl -D $pgdata status && pg_ctl -D $pgdata -m immediate stop
sed -e "s/@hostname@/$(hostname)/" < $pgdata/recovery.conf.in \
> $pgdata/recovery.conf
fi
# 起動していなければ、起動します
pg_ctl -D $pgdata status || pg_ctl -D $pgdata start
;;
esac
以上で設定は終わりですので、仮稼働させていた PostgreSQL を停止させます。
-bash-4.1$ chmod 755 ~/pgdata/notify
-bash-4.1$ pg_ctl -D ~/pgdata/ stop -m fast
root ユーザへ戻り、Keepalived を起動させます。Keepalived はまずバックアップで起動しますが、まだネットワーク上に自分自身しか Keepalived ホストが存在しないので、すぐにマスターに遷移します。そして上記の "notify" のスクリプトを経由して、PostgreSQL のインスタンスをプライマリとして起動させます。
-bash-4.1$ exit
[root@node1 ~]# service keepalived start
keepalived を起動中: [ OK ]
[root@node1 ~]# chkconfig keepalived on
以上が、プライマリの構築手順でした。次に、スタンバイの設定を行います。必要なファイル群はベースのコピーとしてプライマリから取得できるので、こちらの手順は簡単です。なお、フェイルオーバーの際に WAL の取りこぼしが発生して旧プライマリではレプリケーションが継続できなくなった場合には、スタンバイの再構築が必要です。これは、その際の手順でもあります。
[root@node2 ~]# su - postgres
-bash-4.1$ export PATH=/usr/pgsql-9.1/bin/:$PATH
-bash-4.1$ rm -fr ~/pgdata/
-bash-4.1$ pg_basebackup -x -h vip -U reprole -D ~/pgdata/
root ユーザへ戻り、keepalived を起動させます。設定が正しくなされていれば、"notify" のスクリプトを経由して、PostgreSQL のインスタンスが、こちらはスタンバイとして起動されるはずです。
-bash-4.1$ exit
[root@node2 ~]# service keepalived start
keepalived を起動中: [ OK ]
[root@node2 ~]# chkconfig keepalived on
以上です。下記のように、プライマリ上でレプリケーションの状態を確認し、プライマリの現在の WAL 位置とスタンバイの flush_location の位置が一致しているようであれば、試しにプライマリのホストの電源を、終了処理を経ずに落としてみましょう。
-bash-4.1$ psql -h vip -x -c "SELECT * FROM pg_current_xlog_location()"
-[ RECORD 1 ]------------+----------
pg_current_xlog_location | 0/40000B0 ← これと
-bash-4.1$ psql -h vip -x -c "SELECT * FROM pg_stat_replication"
-[ RECORD 1 ]----+------------------------------
procpid | 8432
usesysid | 16384
usename | reprole
application_name | node2
client_addr | 192.168.12.25
client_hostname |
client_port | 33320
backend_start | 2011-XX-XX 18:29:08.142613+09
state | streaming
sent_location | 0/40000B0
write_location | 0/40000B0
flush_location | 0/40000B0 ← これが一致
replay_location | 0/40000B0
sync_priority | 0
sync_state | async
-bash-4.1$
その結果、Keepalived によって node2 がマスター (プライマリ) に昇格し、引き続き "vip" に対してデータベースへのアクセスができるはずです。その後 node1 を起動すれば、今度は node1 がバックアップ (スタンバイ) としてレプリケーションを受けることになります。
なお、HA クラスタ全体を停止させる際には、スタンバイ→プライマリの順に停止してください。
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
