構成について
構成について
それでは、改めて各ファイルを見てみたいと思います。
今回、Keepalived の設定ファイルである keepalived.conf の重要な点としておさえておいて欲しいパラメータは、"virtual_ipaddress", "state", "nopreempt", "priority", "notify" の 5 点です。
- virtual_ipaddress は、見ての通り仮想 IP アドレスを意味します。マスターホストだけがこのアドレスを保持し、これを通じて実際のサービス (今回はデータベース) を提供することになります。
- 各 Keepalived サービスは、起動直後は、"state" に指定した状態で起動します。全てのホストで "BACKUP" を指定していますので、最初は一旦はバックアップとして起動し、その後で、他のホストがまだ見つからないようであれば、改めてマスターに昇格する、という動きをします。
- "nopreempt" を指定すると、たとえ現行のマスターよりもプライオリティ ("priority" パラメータで指定) が高いホストが現れたとしても、自動的に高プライオリティのホストを再度マスターに切り替えることはしません。プライオリティは、複数の昇格候補のバックアップがある場合に、どのノードを新マスターにするかを決めるためだけに使用されます。これは、次項の同期レプリケーションの設定において意味を持ちます。
- "notify" で指定したスクリプトに対して、Keepalived から通知が行われます。ホストがマスターになった時には "MASTER" の文字列が、バックアップになった場合には "BACKUP" の文字列が第 3 引数に渡されて、このコマンドが実行されます。keepalived を止める時に呼ばれるハンドラといったようなものは、特にありません。
今回の非同期レプリケーションにおける各ホストの設定は、IP アドレス、ホスト名を除いて全く対称になっています。そのため、先に Keepalived のサービスが開始された方が Keepalived のマスター (PostgreSQL のプライマリ) となり、後から起動した方がバックアップ (PostgreSQL のスタンバイ) となります。
次に、notify のスクリプトについて見てみましょう。
基本的には、マスターへの遷移の際には昇格を、バックアップへの遷移の際には降格を行うのですが、まだ他のホストを起動していない状態で単一で起動した際 (vip へのアクセスができない場合) には、バックアップへの遷移を指示されてもプライマリとして起動するようにしています。
昇格の際に "pg_switch_xlog()" を行っているのは、もしも、次の WAL セグメントへスイッチする前に recovery_target_timeline='latest' で、以前プライマリだったノードへ再度フェイルバックしてしまうと、前回のタイムラインの WAL レコードがまだ現行セグメント内に残ってしまい、リカバリに失敗するためです。これを防ぐために、昇格直後には pg_switch_xlog() を実行し、セグメントファイルを明示的に切り替えるようにしています。
また、あわせて CHECKPOINT も実行しています。リカバリの際に、*.history ファイルを見てタイムラインをさかのぼるのは 1 段階までです。そのため、短時間の内にフェイルバックを行うと、最終チェックポイント位置がタイムラインを 2 段階以上さかのぼらないと到達できない WAL セグメント内に含まれてしまうことがあります。この場合にもリカバリは失敗してしまいますので、昇格直後には CHECKPOINT を行うようにしています。
3 台で同期 HA を構築
次に、3 台 (node1, node2, spare を利用) での同期モードによる HA の構成を行います。なぜ 3 台も必要かと言うと、第 2 回で見た通り、同期レプリケーション中のスタンバイに障害が起きてプライマリ 1 台だけが残されると、プライマリはスタンバイからの書き込み済みの通知を待ち続けてしまい、全体の処理が止まってしまうためです。
|
|
| 図3:同期 3 台の構成例(クリックで拡大) |

spare のホストを、前項の非同期レプリケーションのスタンバイ側ホストを作る手順と同様に構成してください。
ただし、spare の /etc/keepalived/keepalived.conf のプライオリティだけは下げておきます。
priority 100
↓
priority 10
そして、全ノードの ~postgres/pgdata/postgresql.conf の同期レプリケーションの設定を、以下のように変更します。
synchronous_standby_names = ''
↓
synchronous_standby_names = 'node1,node2,spare'
以上です。ね、簡単でしょう? node1, node2, spare の各 Keepalived のプライオリティを 100, 100, 10 とし、そして "nopreempt" を指定したことで、障害時/復旧時の昇格/降格のパターンが以下のようになります。
|
|
| 図4:同期 3 台での役割の遷移(クリックで拡大) |
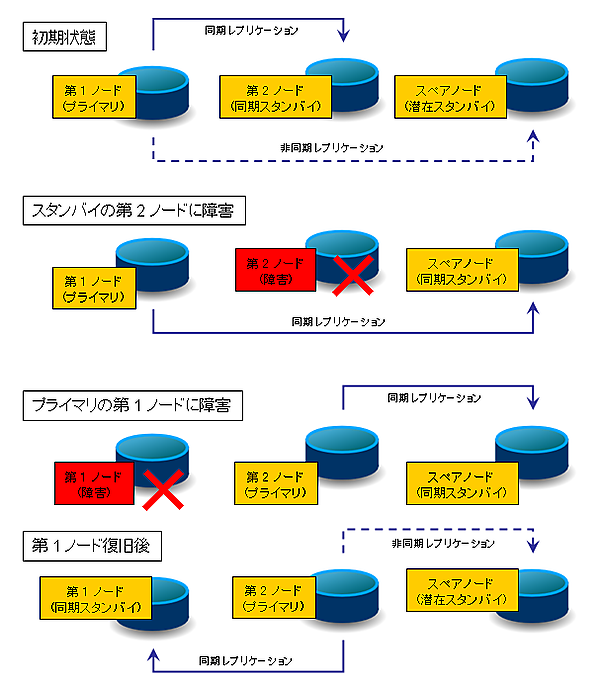
第 1 ノード (node1), 第 2 ノード (node2), スペアノード (spare) の順に起動すると、図の「初期状態」のように、第 1 ノードがプライマリとして起動します。"synchronous_standby_names" に node1, node2, spare の順に記述しましたので、node2 の方が spare よりも同期レプリケーションノードとしてのプライオリティが高くなっています。そのため、初期状態では node2 が同期ノードとなります。spare は "potential" 同期ノードとなり、当座は非同期でのレプリケーションとなります。
ここで第 2 ノードに障害が発生したとします。すると、プライマリ (第 1 ノード) としては同期ノードからのアクセスが無くなったため、プライオリティのリスト上で次の優先度を持つ spare ノードに対して同期レプリケーションを開始します。このようにして、ノードが 1 つだけになって書き込みがブロックしてしまうことを防ぎます。
プライマリ自身に障害が起きた場合には、Keepalived が、残るバックアップホストの中で最も Keepalived プライオリティの高いホスト (ここでは node2 の "100" が spare の "10" より大きい) を昇格させます。先に見たように同期レプリケーションのプライオリティ順は node1, node2, spare ですが、node1 は障害を起こしていて動いていませんので、spare が同期ノードとして稼働します。
その後で第 1 ノードを復旧させて、再度レプリケーションを開始させるとします。Keepalived の設定に "nopreempt" を指定しているために、node1 の昇格は行われず、引き続き node2 がプライマリとしてサービスを続けます。一方、PostgreSQL としての node1 の同期レプリケーションの優先度は spare よりも高いので、spare にかわり、node1 が新しく同期レプリケーションのスタンバイノードとなり、spare は再び潜在スタンバイとして非同期レプリケーションへ移行します。
停止の際には、非同期の例と同じように、スタンバイ→プライマリの順に停止してください。
最後に
PostgreSQL 9.* において、データベース自身の機能を用いて、遅延の小さい、あるいは同期でのレプリケーションを構成することができるようになりました。これによって、従来では rsync や DRBD などを利用する必要があり、どうしても柔軟性に欠き、取り扱いの面倒だった複製の作成が、非常に容易に行えるようになったと思います。ぜひ今回の記事を参考に、実際にご自身で構成をしてみていただきたいと思います。
さらに発展的な内容として、サービスの死活監視の追加 (Keepalived でいうと "MISC_CHECK" の設定、コマンドで言うと "PGCONNECT_TIMEOUT" 環境変数の指定) や、他の HA ソフトウェアを用いたストリーミング・レプリケーションの利用などにも挑戦していただけると、さらに応用範囲が広がるのではないかと思います。
参考リンク
- PostgreSQL 9.1 ストリーミングレプリケーション対応 リソースエージェント - GitHub
- DSAS開発者の部屋:知っていても損はしないkeepalivedの話 ~ MISC_CHECKの注意点
<サイト最終アクセス:2011.10>
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
